
안녕하세요. 커머스전시 스쿼드에서 사용자에게 노출되는 전시 시스템을 개발하고 있는 우투리입니다.
저희 스쿼드는 고객이 올리브영 온라인몰에 진입했을 때 가장 먼저 마주하는 홈 화면을 비롯하여, 상품을 탐색하고 구매를 결정하기까지의 전 과정을 담당하고 있습니다. 고객이 빠르게 원하는 상품을 찾고, 신뢰할 수 있는 정보를 바탕으로 구매를 결정할 수 있도록 시스템을 지속적으로 개선하고 있습니다.
이 글에서는 10년 이상 운영해 온 배치 기반 혜택 데이터 파이프라인을 Kafka 기반 준실시간 구조로 전환한 과정을 공유합니다.
1. 들어가며
올리브영 오프라인 매장에서 고객이 매대를 둘러보며 상품을 고르듯, 온라인몰에서도 고객은 홈, 카테고리, 기획전 같은 화면을 탐색하며 구매를 결정합니다.
이처럼 고객과 상품이 만나는 모든 화면 영역을 저희는 '전시 영역' 이라고 부릅니다. 그중에서도 고객의 구매 결정이 실제로 이루어지는 핵심 단위가 바로 '상품카드'입니다. 이러한 전시 영역의 상품카드는 다음과 같이 크게 4가지 요소로 구성됩니다.

자주 변경되는 가격, 다양한 프로모션 플래그, 리뷰 개수나 평점과 같은 집계 데이터까지 한 번에 제공되는 영역입니다.
이 중에서도 고객의 구매 결정을 직접적으로 자극하는 요소는 위 이미지의 3️⃣번과 같은 혜택/프로모션 플래그입니다. "쿠폰 적용 가능", "선착순 증정" 같은 문구를 이 글에서는 '혜택 플래그'로 통칭합니다.
전시 시스템은 상품·쿠폰·증정·프로모션 등 각기 다른 도메인의 데이터를 하나의 화면에 통합해야 하는 구조입니다. 이 통합 과정이 10년 이상 누적된 프로시저에 의존하면서, 최대 45분까지 지연되는 구조로 운영해 왔습니다.
그 결과, 고객은 잘못된 정보를 기반으로 구매를 결정하거나 기대했던 혜택을 받지 못하는 경험을 하게 되었습니다. "선착순 추가 증정"과 같은 혜택 플래그를 보고 기대에 찬 마음으로 상품 상세 페이지에 들어갔지만, 이미 증정 행사가 마감된 경우를 예로 들 수 있습니다.
커머스 도메인에서 데이터 지연은 단순한 성능 문제가 아니라, 사용자 경험과 구매 행동에 직접적인 영향을 주는 문제입니다. 이에 저희는 해당 영역을 준실시간 기반으로 전환하는 작업을 진행하게 되었습니다.
올리브영에서는 이미 품절 시스템, 캠페인 시스템 등에서 CDC 기반의 이벤트 드리븐 아키텍처 전환을 진행해 왔습니다. 이번 글은 그 흐름을 이어, 사용자에게 가장 직접적으로 노출되는 영역에 적용한 사례입니다. 기존 사례들이 단일 도메인의 데이터 전환에 집중했다면, 이번에는 상품·쿠폰·증정·프로모션 등 다수 도메인의 데이터를 한 화면에 통합해야 한다는 점이 핵심 과제였습니다.
- 올리브영 테크블로그, Kafka Streams 기반 EDA 구축 사례: 올리브영 품절 시스템 현대화 프로젝트
- 올리브영 테크블로그, 올리브영의 실시간 캠페인 타겟팅을 위한 CDC 전환기
2. 문제 정의
이번 글에서 다루는 핵심 과제는 여러 도메인 데이터를 하나의 전시 화면으로 통합하는 일입니다. 이 과정에서 저희가 마주한 문제는 크게 세 가지였습니다.
2-1. 프로시저 속에 숨겨진 복잡성
올리브영은 상품·쿠폰·증정·프로모션과 같이 각 도메인의 역할(R&R)이 세분화되어 있고, 각 팀이 자신의 도메인 데이터를 독립적으로 관리하는 구조입니다. 전시 시스템은 이러한 여러 도메인의 데이터를 조합해 사용자에게 보여주는 역할을 하고 있지만, 기존 구조에서는 각 도메인의 데이터를 직접 조회하는 방식으로 구성되어 있었습니다.
문제는 이 과정에서 각 도메인의 실제 비즈니스 로직이 10년 이상 누적된 단일 프로시저 안에 불투명하게 결합해 있었다는 점입니다. 어느 도메인의 정책이 어떻게 반영되어 있는지 추적하기 어려웠고, 하나의 조건을 바꾸면 전체 로직에 영향을 주는 강결합 구조로 인해 단순한 정책 변경조차 운영 리스크로 이어졌습니다. 기본적으로 프로시저는 다음과 같은 한계를 지니고 있었습니다.
- 특정 조건 변경이 전체 로직에 영향을 주는 강결합 구조
- 쿼리 단위 테스트가 어려워 변경에 대한 검증 비용 증가
- 각 도메인에 대한 전문성이 없으며, 단순 정책 변경조차도 운영 리스크로 이어지는 구조
비즈니스 로직 상의 한계뿐만 아니라 프로시저는 변경된 데이터가 1건이든 0건이든, 매번 전체를 재계산합니다. 데이터의 수가 수만~수십만 건이면 실행마다 불필요한 I/O와 Redo log(DB 변경 이력)이 대량 발생하는 것입니다. 그렇다면 해답은 단순해 보였습니다. 프로시저를 걷어내고, 변경된 데이터만 갱신되는 이벤트 기반 구조로 전환하면 되지 않을까요?

2-2. 도메인마다 다른 데이터 생명주기
결론부터 말하면, 그렇게 단순한 문제는 아니었습니다. 실제 상품카드에 노출되는 혜택 플래그들은 서로 다른 도메인의 데이터를 기반으로 구성됩니다. 그런데 각 도메인이 데이터를 제공하는 방식과 실시간성 요구사항이 모두 달랐기 때문입니다. 일부 데이터는 이미 Kafka 기반 이벤트로 전달받을 수 있는 구조가 마련되어 있었지만, 증정 프로모션 또는 쿠폰 여부와 같은 일부 필드는 데이터를 어떤 방식으로 제공받을 것인지부터 협의가 필요한 상태였습니다.
또한 각 플래그는 서로 다른 성격을 가지고 있었기 때문에, 단순히 "모두 실시간으로 처리한다"라는 접근이 아니라, 각 데이터가 어느 정도의 실시간성을 요구하는지 판단하는 과정이 필요했습니다. 결국 이 문제는 코드가 아니라 도메인 간 데이터 흐름과 책임의 재정의에서 시작해야 했습니다.

2-3. 레거시와의 공존과 안전한 전환
10년간 쌓인 프로시저가 만들어내는 결과물과 새 파이프라인의 결과물이 일치하는지 사전에 보장하기 어려웠습니다. 전환 도중 테이블 상태가 일시적으로 불일치하거나, 예상치 못한 레거시 예외 케이스가 드러날 경우 대체 전략(Fallback Strategy)이 없으면 서비스에 직접적인 영향을 줄 수 있습니다. 즉, 이번 전환의 핵심 과제 중 하나는 오래된 레거시 환경에서 서비스 중단 없이 안전하게 배포하는 것이었습니다.
3. 우리가 선택한 접근
3-1. 데이터 특성에 따른 처리 방식 분리
프로시저 속에 결합된 로직을 분리하고, 도메인별로 다른 제공 방식을 수용하기 위해 저희는 데이터 특성에 따라 처리 방식을 나누는 하이브리드 전략을 선택했습니다. 이벤트 기반으로 제공되지 않던 일부 데이터에 대해서는 즉시 실시간 전환이 아닌, 1차적으로 배치 기반 메시지 발행 구조를 도입했습니다.
이 배치 발행은 유관 도메인팀과 협의하여 각 도메인에서 직접 Kafka로 발행하는 방식으로, 기존의 단일 프로시저 기반 처리 구조에서 벗어나 데이터 흐름을 이벤트 스트림으로 연결하는 것에 초점을 맞췄습니다. 이는 최종 목표가 아닌 전환의 첫 단계로, 현재 해당 데이터들의 이벤트 발행을 준실시간으로 전환하는 작업 역시 현재 진행 중입니다.
더 이상 특정 시점에 일괄 계산된 결과를 조회하는 구조가 아니라, 지속적으로 갱신되는 데이터 흐름 위에서 동작하는 구조로 전환되었다는 점에서 의미 있는 첫걸음이었습니다.

3-2. 배치-스트리밍 간 동시성 제어
하이브리드 전략을 적용하면서 또 하나의 중요한 문제가 발생했습니다. 전시 시스템은 최종적으로 단일 테이블의 한 행(Row)에 여러 도메인으로부터 전달받은 데이터를 통합하여 저장하는 구조로 되어 있었기 때문에, 이벤트 기반 스트리밍 처리와 배치 작업이 동일한 데이터를 동시에 갱신하는 상황이 발생할 수 있었습니다.
이 과정에서 테이블 락(Table Lock), 업데이트 경합(Update Contention), 그리고 데이터 덮어쓰기(Overwrite)와 같은 문제가 발생할 수 있었고, 특히 서로 다른 주기로 동작하는 스트리밍과 배치 작업 간의 간섭을 어떻게 제어할 것인지가 중요한 설계 과제로 떠올랐습니다. 단순히 데이터를 나누는 것만으로는 해결되지 않았고, 서로 다른 처리 방식이 하나의 저장 구조 안에서 충돌하지 않도록 제어하는 전략이 필요했습니다.
가장 단순한 접근은 배치가 수행 중인지를 나타내는 플래그를 두어, 메시지 소비 전 이를 확인하는 방식이었습니다. 아쉽게도 이 방법은 단일 인스턴스 환경에서는 유효하지만, 다중 인스턴스 환경에서는 근본적인 한계가 있었습니다. 각 인스턴스가 플래그를 주기적으로 폴링(Polling)해야 하고, 폴링 주기에 따라 반응 지연이 생기며, 인스턴스 수가 늘어날수록 상태 확인에 드는 비용도 함께 증가합니다.
Redis Pub/Sub은 이 구조를 근본적으로 바꿉니다. 배치를 수행하는 단일 인스턴스가 Kafka 일시 중지(Pause) 이벤트를 발행(Publish)하면, 채널을 구독(Subscribe)하고 있는 모든 소비 인스턴스에 즉각 브로드캐스트(Broadcast)됩니다. 배치가 종료되면 동일한 방식으로 재개(Resume) 이벤트를 발행하고, 각 인스턴스는 이를 수신하는 즉시 메시지 소비를 재개합니다.
단, Pub/Sub 이벤트를 수신했다고 해서 처리 중이던 메시지가 즉시 중단되지는 않습니다. 현재 소비 중인 메시지는 끝까지 처리되어야 하고, 그 완료 여부를 추적하기 위한 상태 값은 여전히 필요합니다. 즉, Redis Pub/Sub은 플래그를 없애는 도구가 아니라, 제어 신호의 전파 방식을 폴링에서 푸시(Push) 기반으로 전환하는 도구입니다.

결국 이 둘의 조합으로 저희는 폴링 비용 없이, 인스턴스 수에 관계없이 일관된 동시성 제어를 구현할 수 있었습니다. 플래그가 "무엇을 할지"를 기억하는 역할이라면, Pub/Sub은 "언제 바꿔야 하는지"를 모든 인스턴스에 동시에 알리는 조율자입니다.
3-3. Pub/Sub 신호 유실에 대한 안전장치
한편, Redis Pub/Sub은 메시지 영속성이 없는 실행 후 무시(fire-and-forget) 방식이기 때문에, Task가 재시작 중이거나 네트워크 순단이 발생하면 신호를 수신하지 못할 수 있습니다. 이 경우 해당 Task가 배치 수행 중에도 메시지를 계속 소비하게 되고, 이는 곧 DB 갱신 경합으로 이어집니다.
이를 보완하기 위해 이벤트를 발행한 뒤, 모든 Task가 실제로 스트리밍을 중단했는지를 일정 주기로 폴링하여 확인하는 단계를 추가했습니다. 이때 폴링 기준은 메시지 수신 여부가 아니라, 메시지 처리가 완료된 시점에 각 Task가 Redis에 갱신하는 플래그 값입니다. 즉, 현재 처리 중인 메시지가 끝나기 전에 배치가 시작되는 경쟁 상태(Race condition) 윈도우 자체가 구조적으로 차단됩니다. 만약 타임아웃 내에 모든 Task의 중단이 확인되지 않으면, 배치 수행 자체를 중단하고 알림을 전송합니다.
이 선택에는 명확한 트레이드오프가 있습니다. 배치를 건너뛰면 데이터 갱신이 해당 주기만큼 지연됩니다. 그러나 불확실한 상태에서 배치를 강행했을 때 발생하는 테이블 락과 데이터 경합은 지연보다 훨씬 위험한 결과를 초래합니다. 저희는 완벽한 실시간성보다 데이터 정합성 및 시스템 안정성을 우선순위에 두는 쪽을 선택했습니다.

3-4. Aggregation Topic
도메인별로 다른 데이터 생명주기 문제 중에서도 특히 도메인 간 처리 순서 의존성은 별도의 설계가 필요했습니다.
상품카드에는 상품의 대표 옵션 정보가 노출됩니다. 대표 옵션은 수시로 바뀔 수 있으며 쿠폰과 증정 행사는 이 옵션 단위로 적용됩니다. 반면 BEST(베스트 상품 여부)는 상품 단위로 적용됩니다. 전시 시스템은 이 데이터들을 각각의 토픽으로부터 구독 및 자체 처리하고 있었는데, 각 토픽의 메시지는 서로 독립적으로 발행되기 때문에 도착 및 처리 순서를 보장할 수 없었습니다.
여기서 핵심 문제는 상품 데이터가 존재해야만 쿠폰·행사 데이터를 연결할 수 있다는 순서 의존성에 있었습니다. 예를 들어 신규 상품이 등록되었고 쿠폰 정보가 변경되었습니다. 각각의 토픽을 구독하고 있기에 메시지는 병렬로 처리되게 됩니다. 상품 정보를 아직 처리하지 못한 상태에서 쿠폰이나 행사 메시지가 먼저 처리되어 버리면, 연결할 상품 Row가 존재하지 않아 데이터를 적재할 수 없는 상황이 발생합니다. 단순히 토픽을 분리하는 것만으로는 이 순서를 제어할 수 없었고, 메시지 처리 흐름 자체를 조율하는 구조가 필요했습니다. 이를 위해 Aggregation Topic을 도입했습니다. 각 토픽에서 들어오는 메시지를 곧바로 처리하는 대신, 하나의 토픽으로 모아 처리 순서를 조율하는 구조입니다.

이 구조의 핵심은 파티셔닝 키 설계에 있습니다. 저희는 상품ID를 파티셔닝 키로 사용했습니다. Kafka는 단일 파티션 내에서만 순서를 보장하지만, 동일한 상품 ID를 가진 이벤트는 항상 같은 파티션으로 라우팅되기 때문에, 멀티 파티션 환경에서도 상품 단위의 순서 보장과 수평 확장을 동시에 달성할 수 있습니다.
상품 Row가 아직 존재하지 않는 상태에서 쿠폰이나 행사 이벤트가 먼저 도착한 경우에는 해당 메시지를 건너뜁니다. 단, 이것이 데이터 누락으로 이어지지는 않습니다. 상품 정보를 기준으로 두어, 메시지 처리 시점에 쿠폰·행사 정보를 API로 실시간 조회하여 함께 적재하기 때문입니다. 또한 만일 메시지 처리가 누락되거나 처리에 실패하더라도 슬랙 연동을 통한 알림, 데이터독 모니터링 등으로 후보정 처리 프로세스가 마련되어 있습니다.
3-5. 멱등성 보장 전략
이벤트 드리븐 시스템에서는 또 하나의 중요한 안전장치가 필요합니다. 컨슈머 크래시, Kafka 리밸런싱, 네트워크 타임아웃으로 인한 재시도 등 다양한 원인으로 동일 메시지가 중복으로 전달될 수 있기 때문입니다.
저희는 멱등성(Idempotency) 보장 전략[1]으로 두 가지를 준비했습니다. 먼저 메시지를 배치로 가져온 뒤 중복을 제거하고, 최신 발행 타임스탬프를 기준으로 필터링하여 오래된 이벤트가 최신 데이터를 덮어쓰는 상황을 방지합니다. 이 과정을 통과한 메시지는 UPSERT로 처리되기 때문에, 만에 하나 중복이 남아있더라도 데이터 정합성에 영향을 주지 않습니다. 처리에 실패한 메시지는 에러 알림을 통해 감지하고 수동 보정합니다. (현재까지 운영하면서 실패 사례가 많이 발생하지 않았고 전체 재색인 프로세스가 있어 수동 처리에 대한 리스크가 낮습니다.)
[1] Confluent, Exactly-Once Semantics Are Possible: Here’s How Kafka Does It
3-6. 데이터 정합성 검증
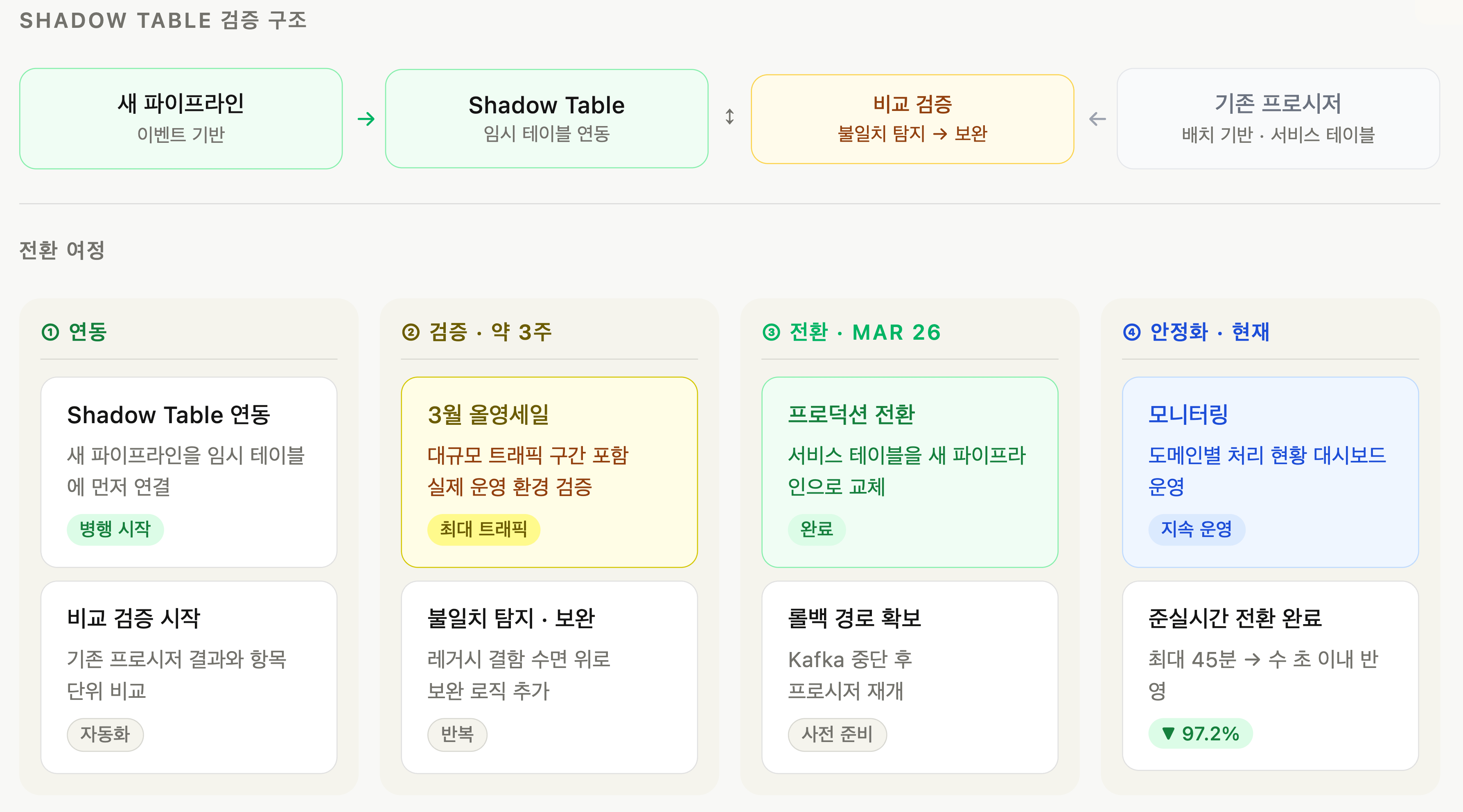
새로운 파이프라인이 완성되었다고 해서 바로 서비스에 연결할 수는 없었습니다. 10년간 쌓인 프로시저의 결과와 새 파이프라인의 결과가 실제로 일치하는지 확인하는 정합성 검증[2] 과정이 마지막 관문으로 필요했고, 이 단계에서 저희는 Shadow Table 전략을 활용했습니다.
실제 서비스 테이블을 바로 교체하는 대신, 임시 테이블에 새 파이프라인을 먼저 연동했습니다. 이후 기존 프로시저가 만들어낸 결과와 새 파이프라인의 결과를 항목 단위로 비교하며 불일치를 탐지했고, 차이가 발생한 케이스에 대해서는 원인을 분석하여 보완 로직을 추가했습니다. 이 검증 과정은 단순히 버그를 잡는 것을 넘어, 오랫동안 미지의 영역으로 남아 있던 레거시 로직의 결함들을 수면 위로 드러내는 계기가 되었습니다.
레거시 전환을 준비하는 팀이라면, 새 파이프라인을 바로 프로덕션에 연결하기보다 Shadow Table로 병행 운영하며 충분한 비교 검증 기간을 두는 것을 권장합니다. 특히 오래된 프로시저일수록 문서화되지 않은 예외 케이스가 숨어 있을 가능성이 높습니다. 실제로 오랜 시간동안 최신화되지 않은 정책과 미처 인지하지 못하고 있던 결함들이 검출되면서, 오히려 Shadow Table의 데이터가 더 정확한 케이스도 다수 발생했습니다. 이 과정 덕분에, 저희는 각 필드의 정의와 적재 기준을 처음부터 다시 정립하는 작업을 진행할 수 있었습니다.
새 파이프라인으로의 전환은 한 번에 이루어졌지만, 그 전에 약 3주간의 병행 운영 기간을 두었습니다. 특히 올리브영 최대 트래픽 구간 중 하나인 올영세일 기간을 포함해, 대규모 행사 환경에서의 안정성을 직접 검증한 뒤 전환을 결정했습니다. 아울러 만일을 대비해 롤백 시나리오를 정리해 두었습니다. 문제 발생 즉시 롤백하고, 중단해 두었던 프로시저를 재개하는 방식을 통해 구 파이프라인으로 복귀할 수 있습니다.
[2] 올리브영 테크블로그, 메시징 시스템 QA, 정합성을 지켜낸 올리브영의 이야기 — 정합성 검증에 대한 자세한 내용을 확인하실 수 있습니다.
4. 마치며
검증을 통과한 이후 실제 서비스 테이블로 전환하면서, 최대 45분까지 지연되던 혜택 플래그가 수 초 이내에 반영되는 구조로 바뀌었습니다. 고객이 보는 화면의 혜택 플래그와 실제 적용 가능한 혜택이 처음으로 일치하게 된 순간이었습니다. 그리고 프로시저가 실패하면 어느 부분에서 실패했는지 추적이 어려웠지만, 이제는 도메인별로 모니터링이 가능해졌습니다. (야호!)
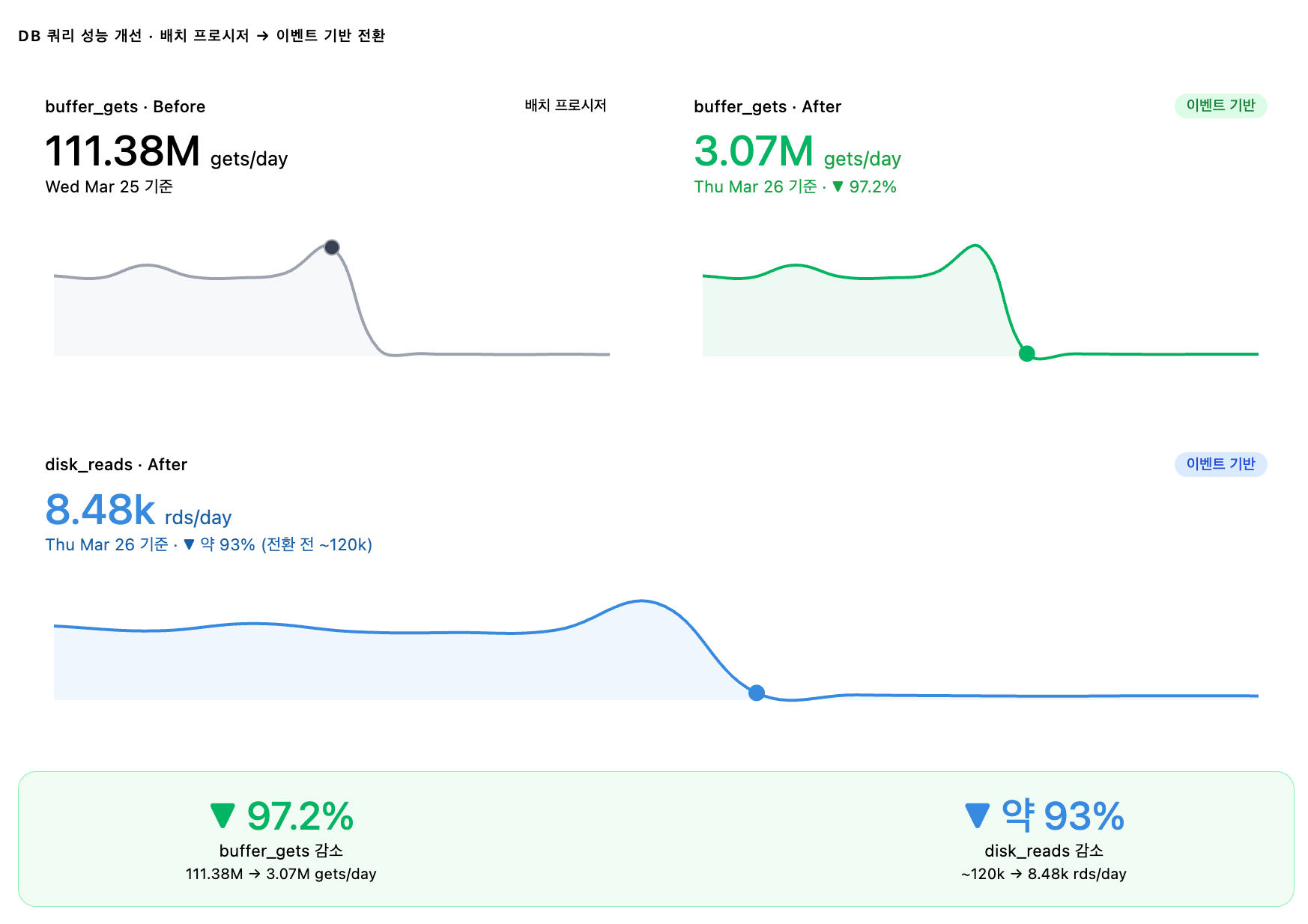
프로시저가 실행마다 수만~수십만 건을 전체 재계산하던 방식이 사라지면서, 변경된 데이터만 처리하는 이벤트 기반 구조로 전환된 결과입니다.
(buffer_gets: 111.38M -> 3.07M로 97.2% 감소, disk_reads: 약 120K -> 8.48K로 93% 감소)
이제 전시 시스템은 더 이상 모든 로직을 직접 계산하지 않고, 각 도메인으로부터 최신 정책과 비즈니스 로직이 반영된 결과 데이터를 전달받아 조합하는 구조로 전환되었습니다. 이를 통해 도메인 로직을 내부에 복제하지 않고도, 보다 정확하고 일관된 데이터를 기반으로 사용자에게 정보를 제공할 수 있게 되었습니다.
개인적으로 더 감사한 부분으로는 이번 프로젝트에서의 협업의 밀도가 그 어느 때보다 높았다는 점이 있었습니다. 이 자리를 빌어 도메인 간 인터페이스를 맞추고 검증하는 모든 과정에 함께해주신 동료분들께 진심으로 감사드립니다. 저와 동료들이 있는 올리브영 개발 조직은 이번 전환에서 멈추지 않습니다. 고객이 올리브영 온라인몰에서 마주하는 모든 순간이 더 빠르고, 더 정확하고, 더 신뢰할 수 있는 경험이 될 수 있도록 크고 작은 개선이 계속되고 있습니다. 지금 이 순간에도요! 그러니 앞으로도 많은 관심과 응원 부탁드립니다.
📖 참고
[3] Martin Fowler, Strangler Fig Application — 레거시 점진 전환의 이론적 배경
[4] Stripe Engineering, Online Migrations at Scale — Shadow Table과 유사한 dual-write 전환 전략
[5] Martin Fowler, Parallel Change — Expand/Migrate/Contract 패턴
