

캠페인과 데이터 정합성
캠페인 시스템은 올리브영 고객들에게 필요한 혜택과 상품을 적절한 타이밍에 제공하여 완성된 쇼핑 경험을 제공하고 구매 전환을 극대화하는 역할을 담당합니다. 주요 임무는 고객의 최신 행동이나 구매 패턴에 기반해 가장 적절하다고 생각되는 알림을 선별해 발송하는 것입니다.
예를 들자면 쿠폰 등의 혜택을 미사용한 사용자에게 혜택을 사용하도록 유도하거나 사용자가 놓치기 쉬운 프로모션을 강조함으로써 올리브영의 구매 전환율을 끌어올리는데 크게 기여하고 있습니다.
그런데 만약 유저 패턴이 실시간으로 시스템에 반영되지 않아서 유저가 필요한 알림을 받지 못한다면 어떨까요? 쿠폰 발행 대상자가 알림을 받지 못한다든지, 혹은 마케팅 정보 수신을 거부했음에도 알림받는 경우가 있겠는데요. 전자는 잠재적인 구매 전환율의 하락으로 이어질 것이고, 후자는 고객의 신뢰를 잃을 수 있겠죠.
이런 이슈는 데이터 정합성(Data Consistency) 측면에서 발생합니다. 다르게 말하면 고객의 최신 상태가 캠페인 시스템에 실시간성으로 반영되지 못했기 때문입니다.
올리브영의 캠페인 시스템은 ODI를 이용한 배치성 스케줄러로 고객 데이터를 소스 데이터베이스에서 싱크하고 있었습니다. 주기는 20분에서 1시간까지 다양하지만 실시간 데이터 변경을 반영하지 못 한다는 명백한 한계를 가지고 있습니다. 배치 주기를 아무리 짧게 해도 짧게는 몇 분, 길게는 몇십 분의 공백이 발생하기 때문입니다.
이는 실시간으로 변화하는 고객 행동에 기민하게 대응하는 것을 어렵게 만들었습니다. 따라서 저희는 이 근본적인 문제를 해결하고자 OGG 기반의 CDC와 Kafka 기반 실시간 스트리밍 시스템으로 데이터 파이프라인을 구축하기로 했습니다.
그럼 이제부터 캠페인 도메인에서 ODI 기반의 배치 시스템을 OGG와 Kafka 기반의 CDC 아키텍처로 성공적으로 전환한 여정과 그 과정에서 마주한 기술적 도전, 그리고 해결책에 대해 소개드리고자 합니다.
ODI의 기반 캠페인 시스템의 한계
기존 올리브영 캠페인 시스템은 ODI(Oracle Data Integrator)를 활용한 배치(Batch) 방식으로 고객 데이터를 동기화했습니다. 이 구조는 데이터 웨어하우징 통합에는 최적화되어 있지만, 실시간 대응이 필요한 캠페인 서비스에는 근본적인 한계를 가집니다.
- ODI 핵심 구조 및 작동 원리
- 데이터 추출 (Extract): 소스 데이터베이스에서 데이터를 추출합니다.
- 타겟 적재 (Load): 추출한 데이터를 타겟 데이터베이스에 적재합니다.
- 대규모 변환 (Transform): 데이터를 적재한 후, 타겟 데이터베이스의 성능을 이용하여 대규모 데이터 변환(조인, 계산 등)을 수행합니다.
- 동기화 방식: 캠페인 시스템이 바라보는 원천 테이블에 대응하는 ODI 스케줄러를 통해 동기화가 이루어집니다.
- 동기화 주기: 최소 20분에서 최대 1시간까지 주기적인 간격으로 데이터를 싱크합니다.
- 데이터 매핑 구조: 1:1 단순 매핑부터 여러 소스 테이블을 조인하여 하나의 타겟에 싱크하는 복잡한 방식까지 혼재되어 있습니다.
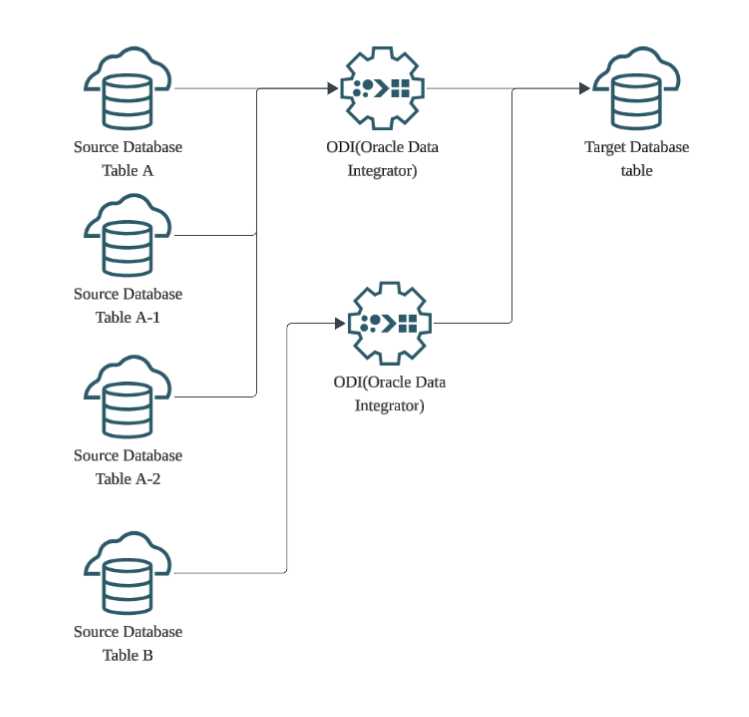
이러한 배치 중심의 구조는 구체적으로 다음과 같은 성능 및 비즈니스적 문제로 이어졌습니다.
데이터 지연 (Data Latency)
- 실시간 대응 불가: 데이터가 정해진 배치 주기에만 업데이트되므로, 고객의 행동 변화(예: 마케팅 수신 동의/철회, 쿠폰 발급)에 대한 최신 정보를 즉각적으로 활용할 수 없었습니다.
- 고객 타겟팅 오류: ODI 수행 시간대에 따라 데이터 최신화가 지연되어, 마케팅 수신 동의를 했음에도 타겟팅에서 누락되거나(기회 손실), 반대로 알림을 껐음에도 알림을 받는(고객 경험 저하) 이슈가 발생했습니다.
성능 이슈 (Performance Bottleneck)
- 소스 DB 부하 집중: 특정 시간대에 쿠폰 대량 발급이나 회원 멤버십 승급과 같이 대규모 데이터 변경이 발생하면, ODI가 이를 한꺼번에 처리하려 하면서 소스 데이터베이스에 과도한 부하를 주었습니다.
- 연쇄적인 싱크 지연: 처리해야 할 데이터량이 많아지면 ODI 작업 자체가 지연되고, 이 지연된 ODI Task가 전체 시스템에 영향을 미쳐 모든 데이터 싱크 프로세스가 함께 지연되는 결과를 야기했습니다.
OGG(Oracle Golden Gate)
올리브영이 실시간 데이터 동기화(CDC)를 위해 채택한 OGG는 엔터프라이즈급 안정성과 확장성을 갖춘 툴로, 기존 배치 시스템의 한계를 극복하는 핵심 기능을 제공합니다.
OGG의 주요 기능은 Oracle DB의 트랜잭션 로그를 활용하여 데이터 변경 사항을 실시간으로 캡처하고, 이를 Kafka 스트리밍 생태계로 효율적으로 전송하는 데 집중되어 있습니다.
실시간 변경 데이터 캡처 (CDC 기능)
- OGG는 Oracle 데이터베이스의 트랜잭션 로그(Redo Log)를 직접 읽어 INSERT, UPDATE, DELETE와 같은 데이터 변경 사항을 실시간으로 캡처합니다. 이는 데이터 변경이 발생하자마자 즉시 감지하여 데이터 지연 시간을 극소화합니다.
Kafka 연동 및 데이터 처리
- 캡처된 변경 사항을 Kafka 환경에서 사용하기 적합하도록 JSON, Avro, Parquet 등의 형식으로 변환하고 포맷팅합니다.
Kafka로 전송
- 변환된 데이터를 Kafka Connect 프레임워크를 통해 지정된 Kafka 메시지로 안정적으로 전송합니다.
데이터 파이프라인 구축
- OGG 커넥터를 사용하여 데이터베이스를 Kafka의 데이터 스트리밍 생태계에 연결함으로써, 복잡한 실시간 데이터 파이프라인을 효율적으로 구축할 수 있습니다.
안정성, 신뢰성 및 확장성
- OGG는 엔터프라이즈급 솔루션으로서, 데이터 손실 없이 안정적인 데이터 복제 및 전송을 보장합니다.
- Kafka Connect 프레임워크를 사용하기 때문에 수평 확장(Scale-out)이 용이하며, 여러 데이터베이스의 변경 사항을 동시에 처리할 수 있는 능력을 갖춥니다.
OGG 커넥터의 활용
OGG 커넥터를 활용하면 데이터베이스의 변경 사항이 발생하는 즉시 Kafka로 전송되어, 실시간 분석, 데이터 웨어하우징, 마이크로서비스 간 데이터 동기화 등 다양한 실시간 시나리오에 즉각적으로 활용할 수 있습니다.
OGG를 활용한 하이브리드 CDC 적용 전략
OGG 커넥터를 그대로 도입하지 못한 주요 원인은 기존 배치 시스템의 복잡한 데이터 통합 로직 때문이었습니다. 이 문제를 해결하고 커넥터의 장점을 유지하기 위해 OGG 커넥터와 워커를 혼합한 하이브리드 아키텍처를 절충안으로 채택했습니다.
- OGG 커넥터 단독으로는 기존 ODI 시스템의 복잡한 요구사항을 처리할 수 없었습니다.
-
1:1 매핑 제약 : OGG 커넥터는 기본적으로 소스 테이블의 Row와 타겟 테이블의 Row가 1:1로 대응하는 구조만 지원합니다. 즉, 타겟 테이블의 컬럼이 모두 소스 테이블에 존재해야 합니다.
-
복잡한 비즈니스 로직 미지원 : 기존 캠페인 도메인은 ODI를 통해 다수의 원천 테이블을 조인(Join) 하고 데이터를 가공하여 하나의 통합 테이블(Consolidated Table) 에 데이터를 싱크하는 복잡한 통합 로직을 가지고 있었습니다.
-
결과 : 순수한 OGG 커넥터만으로는 이처럼 예외적이고 복잡한 데이터 변환 및 통합 비즈니스 로직을 처리하는 것이 불가능했습니다.
-
하이브리드 구조 구상
OGG는 CDC의 안정성을, Campaign-Worker는 데이터의 통합 및 가공을 담당하는 방식으로 역할을 분리했습니다.
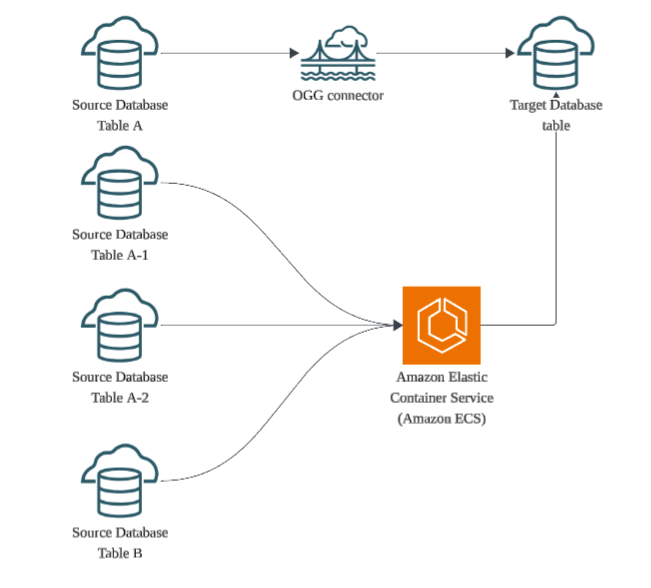
1. OGG 커넥터 담당 (1:1 단순 매핑)
메시지 발행량이 많고, 별도의 비즈니스 로직이 필요 없는 테이블은 OGG 커넥터를 통해 ADW(타겟 DB)로 자동 싱크됩니다. 애플리케이션 레벨의 관리 없이 안정성과 효율성을 확보했습니다.
2. Campaign-Worker 담당 (복합 처리 로직)
복잡한 비즈니스 로직이 필요한 테이블 (예: 여러 테이블 조인, 조건부 변환)의 변경 메시지는 Kafka를 통해 워커가 직접 소비하여 자체 로직으로 처리합니다. 커넥터의 안정성을 유지하면서 복잡한 통합 요구사항을 만족시킵니다.
메시지 순서 문제와 해결 전략 요약
문제 상황: 테이블 간의 의존성
하지만 위 구조 역시 완전한 솔루션은 아니었습니다. 가장 큰 문제를 하나 꼽자면 시스템 자체가 여러 토픽에서 발행된 메시지들의 순서에 서로 의존하는 구조라는 점 입니다. 하지만 카프카의 단일 파티션이 아닌 서로 다른 토픽들간의 메시지 순서 제어는 카프카 자체의 메커니즘으로만으론 불가능합니다.
이러한 이슈로 인해 핵심 문제는 서로 연관된 두 테이블이 바라보는 토픽의 메시지가 타겟에서 원하는 순서대로 소비되지 않을 때 발생합니다.
이해를 돕기 위해 테이블 A와 테이블 B를 다음과 같이 정의하겠습니다.
- 테이블 A (베이스 정보): 회원 기본 정보(회원번호, 회원ID 등)를 담고 있으며, 변경량이 많습니다.
- 테이블 B (부가 정보): 마케팅 수신 정보 등 부가 데이터를 담고 있으며, 테이블 A와 조인되어 타겟에 통합됩니다.
문제 발생 원인 및 시나리오
문제는 테이블 B의 변경 메시지가 먼저 도착했는데, 테이블 A에 해당하는 베이스 정보(Key)가 타겟 테이블에 아직 없는 경우에 발생합니다. 일반적으로는 A 테이블의 변경이 먼저 완료되지만, 드물게 A와 B 테이블이 거의 동시에 업데이트될 경우 Kafka 토픽에서 메시지 순서가 보장되지 않아, B에 해당하는 A의 베이스(Key) 정보를 찾을 수 없어 B의 변경 메시지가 저장에 실패하는 문제가 발생했습니다.
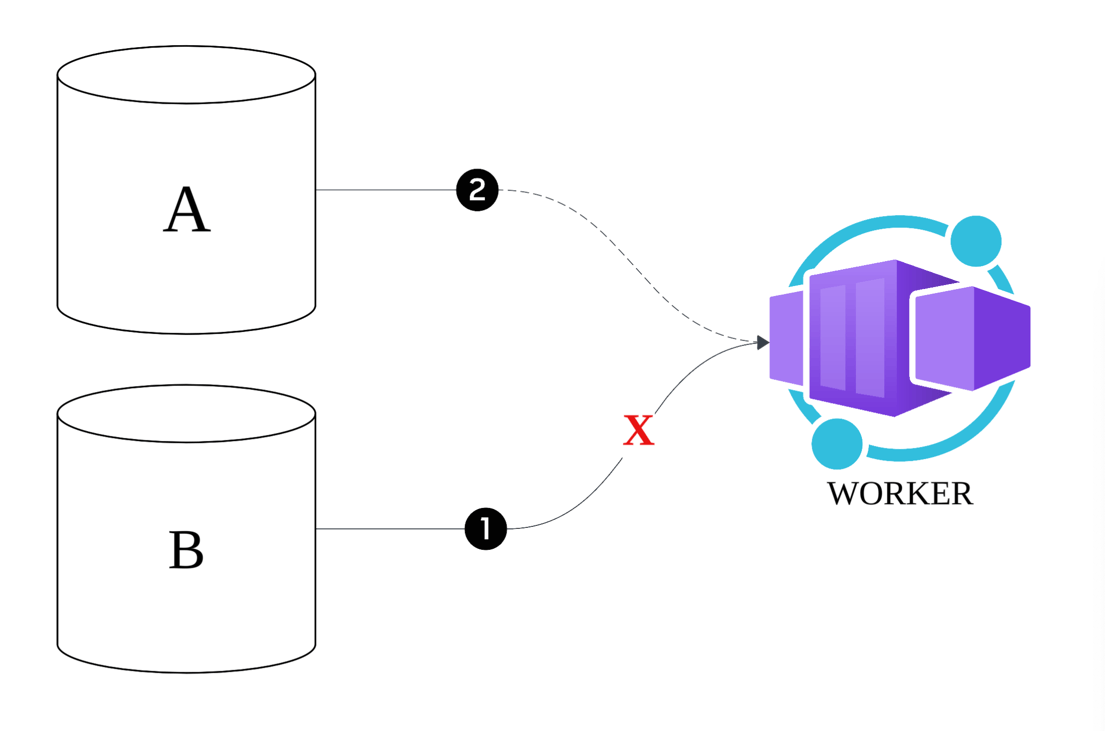
해결 전략 - Retry, DLT, 복구 배치를 활용한 3중 안전장치
이러한 이슈를 보완하기 위해 메시지의 소비 순서를 강제로 보장할 수 없다는 가정을 바탕으로, 손실을 최소화하고 복구 능력을 확보하는 3가지 전략들을 보완했습니다.
1. Retry (재시도) 메커니즘
- 목적: 일시적인 메시지 도착 지연으로 인한 데이터 불일치 문제를 해결합니다.
- 작동: 베이스 테이블(A)의 레코드(ROW)가 없을 경우, 최대 3회까지 짧은 간격으로 즉시 재시도를 수행하여 대부분의 요청을 성공시킵니다.
2. DLT(Dead Letter Topic) 발행
- 목적: 컨슈머 처리량 부족이나 장기간의 순서 문제로 인한 메시지 유실을 방지하고 격리합니다.
- 작동: 3회 재시도 후에도 실패한 메시지는 별도의 DLT 토픽으로 발행합니다.
3. DLT 복구 배치 (DLT Recovery Batch)를 통한 최종 정합성 보장
- 목적: 영구적인 데이터 누락을 해결하여 최종 데이터 정합성을 보장합니다.
- 작동: DLT 리스너가 해당 메시지를 받아 별도의 테이블에 저장하고, 5분/1시간 주기로 동작하는 복구 배치를 통해 저장되지 않은 건들을 주기적으로 재처리합니다. 이는 베이스 테이블 정보가 뒤늦게 도착했을 경우의 누락을 해결합니다.
Retry와 DLT 사용 예시
Retry와 DLT를 사용한 이중 백업 전략을 수립할 때, 다음과 같은 가정을 바탕에 두었습니다.
- 가정 1 : 연관되어 있는 두 토픽에서 발행하는 메시지는 기본적으로 짧은 텀의 간격을 두고 동시에 발행됩니다.
- 가정 2 : 메시지 발행량에 따라 이 텀은 커질 수 있으며, 기본적으로 테이블 A와 B 중의 순서는 보장 불가합니다.
위 가정을 기반으로 Retry 로직을 적용했습니다. 전체 처리 속도가 Retry 덕분에 감소할 수 있지만, 데이터 정합성이 훨씬 중요했기에 짧은 간격으로 Retry 시도하는 것만으로도 대부분의 요청이 성공하는 것을 확인했습니다. 하지만 Retry만으로도 부족한 케이스가 존재했습니다. 특정 토픽에 대해 메시지 발행량이 컨슈머의 처리량보다 커져서 offset lag이 많이 발생한다면, 몇 분의 간격으로 토픽의 메시지 소비 텀이 길어지기도 했기 때문입니다. 이처럼 Retry만으로 해결되지 않는 장기적인 지연 케이스를 수정하기 위해 실패 케이스를 저장하는 DLT 테이블과, 해당 테이블에서 데이터를 복구시키는 복구 배치가 필요했습니다.

백업 로직은 다음과 같이 구성됩니다.
- Base 테이블 (A)에 해당하는 레코드가 없을 경우 예외 발생
- 예외 발생시 최대 3회 Retry
- Retry 후에도 Base 테이블이 없을 경우 DLT 로 발행
- DLT 리스너에서는 해당 건을 받아 따로 테이블에 저장
- 이후 복구 배치가 돌면서 저장되지 않은 건들을 BASE 테이블에 저장 시도
//카프카 에러 핸들러에서의 DLQ 설정
@Bean
fun kafkaListenerMultiConcurrencyContainerFactory(kafkaTemplate: KafkaTemplate<String, Any>): ConcurrentKafkaListenerContainerFactory<String, String> {
val factory: ConcurrentKafkaListenerContainerFactory<String, String> = ConcurrentKafkaListenerContainerFactory()
factory.consumerFactory = memberConsumerFactory()
factory.containerProperties.ackMode = ackMode
factory.containerProperties.pollTimeout = POLL_TIMEOUT
factory.containerProperties.idleBetweenPolls = idleBetweenPolls
factory.setConcurrency(6)
val errorHandler = getDlqErrorHandler(kafkaTemplate)
factory.setCommonErrorHandler(errorHandler)
return factory
}
private fun getDlqErrorHandler(kafkaTemplate: KafkaTemplate<String, Any>) : DefaultErrorHandler {
return DefaultErrorHandler(
DeadLetterPublishingRecoverer(kafkaTemplate) { record, ex ->
TopicPartition("${record.topic()}.dlq", record.partition())
}, FixedBackOff(BACK_OFF_INTERVAL, KAFKA_CONSUMER_MAX_RETRY_ATTEMPT)
)
}검증과 모니터링
CDC 기반 데이터 파이프라인의 핵심은 실시간 데이터의 정합성과 안정성을 보장하는 것입니다. 이를 위해 Datadog 대시보드와 주기적 배치 작업을 결합한 다각적인 검증 및 모니터링 체계를 구축하였습니다.
1. Datadog 기반 실시간 모니터링
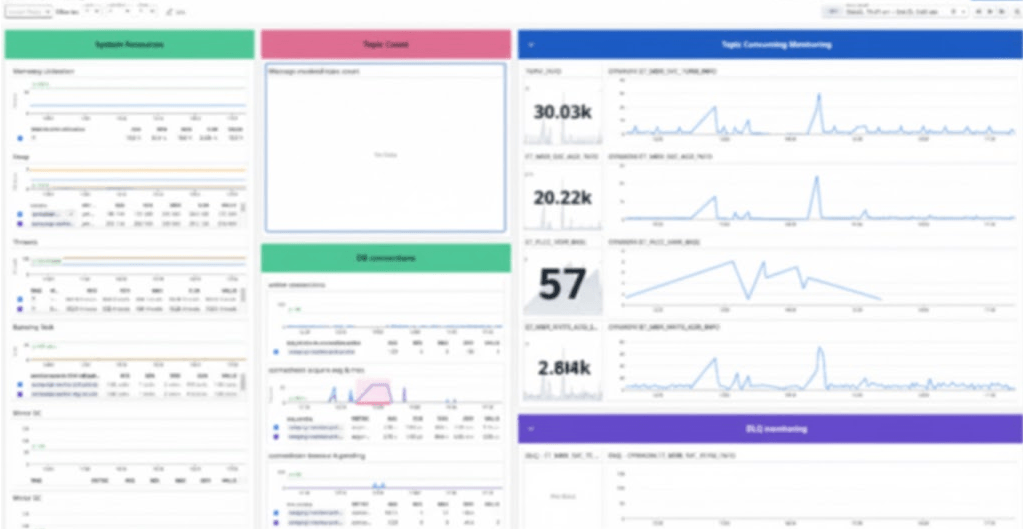
Datadog 대시보드는 CDC 시스템의 운영 현황과 성능 지표를 실시간으로 시각화하여 데이터 흐름의 건강 상태를 파악하는 핵심 도구입니다.
- 토픽 메시지 유입 현황: 각 토픽에 얼마나 많은 메시지가 들어오고 있는지를 파악하여 실시간 데이터 로드 상태를 확인합니다.
- 컨슈머 지연 (Kafka Lag): 토픽별로 컨슈머가 메시지를 처리하지 못하고 얼마나 뒤처지고 있는지(지연 정도)를 모니터링하여, 시스템의 처리 속도 및 병목 현상을 즉시 감지합니다.
2. DLQ 후처리 배치를 이용한 정합성 검증 및 복구
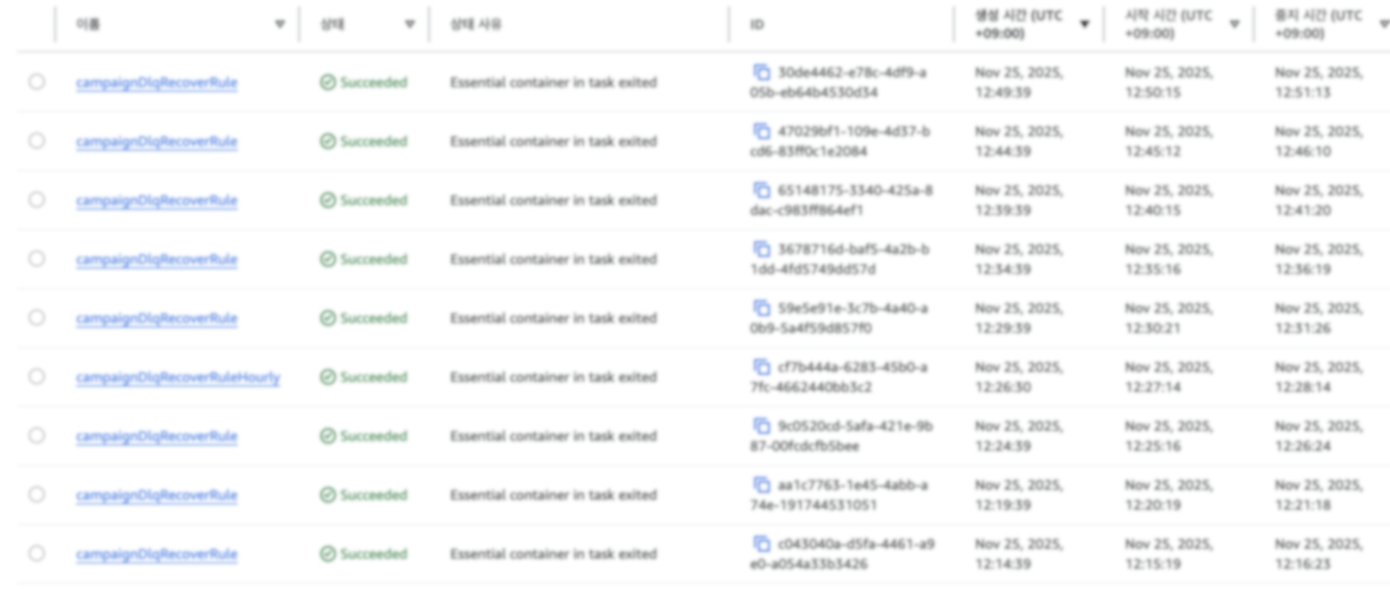
- 검증 배치: 실제 데이터가 소스와 타겟 간에 정확하게 동기화되었는지를 확인하는 배치 작업입니다.
- DLT 복구 배치: 실패 메시지가 격리된 DLT(Dead Letter Topic) 테이블에 쌓이면, 이 배치 작업이 주기적으로 돌면서 저장되지 않은 메시지들을 재처리하여 누락된 데이터가 없도록 복구합니다.
이러한 검증 배치 및 복구 배치의 수행 내역과 복구 현황 또한 모니터링 대시보드에서 확인할 수 있도록 구성하여, 데이터 무결성을 이중으로 보장합니다.
최종 구현
최종적으로 구축된 CDC 아키텍처는 다음과 같습니다.

OGG-kafka 기반의 CDC 최종 아키텍처는 데이터의 종류에 따라 처리 경로를 이원화하고, 재시도(Retry)와 DLT(Dead Letter Topic)를 활용한 복합적인 복구 전략을 통해 데이터 정합성과 안정성을 극대화했습니다.
️데이터 처리 방식
- 이원화된 경로: 데이터를 단순 베이스 정보와 복잡한 부가 정보로 나누어, 각 데이터의 특성에 맞는 최적의 경로로 처리했습니다.
- 커넥터(OGG) 담당: 가장 변경량이 많은 핵심 데이터는 커넥터를 활용해 신속하고 안정적인 ADW(Analytical Data Warehouse) 적재를 담당합니다.
- 워커(Campaign-Worker) 담당: 약관 동의, 마케팅 정보 등 여러 테이블의 변경 사항을 받아 복잡한 조인 및 변환 로직을 수행하여 타겟 테이블에 적재합니다.
🛡️ 복합적인 비즈니스 로직 환경에서 메시지 순서 불일치로 인한 데이터 손실을 방지하기 위해 3단계의 방어 메커니즘을 구축했습니다. 회원 기본 정보(Base) 메시지가 부가 정보 메시지보다 늦게 도착하여 발생하는 일시적인 데이터 불일치 문제를 해결하기 위해, Campaign-Worker는 매칭되는 회원 번호(MBR_NO)가 없으면 최대 3회까지 메시지 처리를 재시도(Retry)하여 순서 지연을 해소합니다. 이후 3회 재시도 후에도 처리에 실패한 메시지는 DLT(Dead Letter Topic)로 이동시켜 별도의 테이블에 안전하게 저장합니다. 이는 메시지 유실을 방지하는 1차적인 격리 조치입니다. 마지막으로 복구 배치가 DLT 테이블에 쌓인 실패 메시지들을 대상으로 주기적인 실행(5분 및 1시간 주기)을 통해 누락된 기본 정보가 타겟에 반영된 후 실패 메시지를 재처리하여 최종적인 데이터 정합성을 보장합니다.
성과
ODI 기반(Batch)에서 OGG/Kafka 기반(CDC)으로 전환하며 다음과 같은 개선 사항을 달성했습니다.
- 데이터 처리 속도: 20분 ~ 1시간 주기 (배치)에서 준실시간 (이벤트 기반)으로 개선
- 고객 대응 능력: 실시간 고객 행동에 대한 지연 대응에서 벗어나, 변경 발생 즉시 타겟팅 가능 (예: 마케팅 동의 즉각 반영)
- 소스 DB 부하: 특정 시간대에 부하가 집중되던 문제에서 트랜잭션 로그 기반으로 전환되어 부하 분산 및 최소화
- 데이터 정합성 보장: 순서 이슈 발생 시 데이터 누락 위험이 있었으나, Retry, DLT, 복구 배치를 통한 이중 안정성 확보로 극복
- 모니터링: Datadog과 Slack 등을 활용하여 메시지 누락 발생이나 소비 이상 시 즉시 탐지 가능
이번 프로젝트는 올리브영 캠페인 시스템의 데이터 파이프라인 핵심 문화를 '주기적 동기화' 에서 '이벤트 기반의 실시간 반응' 으로 변화시켰다는 점에 큰 의의가 있습니다.
특히, ODI의 1:N 조인 변환 로직을 OGG 커넥터와 Campaign-Worker의 하이브리드 구조로 분리하고, 메시지 순서 문제 해결을 위해 DLT와 복구 배치를 적용한 것은 실시간 스트리밍 환경에서 복잡한 비즈니스 로직과 엔터프라이즈급 안정성을 동시에 확보한 전략이었습니다.
이러한 준실시간 데이터 환경을 통해 올리브영은 고객의 행동 변화에 즉각적으로 대응하는 개인화된 캠페인을 제공할 수 있는 견고하고 확장 가능한 시스템을 구축하며, 고객 경험 측면에서 한 단계 더 성장할 수 있었습니다.
