매장 도메인을 구현해 나가는 여정
안녕하세요! 올리브영에서 매장 도메인을 담당하고 있는 알렉스입니다 :)
이전 글에서 저희는 이벤트 스토밍, 바운디드 컨텍스트 식별, 컨텍스트 매핑 등 DDD의 전략적 설계 과정을 통해 매장 도메인을 추출하는 과정을 알아보았습니다.
이번 글에서는 저희가 지난 1년간 걸어온 아래의 여정 중, Part.2 전술적 설계를 바탕으로 매장 도메인을 실제 구현한 사례를 소개하겠습니다 🚀
- 10년 된 레거시를 현대화하다 - Part.1: 도메인 분리의 첫걸음
- ✅ 10년 된 레거시를 현대화하다 - Part.2: 매장 도메인의 구현 여정
- 10년 된 레거시를 현대화하다 - Part.3: 대고객 서비스로의 확장
목차
- 매장 서비스 구축을 위한 준비
- 어떤 것들이 필요한가?
- 멀티모듈 아키텍처
- CQRS 패턴
- 도메인 모델 구축
- 테이블 경량화·통합
- Entity와 VO
- 다음 이야기
매장 서비스 구축을 위한 준비
어떤 것들이 필요한가?
도메인 모델을 구축하고 매장에 관련된 서비스를 제공하려면 어떤 것이 필요할까요?
가장 먼저 코드를 구현할 프로젝트가 필요합니다.
현재 올리브영 대부분의 팀에서는 코프링(코틀린+스프링부트) 형태의 스켈레톤 프로젝트를 사용하고 있습니다.
하지만 제가 오프라인 팀에 합류했을 때는 구성원들 대부분이 이미 자바 프로젝트로 개발을 진행하고 있었고, 코틀린을 사용해 본 인원이 한 명도 없던 상태였습니다.
이 상황에서 무작정 코틀린을 팀에 도입한다면 어떨까요?
물론 어떻게든 개발은 할 수 있겠지만, 저는 코틀린의 주요 특징 및 함수형 패러다임과 객체지향 패러다임을 확실히 이해하고 사용하지 않는다면 오히려 코드가 더 난잡해질 수 있다고 생각합니다.
모든 코드 구석구석에 ?가 포진되어 있는 장관이 펼쳐질 수도 있죠.
- 코틀린의 특징·장점이 궁금하다면 저희 팀원이 최근에 작성하신 Java를 주로 다루는 개발자가 생각하는 Kotlin 장점 🌼 글을 참고해 보시길 추천드립니다 😁
따라서 저희는 오프라인 신규 프로젝트들을 위한 자프링(자바+스프링부트) 형태의 스켈레톤 프로젝트를 구축하기로 결정했습니다.
팀장님과 테크리더 분은 한 달이라는 기간을 주시면서, 저에게 아래와 같은 미션을 할당해 주셨습니다.
- 기본 기능(JPA, MyBatis, Swagger, Test Code, DB Multi Datasource)과 함께 간단한 예시용 API가 개발된 스켈레톤 프로젝트
- AWS ECS 환경 구축
- TeamCity를 통한 CI/CD 파이프라인 구축
- Datadog을 이용한 모니터링 구축
이번 글에서는 애플리케이션 영역까지만 소개하고, AWS & TeamCity & Datadog 등 인프라 영역에 대한 내용은 다음 포스팅에서 소개해보겠습니다 🙌
멀티모듈 아키텍처
저는 곧바로 테크리더와 함께 애플리케이션 아키텍처를 설계하기 시작했습니다.
매장 서비스에서는 내부 서비스끼리의 통신(internal)과 대고객 서비스와의 통신(external) 이 모두 이루어질 예정이었는데요.
하지만 요구사항들이 구체화 되지 않은 상태에서, 처음부터 바로 external 환경과 internal 환경 자체를 분리하는 것은 아직 이르다고 판단하였습니다.
따라서 초반에는 단일 환경에서 서비스를 시작하고, 추후 환경을 분리하기 쉽도록 멀티모듈 아키텍처를 도입하기로 하였습니다.
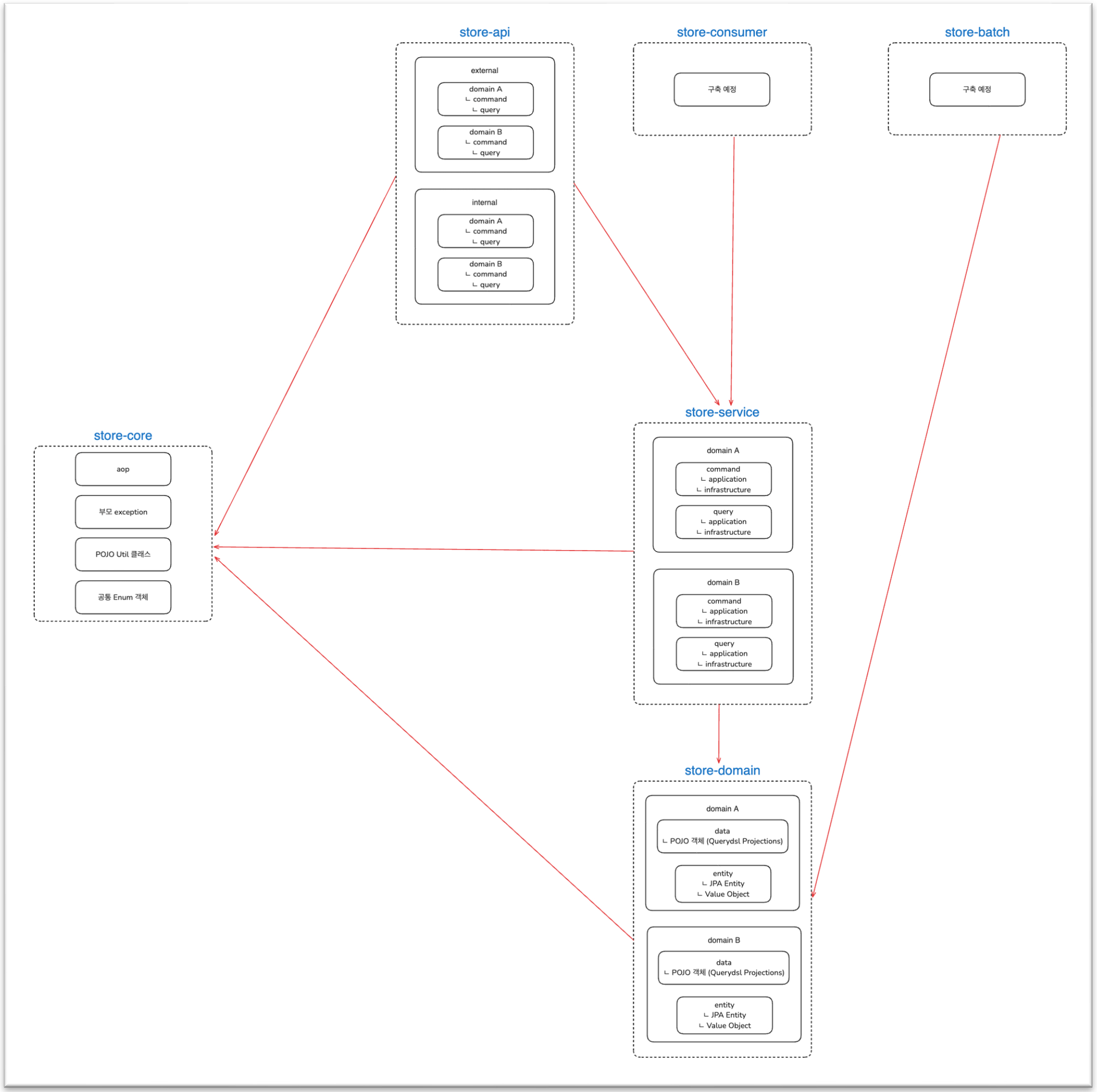
위의 사진에서 볼 수 있듯이, 우선 store-core 모듈은 모든 모듈에서 의존합니다.
단, 흔히 얘기하는 common(core)의 비대함을 방지하기 위해 몇 가지 규칙을 세웠는데요.
core 모듈에 들어가는 코드는 특정 도메인 및 비즈니스와 관련이 없어야 하고, 범용적으로 사용되는 횡단 관심사(AOP)나 POJO로 이루어진 유틸리티 클래스 등만 허용됩니다.
store-domain 모듈에는 각 도메인 패키지 내부에 entity와 data 패키지로 나누어져 있습니다.
entity 패키지에는 JPA Entity 객체가 존재하고, 동일한 관심사끼리 컬럼·로직을 응집시키고 불변을 유지하기 위한 Value Object도 함께 위치합니다.
data 패키지에는 DTO가 존재하는데요. 이는 Querydsl이나 MyBatis를 사용해서 조회한 값을 바인딩할 때 사용되는 객체입니다.
store-service 모듈에서는 application layer와 infrastructure layer를 통해 유스케이스를 구현하고, 비즈니스 요구사항을 수행합니다.
말 그대로 매장 관련 서비스를 담당하는 모듈인 셈이죠.
store-api, store-consumer 모듈은 모두 presentation 영역(클라이언트)을 담당하며, store-service 모듈을 재사용합니다.
이런 아키텍처일 때 얻을 수 있는 장점은 무엇일까요?
API 서버, Consumer 서버, Batch 서버가 추후 각각의 환경으로 분리되더라도 필요한 모듈만 조합하여 배포할 수 있습니다.
즉 중복 코드를 방지할 수 있고, 비즈니스 로직 또한 응집시킬 수 있다는 장점이 있습니다.
그리고 store-api 모듈 안을 보면 패키지로 분리된 external과 internal이 존재합니다.
추후 API 서버에서도 external 환경과 internal 환경이 서로 분리된다면, 이 또한 해당 패키지를 그대로 각자의 모듈에 이관하고 나머지 모듈은 그대로 조립하여 배포만 하면 손쉽게 구성되겠죠.
CQRS 패턴
몇몇 분들은 눈치채셨을 수도 있겠지만, store-api 모듈과 store-service 모듈 안에는 각각 command 패키지와 query 패키지가 분리된 것을 볼 수 있습니다.
또한, store-domain 모듈에서도 entity와 data가 분리되어 있죠.
저희는 멀티모듈 아키텍처와 같이 CQRS 패턴을 함께 적용하기로 하였습니다.
(사실 현재의 모습은 CQS에 가깝습니다만, 최종 아키텍처 기준으로 말씀드리기 위해 CQRS로 소개하고 있습니다 😅)
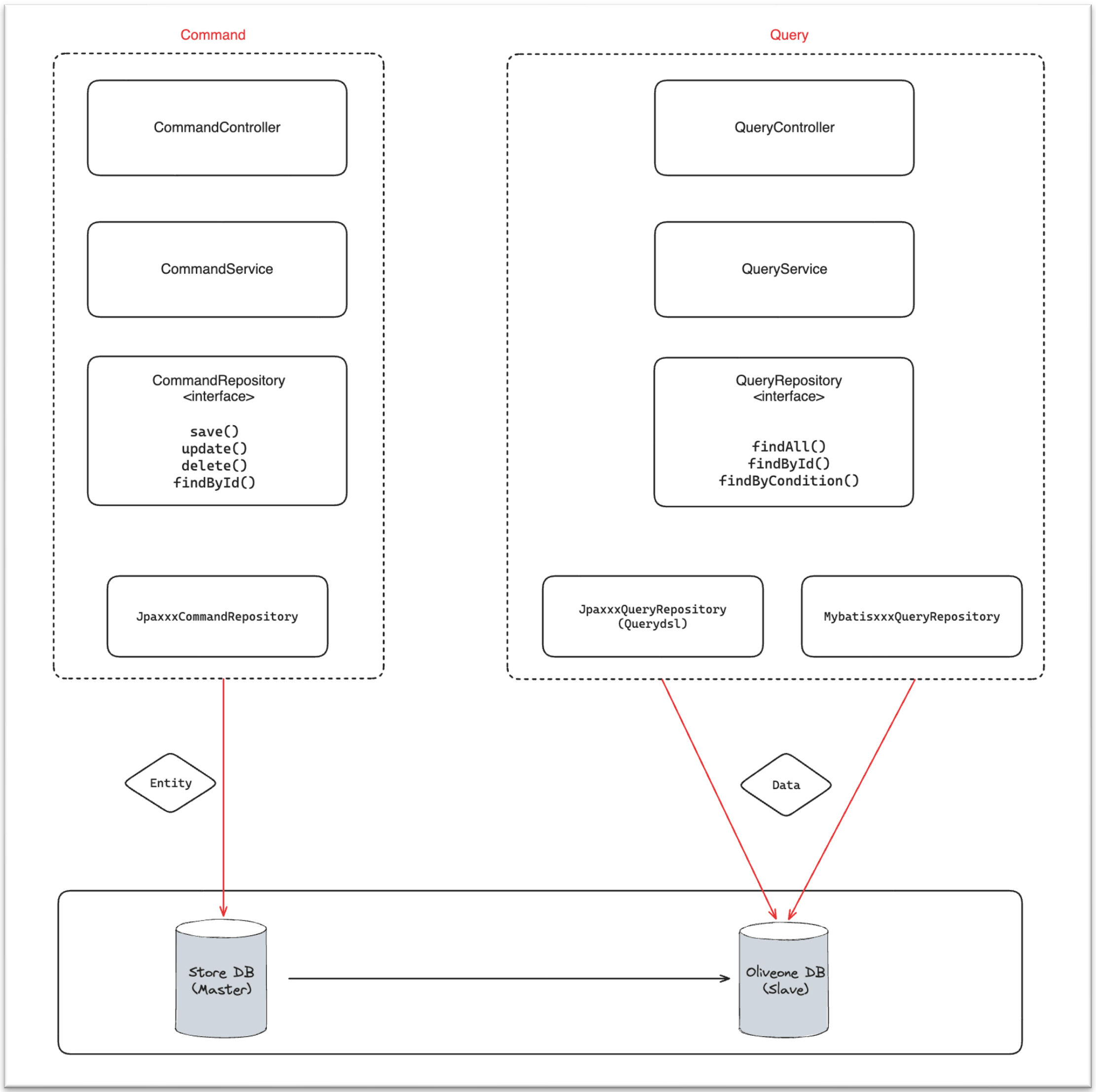
CQRS 패턴의 특징은 명령성(CREATE, UPDATE, DELETE)과 조회성(SELECT)을 서로 분리하는 디자인 패턴인데요.
자칫 복잡할 수도 있는 이 패턴을 적용한 이유는 뭘까요?
저희는 새로운 도메인을 신규로 개발하는 것이 아닌, 기존 레거시에서 매장에 대한 도메인을 추출하여야 합니다.
최종적으로는 매장 도메인 자체의 DB를 별도로 구축하는 것이 목표입니다.
이때 Command 영역(entity)에서 JPA로 구현할 도메인 엔티티는 유용하게 사용될 것입니다.
또한 Command 패키지를 따로 분리함으로써 데이터 추가/수정/삭제에 대한 커맨드를 단순화시키고, 관련 비즈니스 로직들을 응집시킬 수 있습니다.
그렇다면 조회 쪽도 JPA로 구현된 도메인 엔티티를 그대로 사용하면 어떨까요?
레거시에서 기존에 제공하는 매장 관련 조회 쿼리는 보통 적게는 몇십 줄에서 많게는 몇백 줄까지의 SQL 문으로 이루어져 있습니다. 이런 쿼리들을 한 번에 JPA로 변경하는 것은 쉽지 않겠죠.
따라서 Query 영역에서는 Querydsl과 MyBatis를 같이 사용할 수 있도록 아키텍처를 설계하여, 기존 조회 기능을 손쉽게 이관하고 신규 조회 기능도 더욱 빠르게 개발할 수 있도록 했습니다.
또한 Query 영역을 Command와 분리한다면 추후 조회 관련 성능을 높이기에도 용이할 겁니다.
이뿐만 아니라 올리브영에서는 Master DB와 별개로 Read Replica DB를 구성해서 함께 사용하고 있는데요. 이 역시 CQRS 패턴을 선택하게 된 사유 중 하나였습니다.
도메인 모델 구축
자 이제 위의 아키텍처를 사용해서 프로젝트의 뼈대는 구축이 완료되었습니다.
이제 본격적으로 도메인 모델을 구축해야 하는데요.
앞서 말씀드렸듯이 저희는 기존 레거시에서 매장에 대한 도메인을 추출하여야 합니다.
즉 테이블을 새로 만드는 것이 아닌, 기존 테이블을 사용해야 합니다.
매장에 관련된 기존 테이블은 어떻게 구성되어 있었을까요?
단순 매장 정보에 관련된 테이블만 봐도 매장부가정보, 부가상세정보, 상세정보, 일반정보상세, 추가정보, 통합정보 등 굉장히 많은 테이블들이 현재 사용하지 않는 컬럼들과 함께 포진되어 있었습니다.
테이블 경량화·통합
저희는 정리되지 않은 채로 오랜 시간 방치되어 왔던 테이블들을 모두 그대로 가져갈 수는 없다고 판단했습니다.
따라서 저는 도메인 모델을 구축하기 전, 2가지의 작업을 먼저 시작하였습니다.
- 필요한 컬럼 식별
- 필요한 테이블 식별
[필요한 컬럼 식별]
우선 저희의 가장 큰 목표는 매장 서비스에서 관리해야 할 테이블과 컬럼들을 최대한 통합하고 줄이는 것이었습니다.
흔한 레거시의 특징이겠지만, 매장 테이블인데도 매장 정보와 직접적으로 관련 없는 컬럼들이 많이 들어가 있었습니다.
우선 도메인 전문가와 함께 이 컬럼들을 일차적으로 걸러내는 작업을 진행하였습니다.

그리고 추가로 예전에는 사용했던 컬럼이지만, 현재는 사용하지 않는 컬럼들도 존재하였습니다.
이 경우에는 운영환경 DB에서 데이터가 null인 건수와 백오피스 플랫폼에서 해당 컬럼에 대한 사용처들을 리스트업한 후 도메인 전문가와 함께 상의하여 걸러내는 작업을 진행하였습니다.

[필요한 테이블 식별]
이제 매장 관련 모든 테이블의 필요 컬럼이 식별됐으니, 다음 작업은 필요한 테이블을 식별하는 작업입니다.
주로 사용되는 DB 테이블이 있지만, 컬럼 한두 개를 제외하고는 거의 사용되지 않는 레거시 테이블도 존재했습니다.
저희는 이 레거시 테이블에 있는 필요 컬럼을 주로 사용되는 테이블로 이관하는 작업(테이블 통합) 을 3가지의 순서로 진행하였는데요.
필요한 컬럼을 식별하는 작업처럼 단순히 체크(?) 만 하는 것과는 달리, 해당 작업은 실제 DDL문과 DML문을 같이 실행합니다.
- 주로 사용되는 테이블에 이관해야 할 필요 컬럼을 추가 생성합니다. (ALTER)
- 백오피스 플랫폼에서 해당 데이터가 INSERT/UPDATE 되는 곳을 찾아서 통합하려는 테이블에도 데이터가 같이 반영되도록 수정하여 배포합니다.
- 레거시 테이블의 필요한 모든 컬럼 데이터를 주로 사용되는 테이블의 해당 컬럼으로 마이그레이션 합니다. (UPDATE)
- ※ Row Lock 주의 ※
그리고 추후 이 레거시 테이블의 기존 사용처들이 모두 저희 매장 서비스 API를 사용하도록 전환된다면, DROP 문을 통해 레거시 테이블과 깔끔한 작별 인사를 할 수 있습니다.
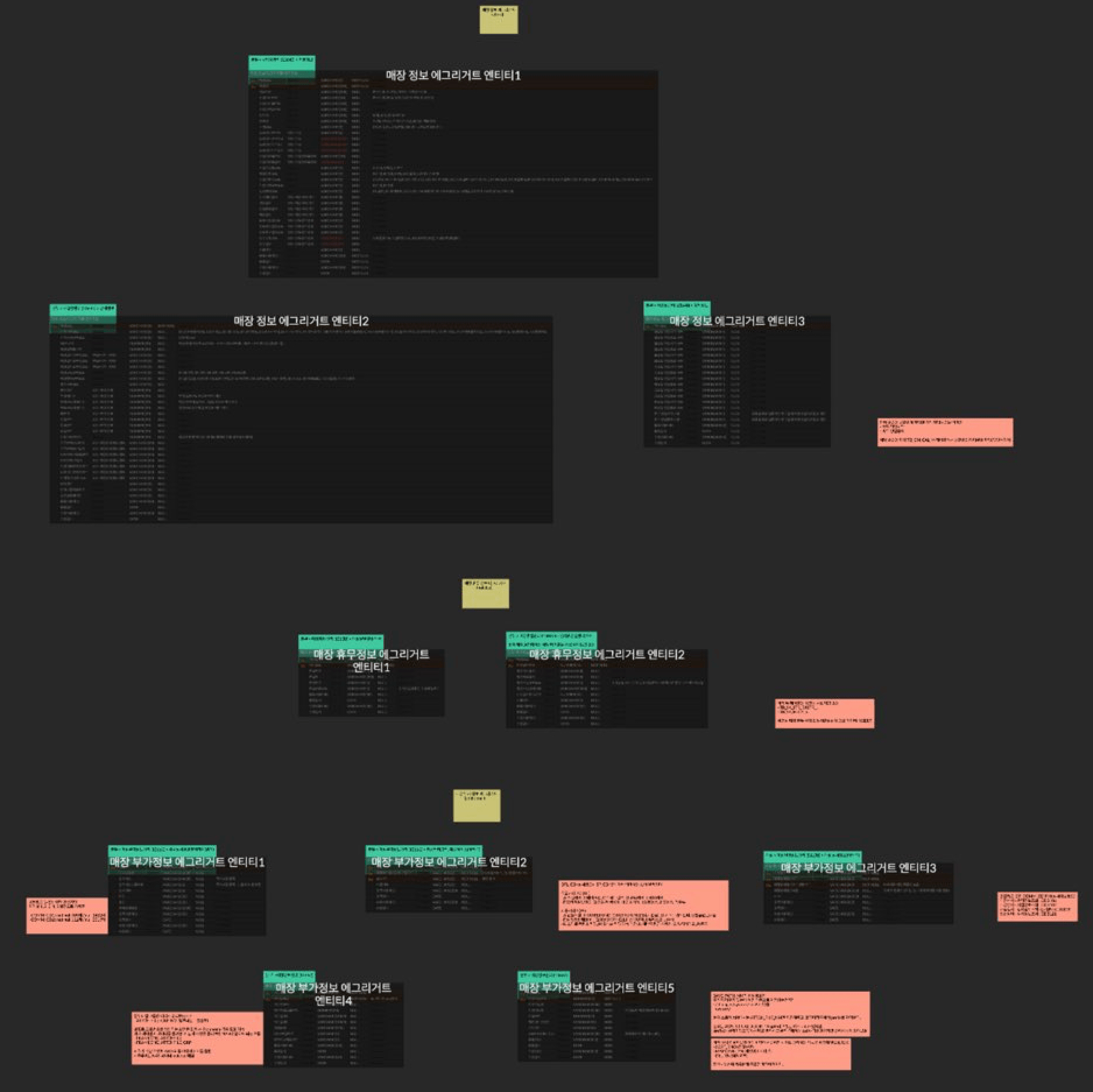
해당 사진은 위와 같은 작업들을 거치며 식별된 영역 중에 일부인 매장 정보에 대한 DB 테이블 목록입니다.
이처럼 테이블 경량화·통합 작업을 완료했다면, 실제로 매장 도메인에서 필요한 테이블과 컬럼들만 집중적으로 관리·사용할 수 있는 환경이 마련됩니다.
Entity와 VO
이제 본격적으로 도메인 모델을 구현할 차례입니다.
DDD의 전술적 설계에서, 도메인 모델은 크게 Entity와 Value Object로 구성합니다.
그리고 특정 군집에 포함되는 여러 Entity와 Value Object를 에그리거트(Aggregate)라고 정의합니다.
해당 군집을 대표하는 Entity를 에그리거트 루트(Aggregate Root) 혹은 루트 엔티티(Root Entity)라고 부릅니다.
이 애그리거트들이 모여서 하나의 바운디드 컨텍스트를 형성합니다.
예시를 간략하게 그려보면 아래와 같이 구성될 겁니다.
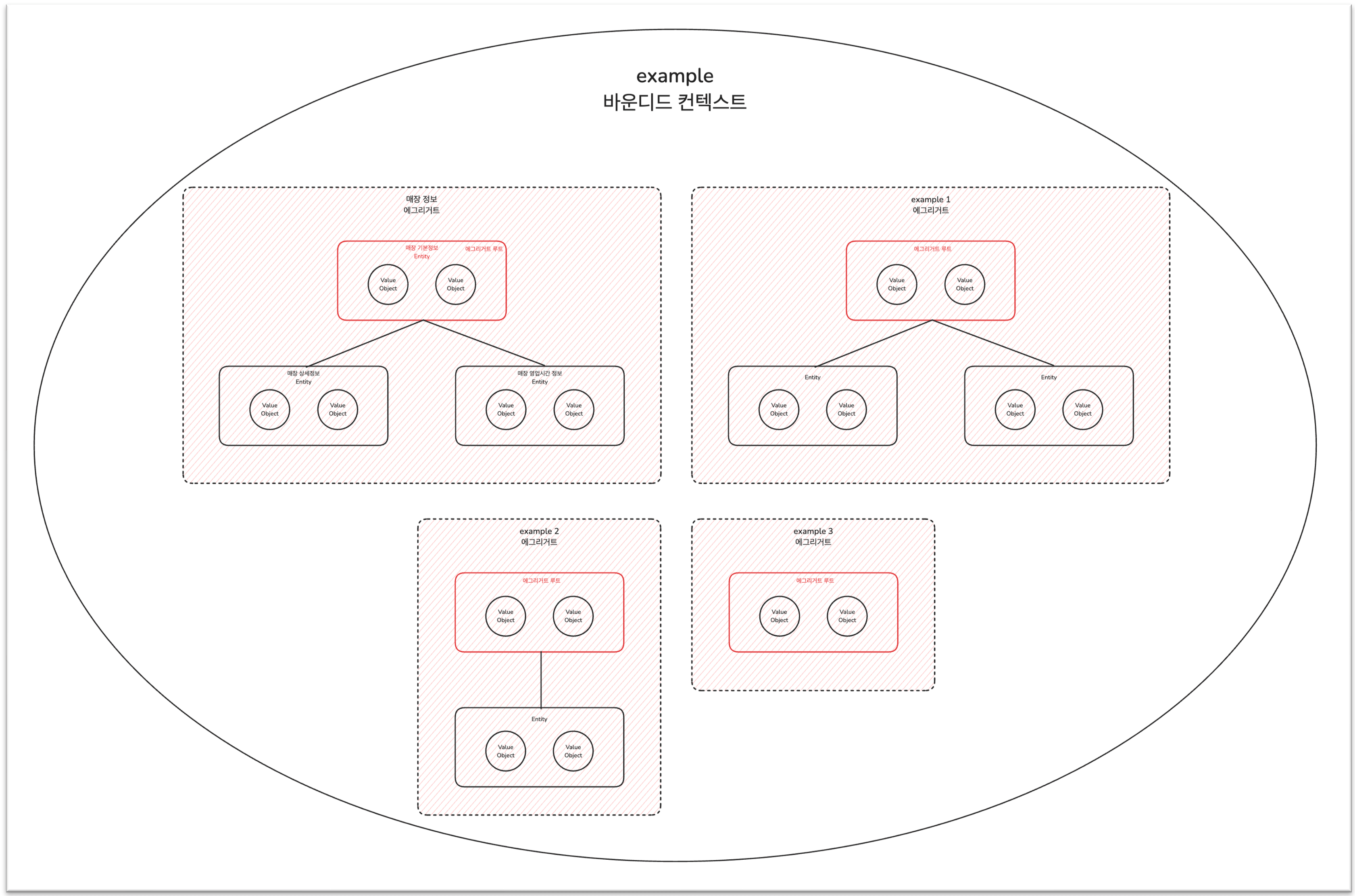
전술적 설계를 더 깊숙하게 들어간다면 아래처럼 굉장히 많은 개념과 전략들이 존재합니다.
- 에그리거트 루트를 통한 불변식 검증 응집
- 도메인 서비스를 통한 여러 에그리거트 간 협력
- 이벤트 기반 아키텍처를 통한 바운디드 컨텍스트 간 느슨한 결합 유지 및 시스템 확장성, 유연성 향상
- 이벤트 소싱을 통한 명확한 상태 변경 이력 추적
하지만 이번 포스팅에서는 Entity, Value Object에 대해서만 설명하고, 간략한 코드 스니펫(Code Snipet)을 통해 어떻게 구현했는지 소개해보려고 합니다.
[Entity]
우선 JPA 덕분에(?) 비교적 친숙한 Entity입니다.
Entity의 가장 큰 특징은 식별자를 가지는 것입니다.
이 식별자는 Entity 객체마다 고유하면서 바뀌지 않기 때문에 식별자만 같다면 두 엔티티는 같다고 판단합니다.
이런 특징을 이용해서 저는 아래와 같이 추상 클래스를 구현하였습니다.
public abstract class DomainEntity<T extends DomainEntity<T, TID>, TID> {
@Override
public boolean equals(Object other) {
if (other == null) {
return false;
}
if (!(other instanceof DomainEntity<?, ?> otherEntity)) {
return false;
}
if (getId() == null || otherEntity.getId() == null) {
return false;
}
return getId().equals(otherEntity.getId());
}
@Override
public int hashCode() {
return getId() == null ? 0 : getId().hashCode();
}
abstract public TID getId();
}DomainEntity 객체는 현재 딱 한 가지의 역할을 수행하고 있습니다.
바로 equals() & hashCode() 재정의를 통해 식별자(id)가 같다면 두 엔티티는 동등하다고 판단하는 역할을 충실히 수행합니다.
식별자(id)만 같고 나머지 모든 필드 값이 다르더라도, Entity는 동등하다고 판단합니다.
이제 Entity를 구현할 때, 해당 DomainEntity를 상속받는다면 자동으로 Entity 동등성 비교가 이루어질 것입니다.
또한, 해당 Entity가 동일한 트랜잭션 범위에서 JPA 영속성 컨텍스트에서 관리되고 있다면 동일성까지 보장될 겁니다.
class TestEntity extends DomainEntity<TestEntity, Long> {
private Long id;
private String name;
private String phone;
TestEntity(Long id, String name, String phone) {
this.id = id;
this.name = name;
this.phone = phone;
}
public Long getId() {
return id;
}
}DomainEntity를 상속받아 구현한 TestEntity에 대해 테스트 코드를 작성하고 실행한 결과는 아래와 같습니다.

[Value Object]
다음은 Value Object입니다.
줄여서 VO라고도 많이 불리는 이 객체는 개념적으로 완전히 하나를 표현할 때 주로 사용됩니다.
VO의 가장 큰 특징은 불변(immutable) 입니다.
즉 한번 값이 할당되면 변경될 수 없으므로, 값을 바꾸고 싶다면 아예 새로운 인스턴스를 생성해야 합니다.
객체가 불변이라면 자칫 사용하기 불편할 수도 있을 텐데 어떤 장점들이 있을까요?
우선, 참조 투명성이 보장되어 안전한 코드를 작성할 수 있습니다.
따라서 멀티 스레드에 안전하다는 특징도 가지고 있습니다.
또한, VO는 Entity와는 다르게 식별자(id)가 존재하지 않습니다.
따라서 VO는 모든 필드 값이 같아야만 동등하다고 판단하는 특징이 있습니다.
이런 특징들을 이용해서 저는 아래와 같이 추상 클래스를 구현하였습니다.
public abstract class ValueObject<T extends ValueObject<T>> {
@Override
public boolean equals(Object other) {
if (other == null) {
return false;
}
if (!(other instanceof ValueObject<?> otherValueObject)) {
return false;
}
return Arrays.equals(getEqualityFields(), otherValueObject.getEqualityFields());
}
@Override
public int hashCode() {
int hash = 17;
for (Object each : getEqualityFields()) {
hash = hash * 31 + (each == null ? 0 : each.hashCode());
}
return hash;
}
protected Object[] getEqualityFields() {
return Arrays.stream(getClass().getDeclaredFields())
.map(field -> {
try {
field.setAccessible(true);
return field.get(this);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
})
.toArray();
}
}ValueObject 객체도 마찬가지로 현재 딱 한 가지의 역할을 수행하고 있습니다.
equals() & hashCode() 재정의를 통해 모든 필드 값이 같다면 두 VO는 동등하다고 판단하는 역할을 충실히 수행합니다.
근데 여기서 getEqualityFields() 메서드가 의문이 들 수도 있을 겁니다.
DomainEntity 경우에는 제네릭을 통해 식별자(id)의 타입을 알고, getId() 메서드를 추상화함으로써 상속받는 Entity 객체는 항상 getId()를 구현할 수밖에 없습니다.
따라서 해당 getId() 메서드를 통해 추상 클래스에서 바로 equals() & hashCode()를 재정의할 수 있습니다.
하지만 ValueObject인 경우에는 동등성 비교 시 모든 필드 값을 알아야 하는데, 실제 VO를 구현하기 전까진 추상 클래스에서는 어떤 필드 값들이 있는지 확인할 방법이 없습니다.
따라서 Java의 Reflection API를 통해 선언된 필드 값을 가져와서 equals() & hashCode()를 재정의합니다.
이제 VO를 구현할 때 해당 ValueObject를 상속받는다면 자동으로 동등성 비교가 이루어질 것입니다.
class TestVO extends ValueObject<TestVO> {
private String name;
private String phone;
TestVO(String name, String phone) {
this.name = name;
this.phone = phone;
}
@Override
protected Object[] getEqualityFields() {
return new Object[]{name, phone};
}
}다만, 여기서 한 가지 특징이 있습니다.
ValueObject 추상클래스를 상속받아 구현한 실제 VO 객체에서도 getEqualityFields() 메서드를 한번 더 재정의해 주는 겁니다.
사실 Java Refelction API는 여러 가지 이유로 보통 사용을 지양합니다.
따라서 VO 객체를 구현할 때 정의한 필드를 그대로 getEqualityFields() 메서드에도 재정의해 준다면, Reflection API를 사용하지 않고도 동등성 비교를 할 수 있습니다.
ValueObject를 상속받아 구현한 TestVO에 대해 테스트 코드를 작성하고 실행한 결과는 아래와 같습니다.

다음 이야기
이번 글에서는 도메인 주도 설계에서의 전술적 설계를 간략하게 소개하였습니다.
도메인 모델을 구축하기 위한 스켈레톤 프로젝트 구축을 시작으로 테이블 경량화·통합 및 Entity와 VO까지 구현해보았습니다.
사실 전술적 설계에서는 정말 많은 개념과 전략들이 포함되어 있지만, 더 깊게 들어가기에는 이번 포스팅 주제와 맞지 않아 보여서 일부분만 소개해 드렸는데요.
더 자세한 부분은 오프라인 매장 서비스의 여정 시리즈를 마무리한 후에 별도로 포스팅해보겠습니다 😁
다음 포스팅에서는 HTTP API 설계를 시작으로 AWS, CI/CD, 모니터링 등 인프라 환경에 대한 내용을 소개하며, 본격적으로 매장 서비스를 오픈해 나가는 이야기를 해보려고 합니다.
긴 글 읽어주셔서 감사합니다 🙂
알렉스 로그
- 입사
- 매장 도메인
- 정산 도메인
- To be continued...