
안녕하세요. 풀필먼트 스쿼드에서 백엔드 개발을 담당하고 있는 시나브로우입니다.
저는 최근 공급망 관리(Supply Chain Management)를 통해 올리브영의 비즈니스 목표를 극대화하는 SCM 스쿼드에서 이적하였는데요.
이적 전인 2024년 3월부터 6개월 동안 진행한 OMS(Order Management System) 프로젝트에서 AWS MSK 를 통해 Kafka 를 구축한 사례와 트러블슈팅 경험을 여러분과 공유하려고 합니다.
실제로 모든 물류 데이터를 인터페이스하는 시스템에서 Kafka 를 통해 실시간으로 모든 데이터를 주고받을 수 있게 전면 개편하는 과정에서,
중복과 유실 없는 안정적인 메시지 송수신 구조를 만든 것이 이 프로젝트를 성공적으로 이끌었다고 생각하기에
메시지 중복과 유실 문제를 케이스별로 분석한 자료와 해결방법을 공유한다면 Kafka 메시지 중복 및 유실 방지에 관심있는 분들에게 분명 도움이 될 거라 판단하였기 때문입니다.
OMS 프로젝트는 올리브영의 SCM, 배송물류, 인벤토리 스쿼드뿐만 아니라, 외부 협력사인 대한통운과 CJ올리브네트웍스의 개발자들과 협력하여 WMS 및 WCS 시스템 개편과 함께 진행되었습니다.
이 프로젝트는 대한통운과 송수신하는 모든 물류 데이터를 인터페이스하는 시스템이며, Kafka 사용해서 모든 데이터를 실시간으로 주고 받을 수 있게 전면 개편되었습니다.
올리브영은 OMS 프로젝트에 3개 스쿼드 뿐만 아니라 계열사까지 참여하여 대규모로 협업한 끝에 2024년 8월 11일에 전면 오픈하였고 2024년 11월 현재까지 안정적으로 운영하고 있습니다.
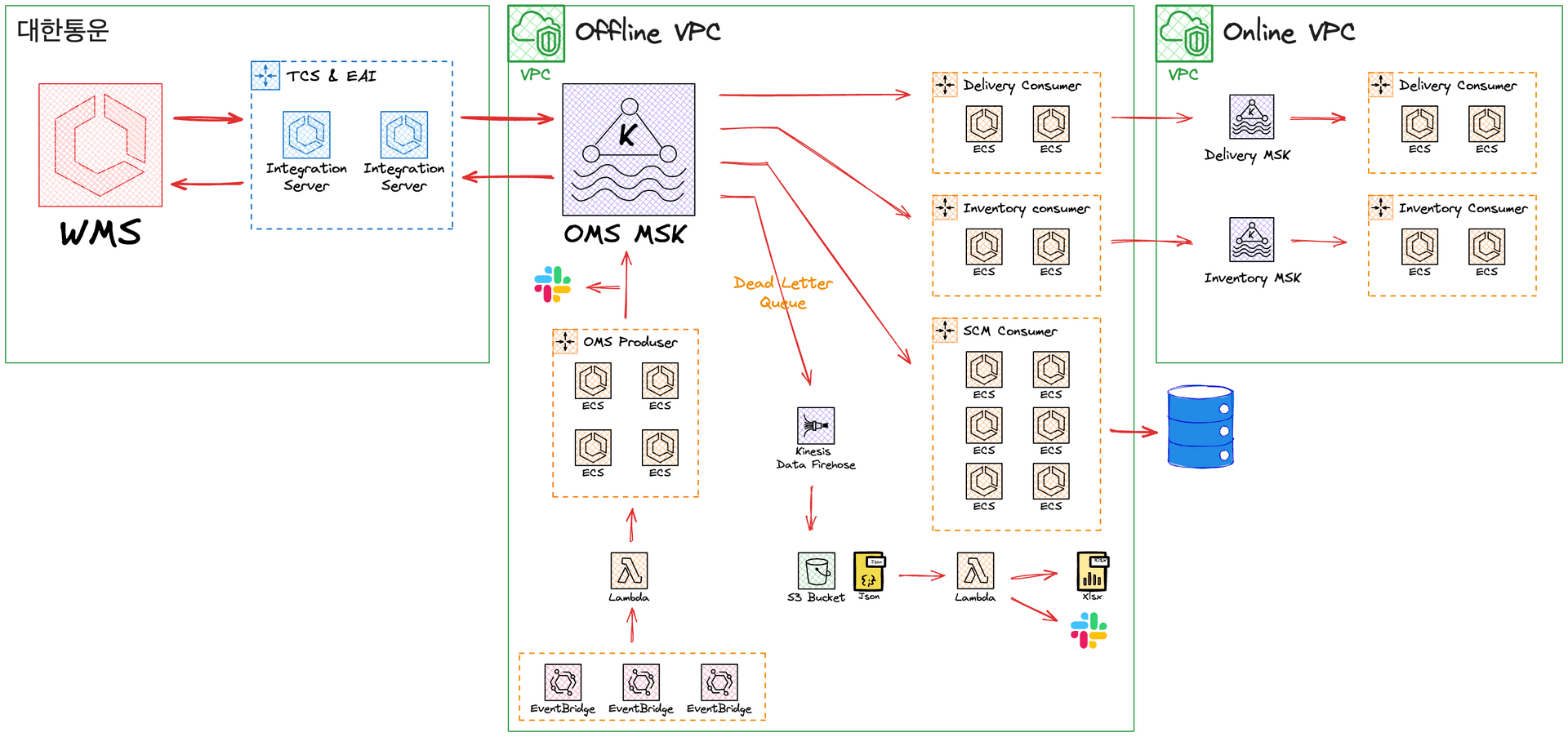
OMS 프로젝트에 SCM 스쿼드의 성과를 언급하자면, 기존 AS-IS WMS 연동은 EAI 와 Batch 를 사용하고 있었습니다.
SCM 스쿼드는 이를 전면 개편하여, 약 40 건의 EAI 와 Batch 를 제거하고 Kafka Topic 을 통해 데이터를 송수신할 수 있도록 변경했습니다.
개편을 통해서 SCM 스쿼드는 Kafka Topic 30 여 개와 DLQ 를 운영하고 있으며, 대량처리와 분산처리에 의해서 성능 또한 AS-IS 대비 처리량이 3배에서 최대 45배까지 증가했습니다.
성능 향상도 중요하지만 저는 OMS 프로젝트의 가장 큰 성공 요인이 중복과 유실 없는 안정적인 메시지 송수신 구조를 만든 것이라고 생각합니다.
본 글에서는 Kafka 를 사용했을 때 발생하는 메시지 중복과 유실 문제를 케이스별로 분석하고, 이를 해결하는 방법을 중심으로 다루겠습니다.
메시지 중복과 유실 방지
Kafka 공식 문서나 다른 정리 문서를 보면 Kafka 의 특징 중 하나가 'Exactly-once guarantees' 라는 것을 볼 수 있습니다.
저 문구가 Message Delivery Semantics 관점에서 많은 것을 내포합니다.
Kafka 설정으로 'Exactly once' 보장은 할 수 있지만, Default 설정은 'At least once' 입니다.
Message Delivery Semantics
* At most once - 일부 메시지가 유실될 수 있다. 유실된 메시지는 consumer 에 도달하지 못한다.
* At least once - 메시지가 절대 유실되지 않는다. 그러나 consumer 에서 동일 메시지를 두번 이상 처리할 수 있다.
* Exactly once - 모든 메시지 절대로 유실되지 않으며, consumer 는 반드시 한 번만 메시지를 처리한다.메시지가 유실과 중복 없이 정확히 한 번 처리하는 것을 원하지만 정확히 한 번만 처리할 수 있게 구현하는 것은 상당히 어려울 수 있습니다.
Exactly once 는 정확한 반드시 한 번만 메시지를 처리하는 가장 이상적인 메시지 처리 방식이지만, 설정이 복잡하고 난이도가 높습니다.
반면 At least once 는 상대적으로 간단하면서도 충분히 안정성을 제공하기 때문에 타협해서 사용할 수 있다. (Default 옵션)
(참고로 Kafka 3.x 버전 이후로 Exactly once 를 보장하는 옵션이 default 로 변경되고 있으며, Exactly once 를 보장할 수 있는 옵션이 추가되고 있습니다.)
SCM 스쿼드에서 진행한 OMS 프로젝트에서는 데이터 특성상 'At least once' 방식을 사용할 수 없었고, 반드시 'Exactly once' 를 보장해야 했기 때문에 Kafka 설정을 커스터마이징했습니다.
그럼 왜 메시지 중복과 유실이 발생하는지 구간별로 살펴보고, 어떻게 해결했는지 살펴보겠습니다.
중복과 유실이 발생하는 대표적인 구간
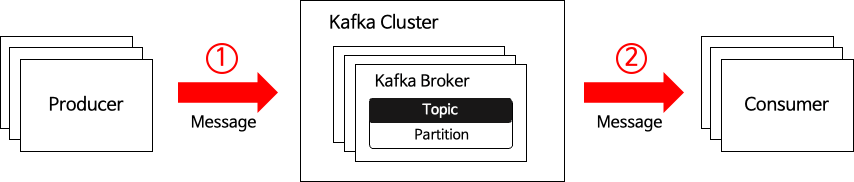
- Producer 와 Broker 간 네트워크 통신 구간
- Producer 와 Broker 간 네트워크 장애가 발생하여, Producer 는 Broker 로 메시지를 보내지 못할 경우 메시지 유실이 발생합니다.
- 해당 케이스를 해결하기 위해서 Producer 에 acks 옵션을 all 로 지정하고 retries 횟수 지정하여 메시지 유실을 막을 수 있었습니다.
acks option
acks 옵션이란? Producer 가 Broker 에 메시지를 전송한 후 요청 완료를 결정하는 옵션입니다.acks=0
- acks=0 으로 설정되면 Producer는 Broker 로부터 어떠한 응답(Ack)도 기다리지 않습니다.
- 즉, Broker 단에 제대로 전달되었는지 확인하지 않습니다.
- Producing 을 하면 저장이 성공한 것으로 즉시 처리합니다.
- 메시지 손실이 다소 있더라도 빠르게 메시지를 보내야 하는 경우에 사용됩니다.
acks=1
- acks=1 으로 설정되면 Producer는 Broker Leader 의 응답 확인(Ack)만 기다립니다.
- 즉, Broker 의 Ack 만으로 전송 완료 처리합니다.
- 이 경우 리더가 메시지를 Ack를 보낸 후, Follower가 복제하기 전에 Leader 에 장애가 발생하면 메시지가 손실됩니다.
- At most once(최대 한 번) 전송을 보장합니다.
- Kafka 2.8 까지는 acks=1 이 default 입니다.
acks=all (-1)
- acks=all 으로 설정되면 Producer는 Broker Leader 와 Follower 모든 응답 확인(Ack)을 기다립니다.
- 적어도 하나의 동기화된 Follower 이 살아 있는 한 메시지가 손실되지 않을 것임을 보장합니다.
- 가장 강력한 보장 방식이며, At least once(최소 한 번) 전송을 보장합니다.
- 다만, 모든 Follower 의 응답 확인을 받아야해서 다소 느릴 수 있습니다.
- Kafka 3.0 이후로 acks=all 이 default 입니다.
- Broker 가 메시지를 받아서 저장 했지만, 저장 성공 응답(Ack)을 Producer 에 보내지 못해서 한번 더 메시지 (retry)를 전달하는 경우 메시지 중복 Producing 이 발생합니다.
- 해당 케이스를 해결하기 위해서 Producer 에 acks=all, enable.idempotence=true 옵션을 설정하여, 메시지 중복 Producing 을 방지할 수 있었습니다.
max.in.flight.requests.per.connection 는 5 이하여야하고 retries 는 1이상으로 설정해야합니다.
enable.idempotence=true 로 적용되면 중복으로 메시지를 Producing 하는 경우가 없어집니다.
네트워크 오류로 인한 retry 시도로 중복 메시지가 발송될 경우, 메시지의 Produce ID 와 시퀀스 번호를 확인하여 한번만 저장되도록 처리합니다.
(Kafka 3.0 이후 부터는 enable.idempotence=true, acks=all 이 기본 옵션으로 설정되어있습니다.
Kafka 3.0 이후 버전을 사용하시는 경우에는 멱등성 보장과 관련된 옵션에 크게 신경 쓰지 않아도 되지만,
Kafka 2.x 대 버전을 사용 중이라면 직접 메시지 유실과 메시지 중복을 방지하기 위해서 멱등성 옵션을 사용하는 것을 권장합니다.)
- Consumer 와 Broker 간 네트워크 통신 구간
- Consumer 서버 재기동 시 재기동 사이에 Broker 에 메시지가 적재될 경우 메시지 유실이 발생합니다.
- 해당 케이스를 해결하기 위해서 Consumer 에 auto.offset.reset=earliest (default 가 latest), spring.kafka.listener.immediate-stop=false (Graceful Shutdown) 옵션을 설정하여, Consume 메시지 유실을 방지할 수 있었습니다.
- Consumer 가 메시지 처리 완료 정보(Ack)를 Broker 에 정상적으로 전달되지 않아, 동일한 메시지를 두 번 이상 Consume 하여 중복 메시지 Consume 이 발생합니다.
- 해당 케이스를 해결하기 위해서 Consumer 에 AcksMode=MANUAL_IMMEDIATE, spring.kafka.listener.immediate-stop=false (Graceful Shutdown) 옵션을 설정하여 메시지 중복 Consume 을 방지할 수 있습니다.
AcksMode
AcknowledgingMessageListener 또는 BatchAcknowledgingMessageListener 를 Interface 를 사용하는 경우 사용 가능한 옵션- MANUAL - Acknowledgement.acknowledge() 메서드가 호출되면 다음번 poll() 때 커밋을 한다.
- MANUAL_IMMEDIATE - Acknowledgement.acknowledge() 메서드를 호출한 즉시 커밋한다.
특정 토픽을 Consume 하는 과정에서 AcksMode=MANUAL 옵션이 세팅된 상태에서 Consume 로직 수행 시간이 max.poll.interval.ms 에 지정한 10분을 초과하는 문제가 발생했습니다.
max.poll.interval.ms 초과하고 Offset Commit 실패하여 Consumer Rebalancing -> Partition 재할당 -> 중복 Consume 후 Offset Commit 하는 문제가 있었습니다.
Offset Commit 실패 시 로그
Caused by: org.apache.kafka.clients.consumer.CommitFailedException: Offset commit cannot be completed since the consumer is not part of an active group for auto partition assignment; it is likely that the consumer was kicked out of the group.at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.sendOffsetCommitRequest(ConsumerCoordinator.java:1180)
- Consumer Rebalancing 이전에 정상적으로 마지막 메시지가 Ack 되지않아서, Consumer Rebalancing 이후에 동일한 메시지를 두 번 이상 Consume 하는 경우 중복 메시지 Consume 이 발생합니다.
- 해당 케이스를 해결하기 위해서 2.8 버전 release note 를 살펴볼 필요가 있습니다.
KAFKA-13636 에 언급되어있는 것 처럼 Rebalancing 지연과 Rebalancing 이전 Commit 보장 방식으로 해당 케이스 버그가 수정되었습니다.
버전을 2.8 이상으로 올려서 사용하시면 해당 이슈를 쉽게 해결할 수 있습니다.
그 외에도 session.timeout.ms, heartbeat.interval.ms, max.poll.interval.ms 설정값을 조정해서 Consumer Rebalancing 가능성을 감소시킬 수 있습니다.
https://repost.aws/ko/knowledge-center/msk-consumer-group-rebalance 링크
Kafka 고가용성 보장과 MSK 보안성 패치 이슈
Kafka cluster 에서 고가용성을 보장할 수 있는 3 가지 요소를 뽑아봤습니다.
High Availability Guarantee Factors
- Broker 다중화 (Multi-AZ) - 특정 Broker 가 다운되더라도 다른 Broker 가 그 역할을 대신할 수 있어 메시지 처리가 계속 유지됩니다.
- Replication Factor - Leader Broker 가 장애를 일으키면 Follower 중 하나가 새로운 Leader 로 승격되어 데이터 손실 없이 메시지 처리를 계속할 수 있습니다.
- Min In-Sync Replicas - 메시지가 성공적으로 기록되기 위해 최소한 몇 개의 Replicas 가 동기화되어 있어야 하는지 관한 설정.
MSK 보안성 패치 이슈
Kafka Broker 와 Kafka Consumer 에서 위의 설정을 통해서 고가용성을 보장할 수 있는데요.
위에 언급한 Multi-AZ, Replication Factor, Min In-Sync Replicas 속성들은 MSK 를 사용할 때 특히나 중요합니다.
MSK 는 한달에 한번 브로커의 보안패치가 있는데, 보안패치 시 브로커 한대씩 재부팅 됩니다.
보안성 패치 시간이 4시간 정도 발생하기 때문에 해당 시간 동안에 메시지 유실이 없도록 방지해야합니다.

보안성 패치 시간 동안 Consumer 서버에서는 다음과 같은 경고 메시지가 발생합니다.
OMS 프로젝트에 설정한 MSK 보안성 패치 대비 메시지 유실 방지 설정은 다음과 같습니다.
MSK Broker 는 3개로 생성되어 있으며, Broker 가 3개에 맞춰 Consumer 의 Replication Factor 를 3 으로 설정하고, Broker 의 min.insync.replicas 를 2 로 설정했습니다.
Replication Factor 설정을 통해 각 Broker 에 Topic 의 Partition replica 가 생성되도록 구성했으며,
min.insync.replicas 값은 "Set minimum in-sync replicas (minISR) to at most RF - 1 to ensure the partition replica set can tolerate one replica being offline or under-replicated" 가이드에 따라 2 로 설정했습니다.
min.insync.replicas=2 로 설정하면, 메시지가 정상적으로 기록되기 위해 최소 2개의 Replicas 가 동기화되어야 성공 응답(ack)을 반환합니다.
acks=all 로 설정하면, Producer 가 Broker Leader 와 Follower 모든 응답 확인(Ack)을 기다립니다.
즉, min.insync.replicas=2, acks=all 같이 설정하여, 최소 2개의 Replicas 에 메시지가 기록되어야만 Producer 에게 성공 응답(ack)을 반환합니다.
Partition Assignment Strategy
Kafka 의 분산처리, 대용량처리를 효과적으로 하기위해서 적절한 파티션 할당 전략을 선택해야합니다.
| Strategy | Contents |
|---|---|
| RangeAssignor Strategy |
default 로 설정된 파티션 할당 전략입니다. 토픽의 전체 파티션 수를 컨슈머 그룹의 총 컨슈머 수로 나눈 값이 일치하는 경우 균등하게 할당. 이후 나머지 파티션은 컨슈머에게 순서대로 추가로 할당합니다. |
| RoundRobin Strategy | 가장 간단한 파티션 할당 전략으로 파티션을 컨슈머 그룹 내 모든 컨슈머에게 균등하게 할당합니다. |
| Sticky Strategy | Rebalancing 이 발생하더라도 기존 매핑 정보를 최대한 유지하는 컨슈머 파티션 할당 전략입니다. |
| CooperativeSticky Strategy |
Apache Kafka 2.4.0에서 도입된 새로운 할당 전략으로, Sticky 전략과 비슷하지만 부분적인 Rebalancing 을 지원합니다. CooperativeSticky는 partition 할당을 가능한 한 안정적으로 유지하고, Consumer 가 처리하고 있던 파티션이 Rebalancing 중에도 이동하지 않도록 합니다. Rebalancing 시에 기존 Partition 할당을 최대한 유지한 채로 필요한 부분만 revoke 후 최소한의 Partition 재할당만 가능하게 하는 전략입니다. |
Kafka 의 default Partition Assignment Strategy 는 "RangeAssignor" 이지만, Kafka 3.0 버전 이후로 "RangeAssignor, CooperativeStickAssignor"로 변경되었고 기본적으로 RangeAssignor를 사용하지만 싱글노드씩 롤링 업그레이드할 때에는 CooperativeStickyAssignor 가 사용됩니다.

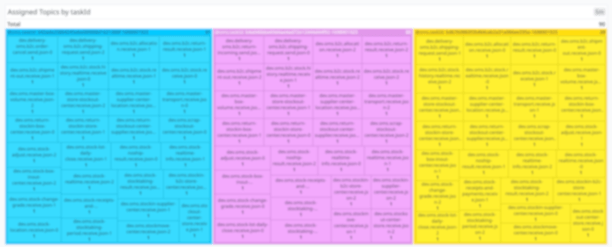
위의 그림처럼, 개발 서버에서 적용한 RangeAssignor Strategy 과 CooperativeSticky Strategy 전략을 비교해보았습니다.
RangeAssignor Strategy 전략의 경우, AWS ECS Task 3 곳에 고르지않게 다소 편중되어 Partition 이 할당되었습니다. 또한 배포할 때마다 ECS Task 에 Partition 이 불규칙하게 뒤섞여 할당되는 문제가 발생했습니다.
반면, CooperativeSticky Strategy 전략의 경우, 그림과 같이 배포 이전과 배포 후에 Partition 고르게 할당 되는 것을 볼 수 있습니다.
Partition 고르게 할당되어야 ECS Task의 Consumer Listener 들이 효율적으로 메시지를 Consume 할 수 있습니다.
즉, 분산 처리 환경에서 메시지를 효율적으로 처리하기 위해서는 적절한 파티션 할당 전략을 선택하는 것이 중요하며,
여러 전략을 사용해본 결과 CooperativeSticky Strategy 전략이 OMS 프로젝트에서는 가장 효과적이었습니다.
DLQ 자동 백업 시스템 구축
SCM 스쿼드에서는 Kafka 오류 데이터를 관리하기 위해 DLQ(Dead Letter Queue) 패턴을 사용하고 있습니다.
SQLException, JDBCException, PersistenceException, NullPointerException, NumberFormatException 와 같은 데이터 오류, 데이터 타입 불일치, PK 중복 등 에러가 발생할 때 DLQ 오류 데이터를 적재합니다.
OMS 에서 사용 중인 DLQ 보관 주기는 3일이며, DLQ 데이터를 확인하고 재처리하기 위해서 정적파일로 관리할 필요가 있었습니다.
이러한 사유로 SCM 스쿼드에서는 AWS Kinesis Data Firehose, S3, Lamda 를 사용하여 DLQ 데이터 자동 백업 플로우를 구축하여 사용하고 있습니다.
DLQ 의 데이터는 AWS Kinesis Data Firehose 통해서 준실시간 자동으로 S3 로 백업 되며, Lamda 를 통해서 Excel 파일로 생성되어 관리하고 있습니다.
AWS Kinesis Data Firehose 는 준실시간(Near Real-Time) 기반의 스트림(Stream) 처리 서비스로, MSK 에 생성되어있는 Topic 단위로 Stream 을 생성합니다.
OMS 시스템의 경우 Firehose 를 이용하여 MSK 에 적재된 DLQ 데이터를 준실시간으로 캡처하여 S3에 백업하고 있습니다.
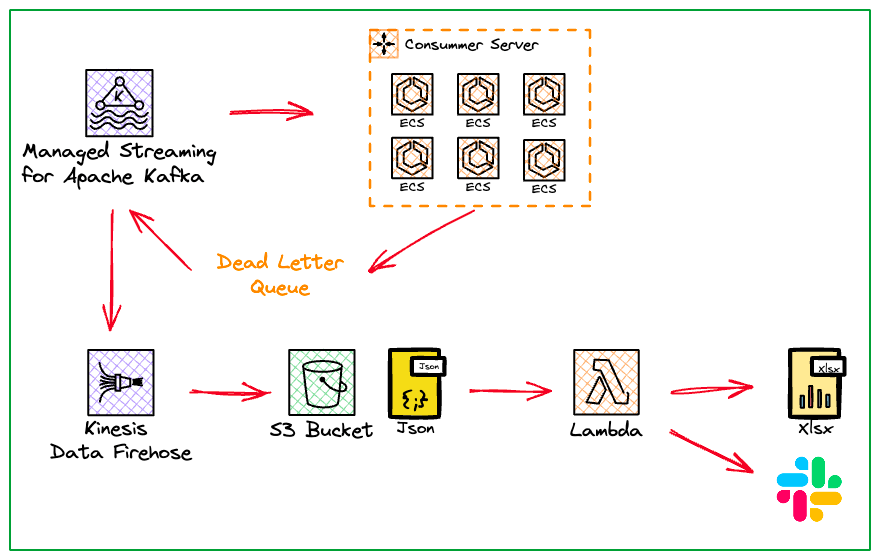
DLQ 데이터 자동 백업 플로우 스텝은 다음과 같습니다.
- DLQ 데이터 적재
- AWS Kinesis Data Firehose 데이터 캡쳐
- S3 에 Json 파일로 저장
- AWS Lambda 함수로 Json 파일을 Xlsx 파일로 변환
- 백업 성공 시 SNS 호출
- Slack 을 통해 DLQ 적재 및 백업 상태 알람
AWS Kinesis Data Firehose 에서 지원해주는 옵션은 다음과 같습니다.
AWS Kinesis Data Firehose 에서 지원해주는 옵션
S3 압축 타입- GZIP, Snappy, Zip, Snappy
Amazon S3 로의 데이터 전송이 트리거 조건
- buffer size: 1 MiB ~ 128 MiB
- buffer time: 60~900 seconds
OMS 프로젝트에서 AWS Kinesis Data Firehose 옵션을 최적화해서 사용하고 있습니다.
- S3 압축타입: GZIP
- 포맷타입: json
- buffer size: 5MiB (5.24288MB)
- buffer time: 300 seconds
옵션에서 볼 수 있듯이, OMS MSK 에서는 DLQ Topic 을 대상으로 5분간격 또는 5MiB 버퍼 간격으로 GZIP 압축하여 S3 로 백업합니다.
이러한 백업 플로우를 통해서 OMS DLQ 데이터를 안전하게 백업하고 있습니다.
끝으로
지금까지 올리브영 SCM 스쿼드의 WMS 인터페이스 개편과 Kafka 메시지 중복&유실 방지 방법을 소개하였습니다.
아직 사내에서도 OMS 프로젝트를 잘 모르고 계시는 분들과 Kafka 메시지 중복&유실 방지에 관심이 있는 분들을 위해 이 글을 작성했습니다.
글이 점점 더 길어지는 것 같네요. 독자들께 많은 도움이 되기를 바라면서 글을 마무리하겠습니다.
다음 글에서는 풀필먼트 스쿼드에서 진행한 프로젝트를 주제로 다룰 예정입니다.
이전 글도 많이 읽어주세요. AWS MSK Connect 효과적으로 운영하기
마지막으로 제가 소속된 인벤토리서비스개발팀의 풀필먼트 스쿼드와 함께 물류 시스템을 구축하고 싶은 분은 채용 공고를 꼭 확인해주세요!
현재 활발하게 채용 중이니, 지금 바로 지원해 보세요!
지금까지 올리브영 풀필먼트 스쿼드의 시나브로우였습니다.
감사합니다.
