
안녕하세요. 인벤토리 스쿼드 백엔드 개발자 펭귄대장입니다!
인벤토리 스쿼드에서 재고 변경 이력을 관리하기 위해 OpenSearch + EFK 를 구축하게 되어 소개 드립니다.
이전 포스팅에서 자주 언급되었듯이, 올리브영은 Datadog 을 사용하여 올리브영의 온오프라인 서비스를 모니터링 하고 있습니다.
이미 로그 확인과 서비스 모니터링을 위해 Datadog 을 사용 중인데,
왜 재고만을 위해 별도로 OpenSearch + EFK 기반의 로그 시스템을 구축하게 되었을까요?

올리브영의 재고는 입고, 점간 이동, 주문, 반품, 감모, 자소 등 30개 이상의 이벤트 타입이 존재하며,
당일 매장별 상품(SKU)의 기초 재고 데이터 생성을 시작으로, 전체 SKU 기준으로 하루 최소 천만번 이상의 재고 변경이 발생합니다.
또한 오늘드림 서비스, 구매 가능 매장 안내 등에서 사용자의 일관된 경험 제공 및 사용자 경험의 만족도를 높이기 위해
재고의 정합성을 확보하는 것이 중요하며 이를 위한 재고 변경 이력 관리 및 용이한 추적이 필요했습니다.
마지막으로 재고 API 를 사용하는 도메인과 서비스가 늘어나고 있으며 확장 가능성을 위해 OpenSearch EFK 를 구축하게 되었습니다.
정리하면 아래와 같은 이점이 있습니다.
- 커스터마이징 가능성: OpenSearch EFK를 사용하면 개발자가 로그 및 이력 데이터를 자유롭게 구성하고 분석할 수 있습니다.
따라서 특정 요구 사항에 맞게 로그 데이터를 유연하게 처리할 수 있습니다. - 비용 효율성: OpenSearch의 Index Lifecycle Management을 활용하여 로그 데이터의 수명주기를 관리하고 비용을 절감할 수 있습니다.
필요에 따라 데이터를 자동으로 삭제하거나 아카이빙하여 비용을 최적화할 수 있습니다. - Rest API 지원: OpenSearch는 Rest API를 지원하므로 로그 데이터의 적재뿐만 아니라 조회 및 분석에도 유연하게 활용할 수 있습니다.
변경 이력을 조회하는 API 서비스를 제공하는 등의 확장이 가능합니다.
그럼 이제부터 OpenSearch 와 EFK 가 무엇인지, 어떤 특징이 있는지 간단히 알아보겠습니다.
EFK Stack
EFK 는 아래 기술들의 앞 글자를 합친 말로 로그 및 이벤트 관리를 위한 기술 스택을 칭합니다.
ElasticSearch/OpenSearch: 데이터 인덱싱/저장/분석/검색
Fluentd/FluentBit: 데이터 수집/변환 및 OpenSearch로 전송
Kibana: 데이터 시각화 대시보드
OpenSearch
ElasticSearch 에서 2021년 1월 이후 OpenSource 정책을 폐기함에 따라,
Amazon 에서 ElasticSearch v7.1을 fork 하여 만든 AWS 의 PaaS 서비스입니다.
ElasticSearch(OpenSearch)의 특징
- 실시간 분석 (real-time): 데이터가 입력(indexing)되고 그와 동시에 near real-time 속도로 색인 된 데이터의 검색, 집계 가능
- 전문 검색 엔진 (full text): 루씬 기반으로, 역 파일 색인(역 인덱스) 구조로 데이터를 저장하여 전문 검색이 가능
- RestFul API: Rest API http 프로토콜 CRUD 지원
- multitenancy: 데이터들을 인덱스라는 논리적인 집합 단위로 구성하여 서로 다른 저장소에 분산 저장.
서로 다른 인덱스들을 별도 커넥션 없이 하나의 질의로 묶어서 검색/출력 가능
Inverted Index(역인덱스)
RDBMS 에서 아래와 같은 테이블 구조로 저장되어 있을 때,
Text 에 "best" 가 포함된 행을 가져오려면 Text 열을 하나씩 찾아 내려가면서 row 내용까지 모두 읽어가며 키워드를 찾아야 합니다.
| ID | Text |
|---|---|
| doc1 | Oliveyoung |
| doc2 | Oliveyoung is better |
| doc3 | Oliveyoung is the best |
반면, Elasticsearch(OpenSearch) 는 데이터를 저장할 때 아래와 같이 역인덱스 구조로 만들어 저장하여,
키워드를 포함하고 있는 document ID 를 바로 얻어올 수 있습니다.
| Term | Id |
|---|---|
| Oliveyoung | doc1, doc2, doc3 |
| is | doc2, doc3 |
| the | doc3 |
| best | doc3 |
| better | doc2 |
RDBMS와 ElasticSearch(OpenSearch) 용어 차이
| RDBMS | OpenSearch |
|---|---|
| Database | Index |
| schema | mapping |
| table | type |
| Column | Field |
| Row | Document |
FluentBit/Fluentd
FluentBit/Fluentd 모두 오픈소스 로그 데이터 수집기로,
FluentBit은 Fluentd에 비해 메모리 사용량이 적고 가볍다는 특징이 있습니다.
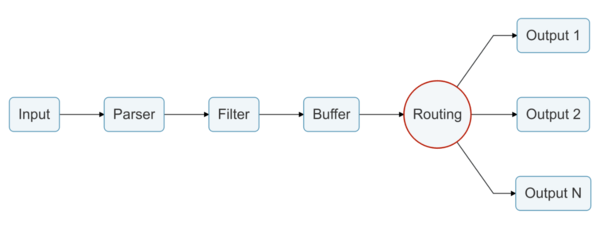
FluentBit pipeline
FluentBit은 INPUT 섹션에 리스닝 할 포트 혹은 기준이 될 로그 파일을 지정하고
Filter 로 문자열을 필터링하고 정제하여
OUTPUT으로 목적지에 전송하는 아래와 같은 파이프라인으로 동작합니다.
(Routing 은 INPUT 태그에서 선언한 Tag 를 기준으로 동작합니다)
Fargate 에서 firelens sidecar pattern을 사용하여 EFK 구축하기
올리브영에서 모던아키텍처라 불리는 AWS ECS 기반 API 서버들은 fargate 로 동작하며, 모니터링으로 Datadog를 사용하고 있습니다.
datadog agent container는 jvm metric을 전송하기 위함이며,
그 외 서버 로그들은 firelens(plugin) sidecar pattern 을 사용하여 fluentbit container를 통해 Datadog 서버에 적재하고 있습니다.
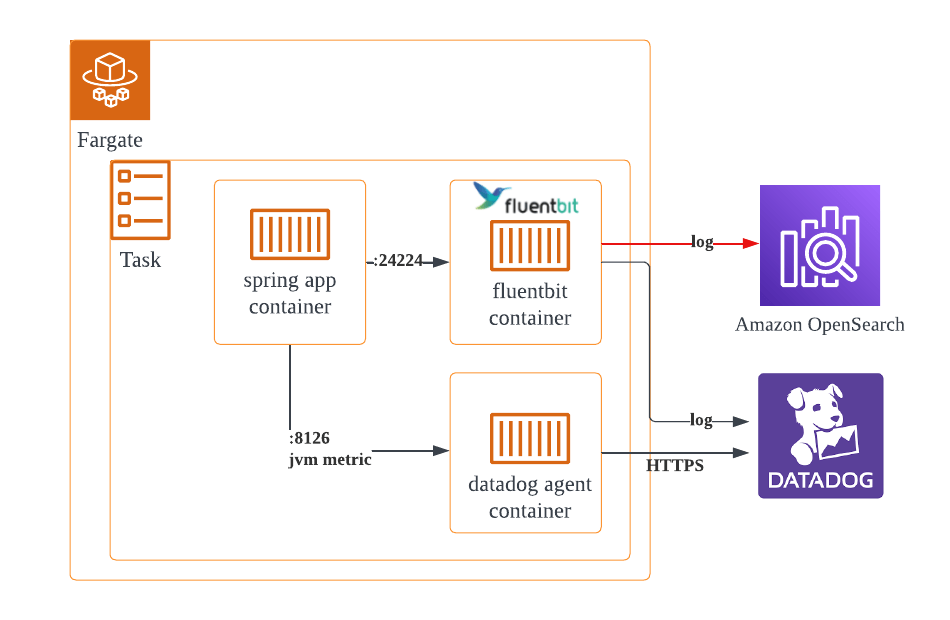
위 그림의 빨간 선을 추가하여,
fluentbit container 에서 앱 컨테이너의 로그 중 재고 변경과 관련된 특정 로그만 라우팅하여 opensearch 로 전송하도록 설정하는 게 목표입니다.
아래와 같은 순서로 진행하겠습니다.
- OpenSearch 구성
- 로그 라우팅을 위한 app container 수정
- fluentbit custom docker image 생성 및 푸시
- fluentbit container 추가를 위한 ecs fargate 설정 수정
- 테스트 및 결과 확인
첫 번째 순서로 opensearch 를 구성합니다.
AWS OpenSearch 구성
OpenSearch 도메인 생성
도메인 생성 과정에서 세분화된 액세스 제어(보안) 관련 설정만 간단하게 살펴보고 나머지는 생략하겠습니다.
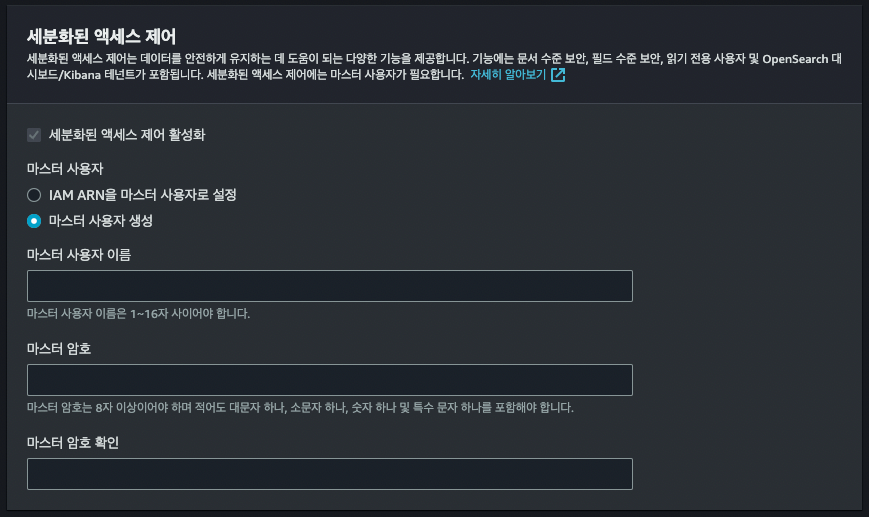
cognito / IAM 등을 사용한 유저 및 권한 관리도 가능하나, 마스터 사용자 생성을 기준으로 설명하겠습니다.
마스터 사용자 옵션을 사용할 경우 OpenSearch 내장 DB 의 master 유저를 생성하여 사용하게 됩니다.
이때 생성한 master user 는 index 관리, 유저 권한 관리 등 OpenSearch 의 모든 권한을 갖습니다.

OpenSearch 도메인 생성이 끝난 콘솔의 모습입니다.
OpenSearch Index 설정
OpenSearch 파라미터 타입 매핑을 위한 OpenSearch Template 을 생성해 줍니다.
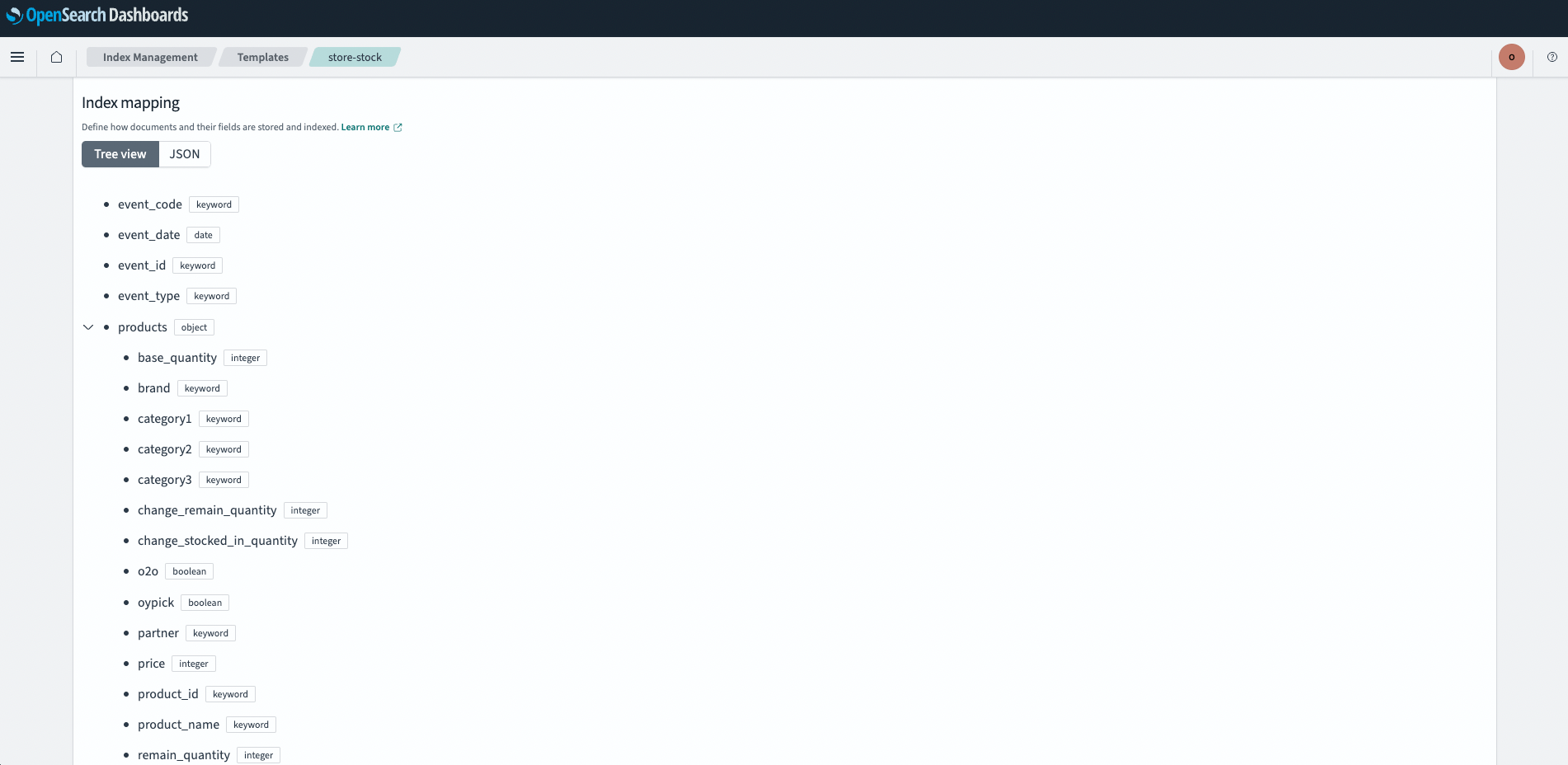
문자 형태의 Data type은 크게 keyword 와 text 가 있으며 아래와 같은 차이점이 있습니다.
- keyword: 메트릭 지표 및 facet 으로 사용하기 위한 경우 사용
- text: 검색엔진에서 사용하기 위한 역인덱스 생성이 필요한 경우 사용
index 를 index-%Y%m%d 와 같이 날짜별로 생성할 것이므로 index pattern 은 index-* 형태로 지정합니다.
OpenSearch ISM(Index Statement Management) 설정
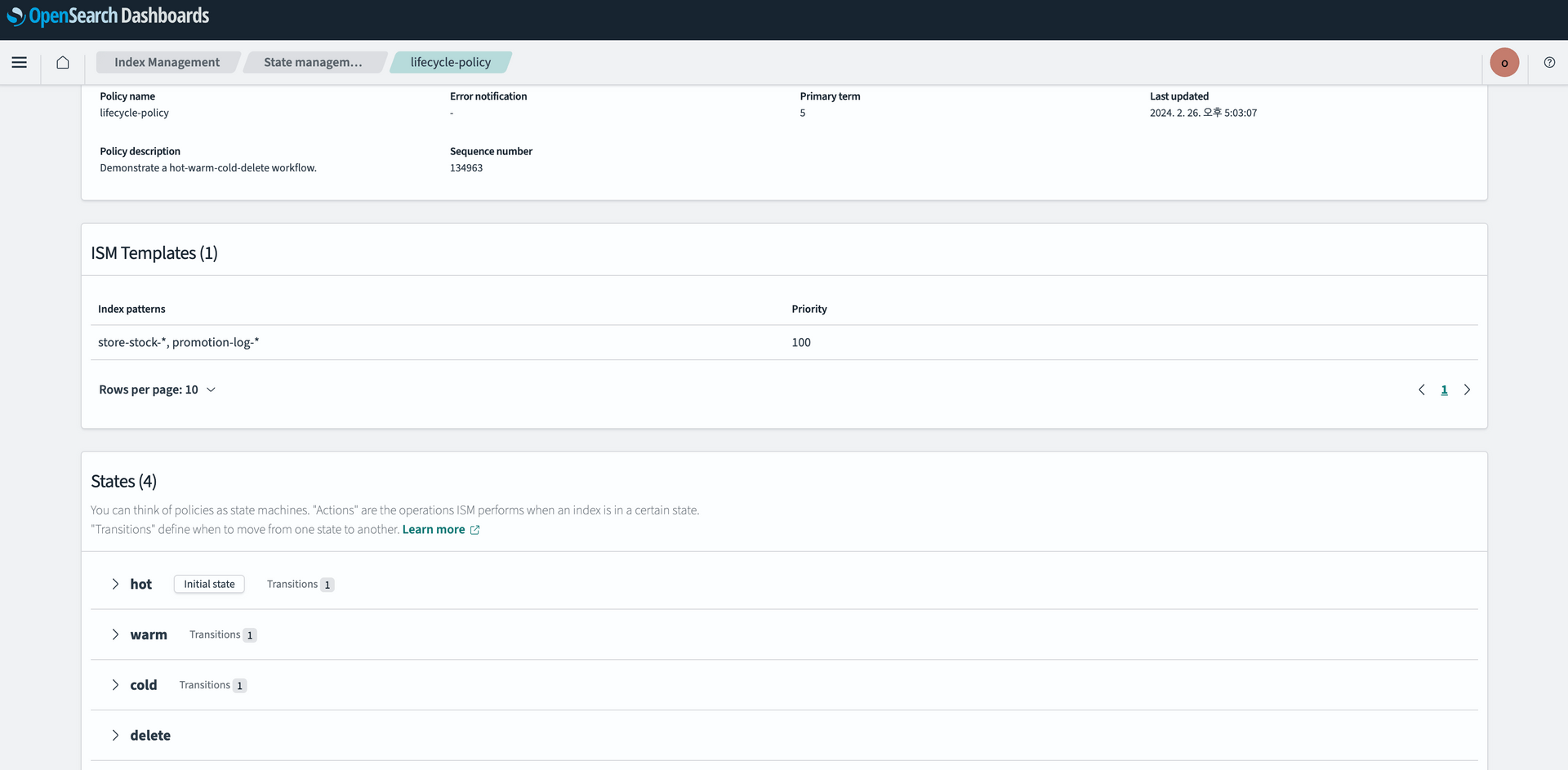
Index LifeCycle 을 설정합니다.
관련된 자세한 내용은 링크를 참고해 주세요.
OpenSearch User 및 Role 설정
fluentbit container 에서 도메인 생성 과정에서 생성한 master user 를 사용해도 되지만
master user 는 모든 권한을 갖고 있으므로, 데이터 적재에 필요한 권한만 가지고 있는 유저를 생성하여 fluentbit container 에서 사용하도록 합니다.
계정 생성이 완료되었으면, 생성한 계정에 fluent bit container 에서 OpenSearch 로 OUTPUT 하기 위해 필요한 권한을 추가해 줍니다.
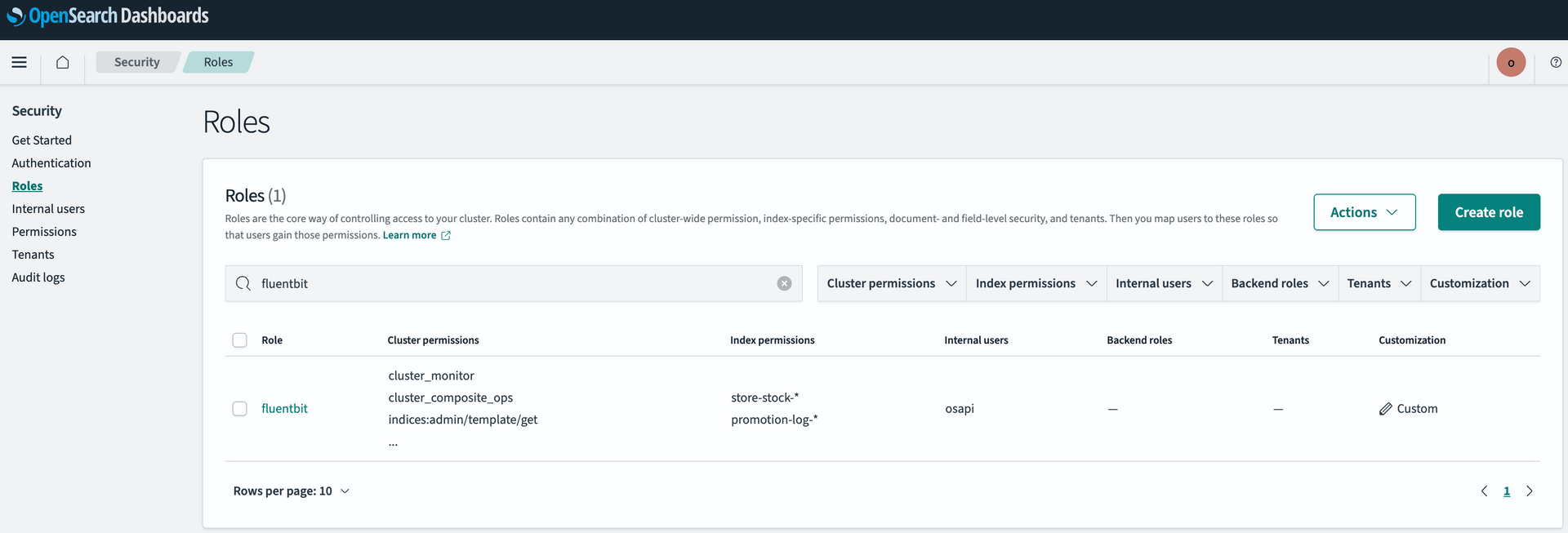
fluentbit 이 OpenSearch 로 OUTPUT 할 때, fluentbit 이 bulk api 를 사용하므로 indices:data/write/bulk 권한은 필수입니다.
권한이 부족할 경우 fluentbit container 에서 403 에러가 발생합니다.
logstash role 이 template 으로 이미 생성되어 있으므로 해당 role 을 참고하여 생성하거나 logstash role 을 수정해서 사용해도 무방합니다.
OpenSearch 구성이 끝났습니다.
fluentbit 에서 앱 컨테이너의 로그 중 재고 변경 로그만 라우팅 하여 opensearch 로 전송하기 위해,
fluentbit 라우팅과 파싱 설정의 편의성을 위해 앱 컨테이너의 코드를 조금 수정합니다.
앱 컨테이너 코드 수정
objectMapper Bean 설정
opensearch 에 전송할 document 를 json format 으로 출력하기 위해 ObjectMapper 를 사용합니다.
또한 java/kotlin 에선 변수명을 선언할 때 camel case를 사용하지만
opensearch document 의 field는 snake case를 사용하므로 아래와 같이 PropertyNamingStrategy 를 SNAKE_CASE로 설정합니다.
@Bean
fun objectMapperSnakeCase(): ObjectMapper {
return jacksonObjectMapper().also {
it.propertyNamingStrategy = PropertyNamingStrategies.SNAKE_CASE
}
}opensearch 적재용 log appender 추가
opensearch 에 전송할 document 는 별도의 포맷으로 로깅 할 수 있도록 log appender 를 추가합니다.
<appender name="jsonFormattedAppender" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%msg %n</pattern>
</encoder>
</appender>
<logger name="opensearch_efk" level="INFO" additivity="false">
<appender-ref ref="jsonFormattedAppender" />
</logger>fluentbit container 에서 오픈서치 적재 대상 로그를 구분하기 위한 wrapper class 입니다.
loggerName 필드를 통해 opensearch 적재용 로그를 타 로그들로부터 구분합니다.
(logback 에서 logstash encoder 사용, fluentbit 설정에서 정규식을 통한 식별 등 다양한 방법이 존재하니 꼭 이 방법을 따르지 않으셔도 됩니다)
class OpenSearchDocument(
val loggerName: String,
val document: Any
)sendByFluentBit 함수는 위에서 선언한 objectMapper 및 json format appender 를 사용하여 log 출력합니다.
@Service
class OpenSearchService(
val objectMapperSnakeCase: ObjectMapper
) {
companion object {
private const val OPENSEARCH_LOGGER_NAME = "opensearch_efk"
}
private val openSearchLogger by LoggerDelegator(OPENSEARCH_LOGGER_NAME)
fun sendByFluentBit(document: Any) {
openSearchLogger.info(
objectMapperSnakeCase.writeValueAsString(
OpensearchDocumentDto(openSearchLogger.name, document)
)
)
}
}Document Entity 입니다.
class OsDocument(
val eventType: String,
val eventCode: String,
// 생략
) {
class Products(
val productId: String,
val productName: String,
// 생략
)
}그러면 이제 작성한 함수를 호출하여 확인합니다.
openSearchService.sendByFluentBit(OsDocument(..))의도한 대로 camel case 로 선언되어 있던 필드들이 snake case 로 변환되었고,
json 포맷으로 document 키 밑에 출력되었습니다.
{"logger_name":"opensearch_efk","document":{"event_type":"테스트","event_code":"테스트","event_date":"2024-04-15T10:09:53+09:00","event_id":"테스트","store_id":"테스트","store_name":"테스트","products":{"product_id":"테스트","product_name":"테스트","base_quantity":0,"remain_quantity":0,"stocked_in_quantity":0,"category1":"테스트","category2":"테스트","category3":"테스트","brand":"테스트","partner":"테스트","price":17000,"change_remain_quantity":0,"change_stocked_in_quantity":0,"oy_pick":false}}}앱 컨테이너 쪽의 준비는 끝났습니다.
이제 앱에서 출력되는 로그를 fluentbit 에서 식별(routing)하여 opensearch 로 전송하도록 설정이 필요합니다.
우선 fluentbit 설정 및 fluentbit container 에서 사용할 custom docker image 를 생성합니다.
fluentbit custom docker image 생성 및 푸시
fluentbit 설정 파일 작성 (extra.conf)
[SERVICE]
Flush 1
Log_Level info
parsers_file /fluent-bit/etc/extra-parsers.conf
[FILTER]
Name rewrite_tag
Match_regex ^((?!opensearch).)*$
Rule $log .*logger_name\":\"opensearch_efk.* opensearch false
[FILTER]
Name parser
Match opensearch
Parser stock_live_parser
Key_Name log
[FILTER]
Name record_modifier
Match opensearch
Allowlist_key document
[FILTER]
Name nest
Match opensearch
Operation lift
Nested_under document
[OUTPUT]
Name opensearch
Match opensearch
Host vpc-....amazonaws.com
Port 443
Index store-stock-%Y%m%d
Type _doc
tls On
tls.verify Off
Suppress_Type_Name On
AWS_Auth Off
AWS_Region ap-northeast-2
Http_User ${FLUENTBIT_OS_USER}
Http_Passwd ${FLUENTBIT_OS_PW}
Retry_Limit 2
[OUTPUT]
Name stdout
Match opensearch
Log_Level info[SERVICE] parsers_file
파서파일 경로를 지정합니다.
[INPUT]
firelens(:24224) 를 통해 로그가 인입되므로 별도로 INPUT 섹션을 선언하지 않습니다.
[FILTER] rewrite_tag
log 에 os_live_log 문자열이 포함되어 있지 않을 경우 opensearch 태그를 붙입니다.
routing 용도로써 logger_name":"opensearch_efk 문자열이 포함된 로그만 opensearch 에 전송하기 위함입니다.
tag 를 사용한 라우팅이 아닌 filter + grep 을 사용할 경우 필터에 걸리지 않은 모든 로그는 데이터독으로 전송되지 않고 버려집니다.
[FILTER] parser
opensearch 태그가 붙은 log를, SERVICE 섹션에 지정한 parsers_file에서 일치하는 Name 을 가진 파서를 통해 파싱합니다.
[FILTER] record_modifier
Allowlist_key 로 지정된 document 키를 제외한 키를 제거합니다.
라우팅 용도로 사용된 logger_name 이 과정에서 제거됩니다.
[FILTER] nest lift
document 키 밑의 object 들을 상위 계층으로 올립니다(wrapper 벗기기).
[OUTPUT] opensearch
정제된 로그를 opensearch 로 전송합니다.
Index를 store-stock-%Y%m%d 와 같이 설정할 경우 일자별로 인덱스를 생성하게 되며
document 를 전송하기 전에, index 를 먼저 생성한 후 document 가 전송됩니다.
[OUTPUT] stdout
opensearch 태그가 붙은 log 를 출력합니다.
fluentbit 컨테이너의 로그를 cloudwatch 에서 확인하기 위함입니다. (fluentbit 컨테이너의 logDriver 설정 필요)
fluentbit parser 설정 파일 작성 (extra-parsers.conf)
[PARSER]
Name stock_live_parser
Format json[PARSER]
parser 는 INPUT/FILTER/OUTPUT 과 별도의 파일에 선언해야 합니다.
이미 json 으로 출력한 컨테이너 로그인데 json parser 를 사용하는 이유는,
json parser 를 사용하지 않을 경우 아래와 같이 log key 밑에 container 로그가 들어있는 형태로 input 되기 때문입니다.
{"log"=>"{"data1":"test1", "data2":"test2"}"}Dockerfile 작성 및 ECR 에 푸시
도커파일을 작성합니다.
FROM public.ecr.aws/aws-observability/aws-for-fluent-bit:latest
COPY extra.conf /fluent-bit/etc/extra.conf
COPY extra-parsers.conf /fluent-bit/etc/extra-parsers.confdocker 빌드 및 AWS ECR 에 푸시합니다.
# aws sso login
aws sso login --profile ECS_Developer-40**
# ecr 접속
aws --profile ECS_Developer-40** ecr get-login-password --region ap-northeast-2 | docker login --username AWS --password-stdin 40**.dkr.ecr.ap-northeast-2.amazonaws.com
# docker build
# mac os 를 사용할 경우 --platform linux/amd64 옵션을 주어 이미지 호환성 오류 방지
docker build . --platform linux/amd64 -t 40**.dkr.ecr.ap-northeast-2.amazonaws.com/catalog-inventory-fluentbit:latest
# aws ecr에 푸시
docker push 40**.dkr.ecr.ap-northeast-2.amazonaws.com/catalog-inventory-fluentbit:latestprivate ECR 에 업로드된 이미지를 확인합니다.

이제 push한 fluentbit image 를 사용하도록 fargate container 를 설정합니다.
Fargate 설정
container 설정 수정 (taskdef.json)
{
"containerDefinitions": [
{
"name": "catalog-api-dev-container", # app container
"image": "40**.dkr.ecr.ap-northeast-2.amazonaws.com/catalog-api-dev-repo",
"logConfiguration": {
"logDriver": "awsfirelens", # log driver 로 firelens 사용
"secretOptions": [
{
"valueFrom": "arn:aws:ssm:ap-northeast-2:**:parameter/datadog/apikey/aws/ecs/fargate",
"name": "apikey"
}
],
"options": { # datadog 로그 전송을 위한 설정으로 본 포스팅에선 다루지 않습니다.
"dd_message_key": "log",
"compress": "gzip",
"provider": "ecs",
"dd_service": "catalog-api-dev",
"Host": "http-intake.logs.datadoghq.com",
"TLS": "on",
"dd_source": "fargate",
"dd_tags": "env:dev,env_type:fargate",
"Name": "datadog"
}
},
// ... 생략
},
{
"name": "oymall-datadog", # datadog agent (jvm metric 전송용)
"image": "public.ecr.aws/datadog/agent:latest",
// ... 생략
},
{
"name": "fluentbit-log-router", # fluentbit container
"image": "40**.dkr.ecr.ap-northeast-2.amazonaws.com/catalog-inventory-fluentbit:latest", # custom docker image 사용
"environment": [
{
"name": "FLUENTBIT_OS_USER",
"value": "fluentbit" # fluentbit container 에서 사용할 opensearch user 정보
},
{
"name": "FLUENTBIT_OS_PW",
"value": ""
}
],
"logConfiguration": {
"logDriver": "awslogs", # fluentbit container 로그를 cloudwatch 에서 확인 필요할 때 사용. fluentbit 설정에 output stdout 필요.
"options": {
"awslogs-create-group": "true",
"awslogs-group": "/ecs/catalog-api-dev-task",
"awslogs-region": "ap-northeast-2",
"awslogs-stream-prefix": "ecs"
}
},
"firelensConfiguration": { # firelens 설정
"type": "fluentbit",
"options": {
"config-file-type": "file",
"config-file-value": "/fluent-bit/etc/extra.conf", # 앞서 설정한 fluentbit conf 파일 지정
"enable-ecs-log-metadata": "true" #ecs 로그 수집을 위해 true 선언 필수
}
},
// ... 생략
}
],
"requiresCompatibilities": [
"FARGATE"
]
// ... 생략
}모든 준비가 끝났습니다.
이제 마지막으로 테스트만 남았습니다.

테스트 및 결과
코드 배포 및 변경된 사항을 릴리즈합니다.

총 3개의 컨테이너가 정상적으로 올라왔습니다.
이제 재고 변경 이벤트를 발생시켜 로그 및 적재된 document 를 확인합니다.
컨테이너 로그 확인
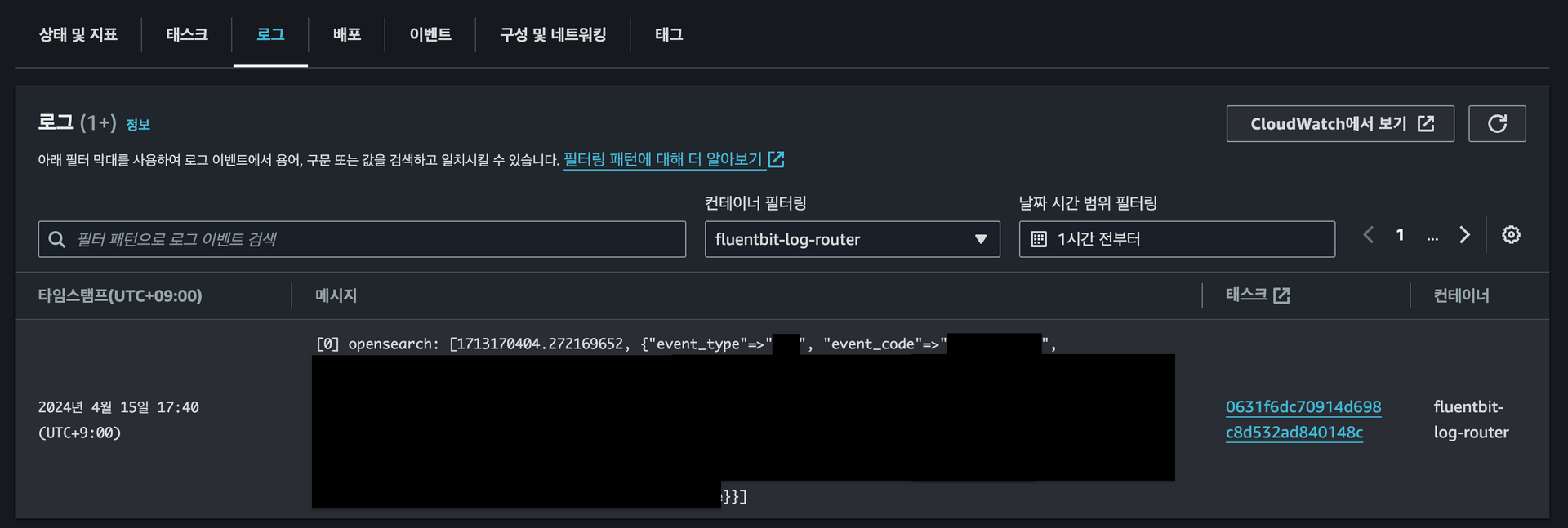
컨테이너 로그에 의도한 대로 잘 파싱 되어 출력되었습니다.
OpenSearch 대시보드에서도 데이터가 잘 들어왔는지 확인합니다.
OpenSearch Dashboard 확인

의도한 대로 일자별로 인덱스가 생성되었습니다.
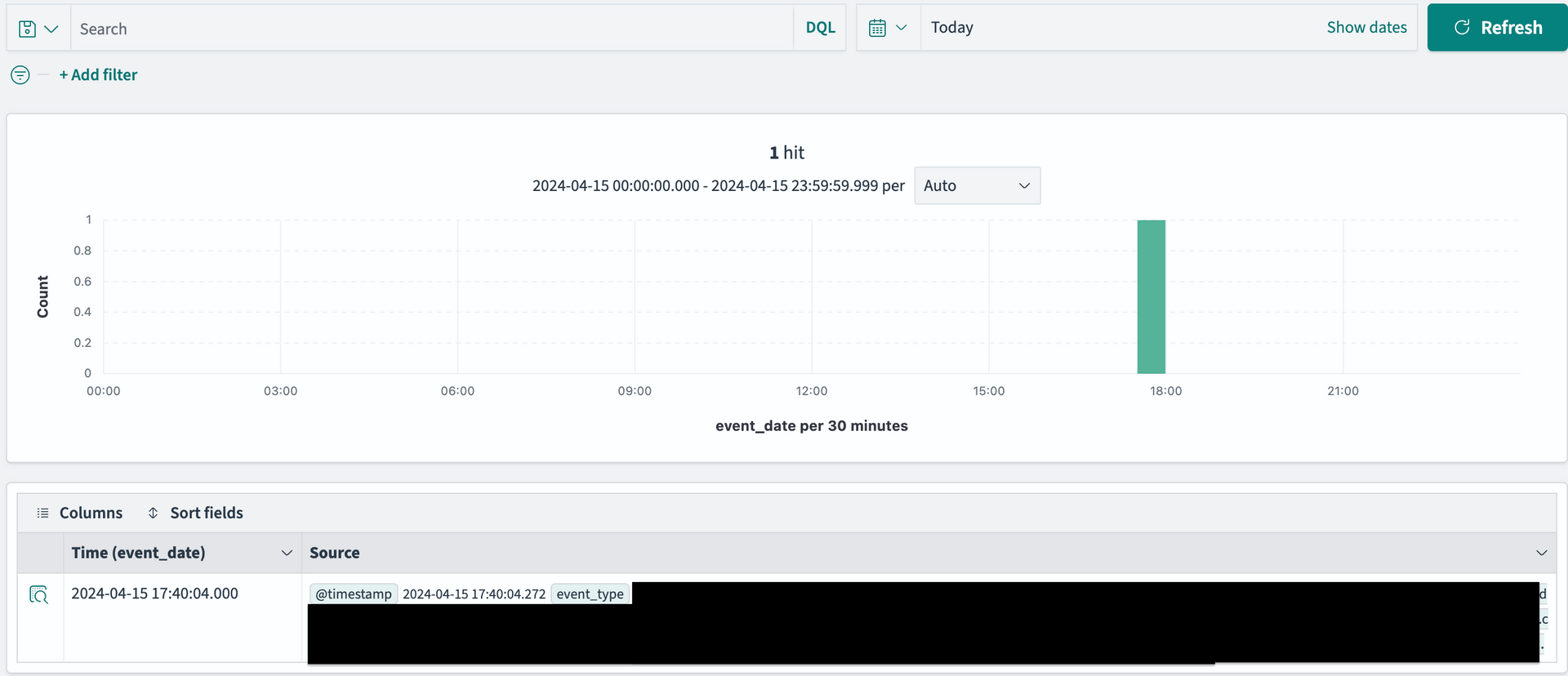
document 도 잘 적재되었습니다.
이렇게 ECS Fargate 환경에서의 OpenSearch + EFK 구축이 끝났습니다.
이제 재고가 언제 어디서 어떻게 변경되었는지 추적할 수 있게 되었습니다.
(kibana 구성은 본 포스팅에서 다루지 않습니다)
포스팅을 마무리 하기 전에..
진짜 마지막으로 OpenSearch Rest API 를 사용한 적재 방법도 가볍게 다뤄보겠습니다..

OpenSearch Rest API 를 사용한 Document 적재
OpenSearch 는 Rest API 를 지원하므로 logstash/Fluentbit/Fluentd 와 같은 로그 수집기를 사용하지 않고
데이터를 코드 레벨에서 직접 전송 및 적재할 수 있습니다.
fluentbit sidecar pattern 을 사용할 경우 앱 컨테이너와 별개로, 분리된 컨테이너에서 데이터 전송을 처리한다는 장점이 있지만,
OpenSearch Rest API 를 사용하면 코드를 직접 작성하기 때문에 예외처리 등 보다 유연한 처리가 가능하다는 장점이 있습니다.
아래는 OpenSearch Low level client 를 사용하여 데이터를 적재하는 예제입니다.
(High level client 사용이 더 손쉽지만, OpenSearch 3.0 version 부터 지원되지 않으므로 Low level client 사용을 권장합니다)
dependency 를 추가합니다.
implementation("org.opensearch.client:opensearch-rest-client:2.12.0")
implementation("org.opensearch.client:opensearch-java:2.6.0")opensearch client bean 을 선언합니다.
aws kms 암복호화 관련 부분은 생략하겠습니다.
@Configuration
class OpenSearchClientProvider(
val credentialEncoder: CredentialEncoder
) {
@Autowired
lateinit var opensearchProperty: OpensearchProperty
@Bean
fun osClientCredentials() : BasicCredentialsProvider {
val basicCredentialProvider = BasicCredentialsProvider()
basicCredentialProvider.setCredentials(
AuthScope.ANY,
UsernamePasswordCredentials(
opensearchProperty.username,
credentialEncoder.decryptInternalByAwsKms(opensearchProperty.password, KmsKey.OPENSEARCH)
)
)
return basicCredentialProvider
}
@Bean
fun openSearchClient(
@Qualifier("osClientCredentials")
credentialsProvider: CredentialsProvider
): OpenSearchClient {
val httpHost = HttpHost(opensearchProperty.host, opensearchProperty.port, opensearchProperty.scheme)
val restClient = RestClient.builder(httpHost)
.setHttpClientConfigCallback { httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
}.build()
val transport = RestClientTransport(restClient, JacksonJsonpMapper())
return OpenSearchClient(transport)
}
}bulk api 를 사용하여 document 를 전송하는 함수입니다.
@Service
class OpensearchService(
@Qualifier("openSearchClient")
val openSearchClient: OpenSearchClient,
) {
fun <TDocument> sendByBulkApi(
docs: List<TDocument>,
index: OpensearchIndex
): BulkResponse {
val bulkRequest = BulkRequest.Builder()
docs.forEach {
bulkRequest.operations { operation: BulkOperation.Builder ->
operation.index { idx: IndexOperation.Builder<TDocument> ->
idx.index(OpensearchIndex.dateFormattedIndex(index))
.id(null)
.document(it)
}
}
}
return openSearchClient.bulk(bulkRequest.build())
}
}id 를 지정하지 않고 null 을 넘길 경우 opensearch 에서 id 를 자동 생성합니다.
비슷하게 index 및 document 에 대한 CRUD 가 가능합니다.
Maximum size of HTTP request payloads
bulk api 를 사용하여 대량의 document 를 한 번에 OpenSearch 로 전송할 수 있지만,
용량 제한이 있어 document size 를 고려하여 적절히 청크 단위로 나눠서 전송해야 합니다.
인스턴스 타입별 Http payloads limit 은 여기를 참고해 주세요.
(위에서 따로 언급 및 설정하지 않았지만 fluentbit default chunk size 는 2MB 입니다)
마치며..
지금까지 OpenSearch + EFK 에 대해 알아보았습니다.
꽤 많은 내용을 다루다 보니 깊이가 다소 얕은 느낌이 들지만,
마무리는 멋지게 짓겠습니다.

참고
fluentbit doc
firelens aws doc
fluentbit rewrite_tag
opensearch java client doc
