
안녕하세요! 상품스쿼드 백엔드 개발자 빽곰입니다.
상품스쿼드에서 상품데이터 Pipeline을 위해 도입한 Debezium CDC를 소개해 보려고 합니다.
왜 도입하게 되었을까?..🤫
상품스쿼드에서는 상품의 메타정보를 효율적으로 관리/제공하기 위한 Catalog Service 개발을 진행 중입니다.
기존 monolithic한 시스템을 MSA로 전환하는 과정에서 데이터베이스의 마이그레이션과 동기화가 필요하게 되었고
다음과 같이 세 가지 주요 목표를 설정했습니다.
1️⃣ Oracle, MySQL, MongoDB, Cassandra 등 다양한 데이터베이스 간 유연한 동기화
2️⃣ 기존 데이터와 동기화를 비롯한 데이터 간의 유기적 흐름 PipeLine 구성
3️⃣ 상품데이터 변경 내역에 대한 효율적인 Tracking Process 구축
이 목표를 달성하기 위해 기술검토 결과 Debezium을 도입하기로 결정했습니다.
Debezium
- CDC(change data capture)의 대표적인 오픈소스
- Oracle / MySQL / MongoDB / Cassandra 등 다양한 데이터베이스 지원
- 신규 버전을 계속해서 릴리즈하고 있으며 Reference 문서, 커뮤니티 등 활성화되어 있음
DB 트랜잭션 로그를 이용하여 데이터 변경 사항을 실시간으로 캡처하여 스트리밍 하는 오픈 소스 입니다.
| Connector | Role | Description |
|---|---|---|
| Source Connector | PRODUCER | 데이터 변경 발생시 MSK로 실시간 데이터 전송 |
| Sink Connector | CONSUMER | Target DB에 데이터를 적재, 대표적으로 JDBC Sink Connector |
저희 상품스쿼드에서는 AWS MSK Connect에 Source를 Debezium으로 구성하고 Consume 데이터를 처리 후 활용하기 위해 별도의 Consumer 서버로 구성했습니다.
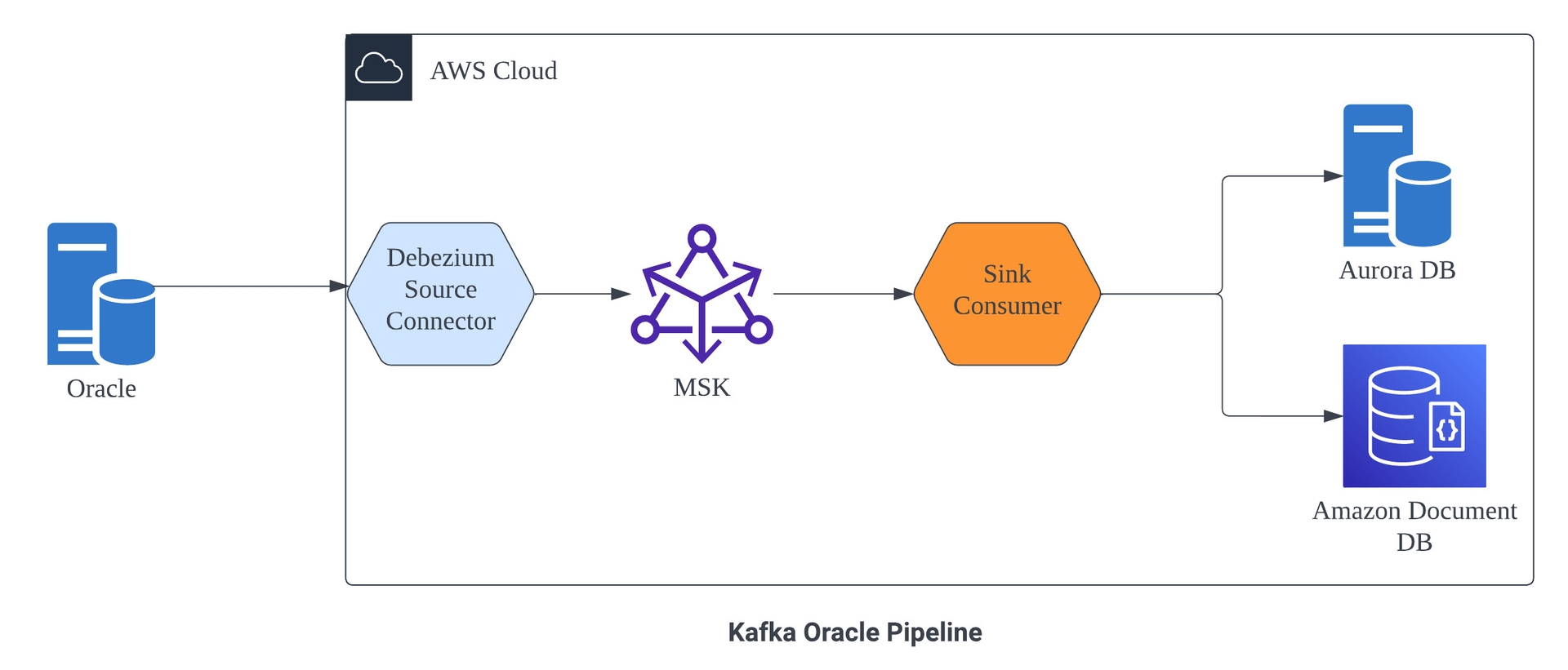
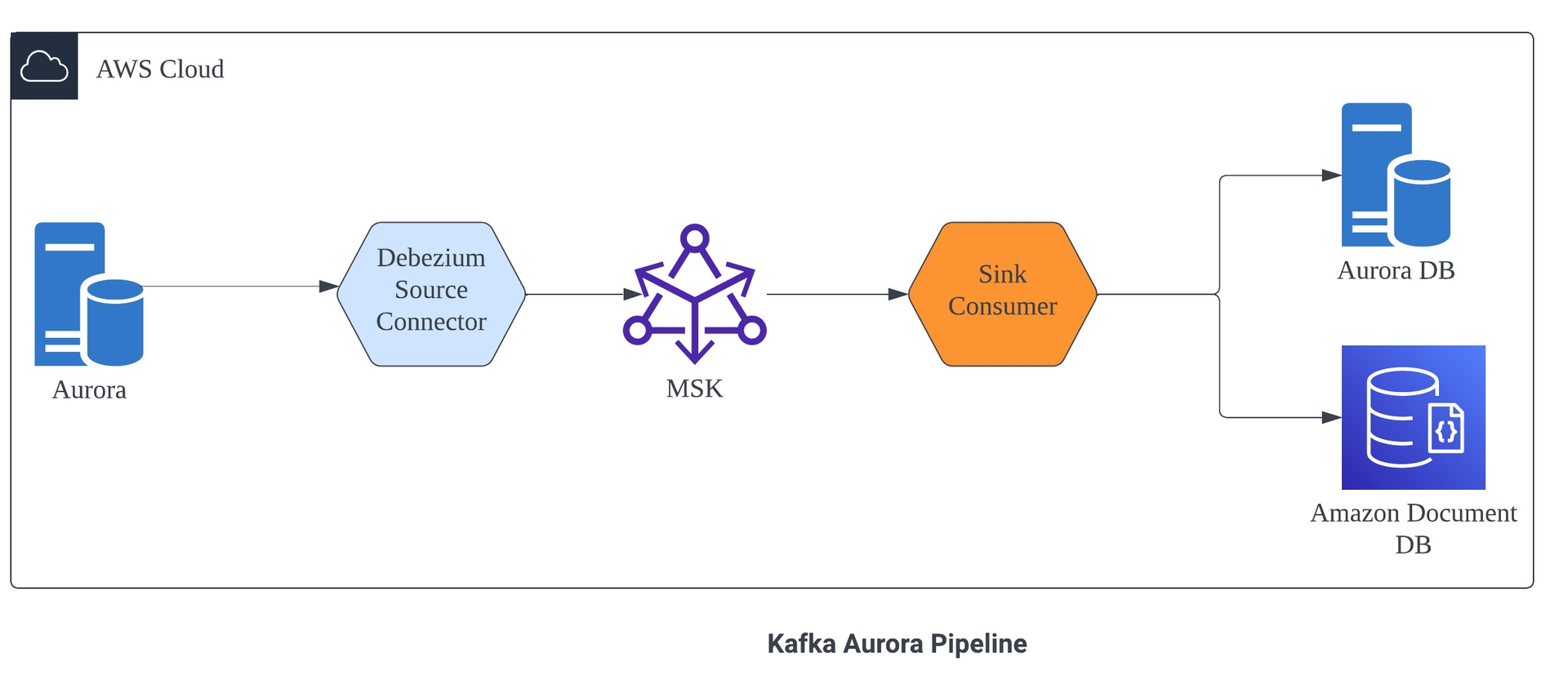
Oracle DB와 Aurora DB의 Pipeline 시스템 구성도 입니다.
▶️ DB 설정
DB의 트랜잭션 로그 기반으로 동작하기 때문에 DB에 로그 관련 설정이 필요합니다. Xstream과 Logminer 방식이 있고
Xstream의 경우 kafka_home/libs 경로에 Xstream.jar가 업로드가 필요해서 MSK connect는 매니지드 서비스라 지원 불가 😂
(MSK에서 Xstream으로 얼마나 많은 시간을 보내게 되었는지.....🤫)
| CDC 방식 | 특 징 |
|---|---|
| Xstream |
Goldengate 라이센스가 필요하며 비용이 비싸지만 Logiminer 보다 성능/리소스 유리할 수 있음 |
| Logminer |
Debezium의 Default 방식으로 LOG 파일을 분석하여 CDC |
Oracle Logminer Guide💡
ORACLE_SID=ORACLCDB dbz_oracle sqlplus /nolog
CONNECT sys/top_secret AS SYSDBA
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate
startup mount
alter database archivelog;
alter database open;
-- Should now "Database log mode: Archive Mode"
archive log list
exit;
//Log mode 확인
SQL> SELECT LOG_MODE FROM V$DATABASE;
LOG_MODE
------------
ARCHIVELOG
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
//Logminer User 설정
sqlplus sys/top_secret@//localhost:1521/ORCLCDB as sysdba
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
sqlplus sys/top_secret@//localhost:1521/ORCLPDB1 as sysdba
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/ORCLPDB1/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
sqlplus sys/top_secret@//localhost:1521/ORCLCDB as sysdba
CREATE USER dbzuser IDENTIFIED BY dbz
DEFAULT TABLESPACE logminer_tbs
QUOTA UNLIMITED ON logminer_tbs
CONTAINER=ALL;
GRANT CREATE SESSION TO dbzuser CONTAINER=ALL;
GRANT SET CONTAINER TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$DATABASE to dbzuser CONTAINER=ALL;
GRANT FLASHBACK ANY TABLE TO dbzuser CONTAINER=ALL;
GRANT SELECT ANY TABLE TO dbzuser CONTAINER=ALL;
GRANT SELECT_CATALOG_ROLE TO dbzuser CONTAINER=ALL;
GRANT EXECUTE_CATALOG_ROLE TO dbzuser CONTAINER=ALL;
GRANT SELECT ANY TRANSACTION TO dbzuser CONTAINER=ALL;
GRANT LOGMINING TO dbzuser CONTAINER=ALL;
GRANT CREATE TABLE TO dbzuser CONTAINER=ALL;
//GRANT LOCK ANY TABLE TO dbzuser CONTAINER=ALL;
GRANT CREATE SEQUENCE TO dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR TO dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR_D TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG_HISTORY TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_LOGS TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGFILE TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVED_LOG TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$TRANSACTION TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$MYSTAT TO dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$STATNAME TO dbzuser CONTAINER=ALL;
exit;MySQL binlog Guide💡
create user 'dbzuser'@'%' identified by 'password';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'dbzuser'@'%' with grant option;
FLUSH PRIVILEGES;
SHOW GRANTS FOR 'dbzuser'@'%';
--수행시 결과값 ON 아닐경우 binlog 활성화 필요! Aurora의 경우 클러스터 Configuration에서 변경 가능
SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM performance_schema.global_variables WHERE variable_name='log_bin';※ Connector 실행 시 현재 데이터의 Snapshot을 수행할 때 lock이 발생할 수 있어서 안전하게 계정의 lock 권한 제외를 추천드립니다!
< Oracle 설정 가이드 참고 >
< MySQL설정 가이드 참고 >
▶️ MSK 플러그인 생성
먼저 AWS MSK에서 Debezium을 사용하기 위해서는 플러그인 생성이 필요합니다!
🔷 AWS MSK > MSK connect > 사용자 지정 플러그인 > 플러그인 생성
| DB | PluginFile |
|---|---|
| Oracle |
debezium JDBC Driver MSK 구성 공급자 |
| MySQL |
debezium MSK 구성 공급자 |
=> 다운로드 파일들을 단일파일 ZIP로 압축하여 S3업로드 후 사용자 지정 플러그인 생성으로 등록하여 사용
정상적으로 플러그인이 생성되면 컨넥터 생성시 사용자 지정 플러그인 선택할 수 있습니다.
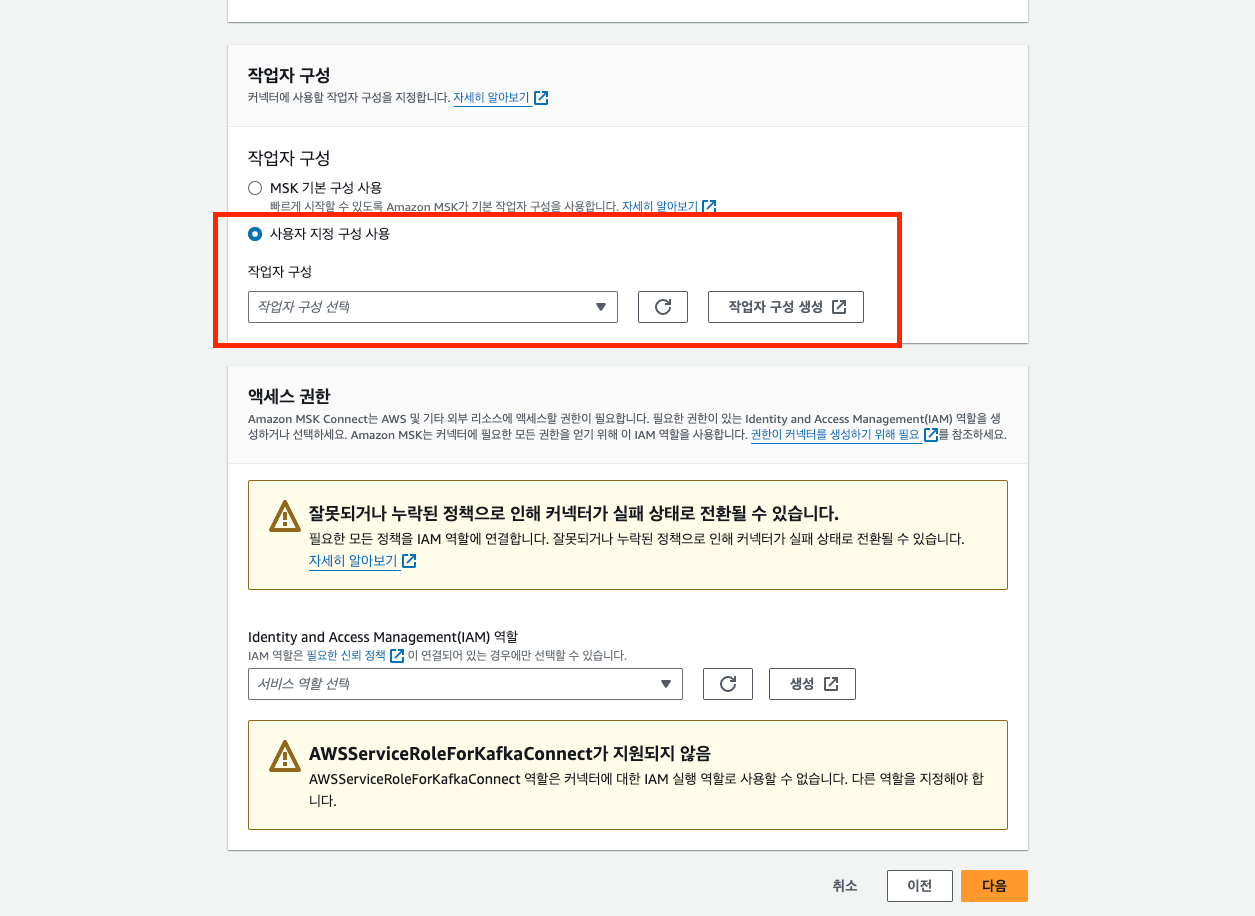
▶️ MSK Connector 생성하기
MSK Connect는 JVM 프로세스 Worker로 구성되어 있으며 Worker가 Task를 수행하게 됩니다.
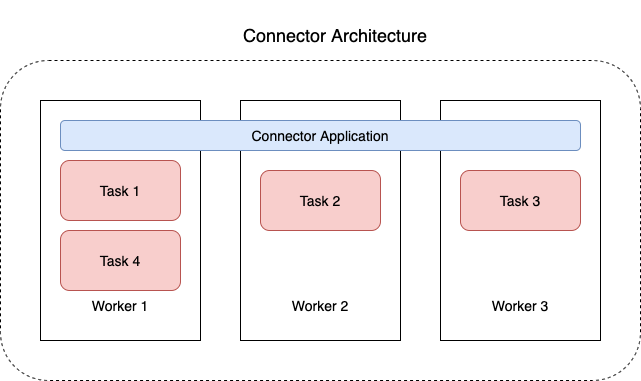
🔷 AWS MSK > MSK connect > 커넥터 > 작업자 구성
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
-- __amazon_msk_connect_offset DB log 오프셋 기록 토픽 파티션 및 리플리케이션 수
offset.storage.partitions=3
offset.storage.replication.factor=3
-- __amazon_msk_connect_config 커넥터 내부 구성정보 저장 토픽 리플리케이션 수(partitions은 변경불가)
config.storage.replication.factor=3
-- __amazon_msk_connect_status 작업 구성상태 변경 기록 토픽 파티션 및 리플리케이션 수
status.storage.partitions=3
status.storage.replication.factor=3작업자 구성이 완료되면 컨넥터 생성시 사용자 지정 작업자를 선택할 수 있습니다.
🔷 AWS MSK > MSK connect > 커넥터 > 커넥터 생성
플러그인, 컨넥터명, MSK 클러스터를 선택 후 가장 중요한 컨넥터 구성 입니다. 컨넥터 구성 정보로 컨넥터를 컨트롤 할 수 있으며
오류 발생과 이슈 등도 대부분 컨넥터 구성 정보를 변경해서 해결 가능하니 반드시 Debezium 공식 문서를 꼼꼼하게 읽어주시기를...🫶
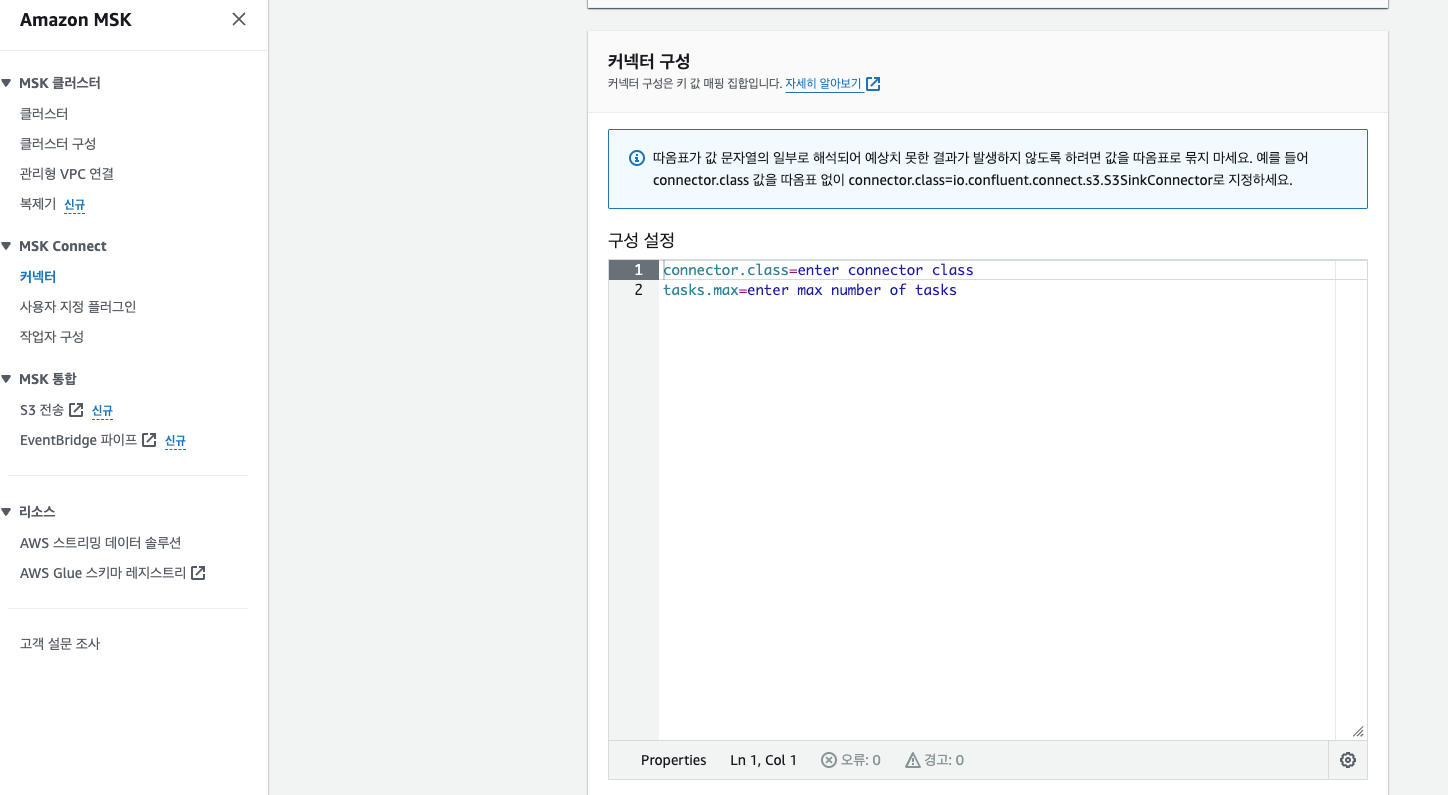
--ORACLE
connector.class=io.debezium.connector.oracle.OracleConnector
-- kafka 클라이언트/프로듀서 보안 및 프로토콜
schema.history.internal.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.producer.security.protocol=SASL_SSL
schema.history.internal.producer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.consumer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.security.protocol=SASL_SSL
-- 스키마 변경이력 토픽
schema.history.internal.kafka.topic=schema-changes.product
-- ddl 스냅샷 캡쳐대상만
schema.history.internal.store.only.captured.tables.ddl=true
--kafka 클러스터 정보
schema.history.internal.kafka.bootstrap.servers=""
--DB정보
database.user=생성한 로그마이너계정
database.dbname=db명
database.url=jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)
database.pdb.name=플러그인DB명
database.connectionTimeZone=Asia/Seoul
database.password=3
database.port=1234
table.include.list=스키마명.테이블1,스키마명.테이블2
-- snapshot시 table lock 방지!
snapshot.locking.mode=none
-- before/after와 changefield관련 SMT
transforms.moveHeadersToValue.headers=Changed
transforms=changes,moveHeadersToValue,convertTimezone
transforms.convertTimezone.converted.timezone=Asia/Seoul
transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter
transforms.moveHeadersToValue.operation=move
transforms.moveHeadersToValue.type=io.debezium.transforms.HeaderToValue
transforms.moveHeadersToValue.fields=ChangedFields
transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState
transforms.changes.header.changed.name=Changed
-- Debezium은 최대 1개 작업자만 지원
tasks.max=1
-- delete 데이터 기록
tombstones.on.delete=true
-- 토픽 명칭 prefix
topic.prefix=proudctV1
key.converter.schemas.enable=false
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter=org.apache.kafka.connect.json.JsonConverter
heartbeat.interval.ms=30000
-- 컨넥터 여러개 구성시 테이블명 분리해서 사용 권장
log.mining.flush.table.name=LOG_MINING_FLUSH
log.mining.strategy=online_catalog
time.precision.mode=connect
-- clob 스냅샷 사용시
lob.enabled=true--MySQL
connector.class=io.debezium.connector.mysql.MySqlConnector
schema.history.internal.producer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.security.protocol=SASL_SSL
schema.history.internal.producer.security.protocol=SASL_SSL
schema.history.internal.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.store.only.captured.tables.ddl=true
schema.history.internal.store.only.captured.databases.ddl=true
schema.history.internal.kafka.topic=schema-changes.product
schema.history.internal.kafka.bootstrap.servers=""
database.history.kafka.topic=db.sink.historyV2
database.history.kafka.recovery.attempts=4
database.history.kafka.recovery.poll.interval.ms=100
database.history.kafka.query.timeout.ms=3000
database.hostname=dev-online-mysql-cluster.abcd.ap-northeast-2.rds.amazonaws.com
database.user=kafkaCDC
database.password=
database.connectionTimeZone=Asia/Seoul
database.port=3406
database.server.id=10004
database.server.name=AuroraCDCV
snapshot.locking.mode=none
database.include.list=product
table.include.list=product.테이블명
transforms=changes,moveHeadersToValue,convertTimezone
transforms.convertTimezone.converted.timezone=Asia/Seoul
transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter
transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState
transforms.moveHeadersToValue.operation=move
transforms.moveHeadersToValue.type=io.debezium.transforms.HeaderToValue
transforms.moveHeadersToValue.fields=ChangedFields
transforms.changes.header.changed.name=Changed
transforms.moveHeadersToValue.headers=Changed
include.schema.changes=true
poll.interval.ms=30000
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
heartbeat.interval.ms=1000
tasks.max=1
tombstones.on.delete=true
topic.prefix=AuroraCDC
※ Oracle과 MySQL의 컨넥터 구성이 버전별로 조금씩 다르기 때문에 반드시 공식문서 확인 필요합니다! snapshot.locking.mode를 꼭 확인하세요!
< Oracle DEBEZIUM >
< MySQL DEBEZIUM >
▶️ Debezium Connector Result
컨넥터가 정상적으로 생성되면 토픽조회시 컨넥터명으로 Config / Offset / status 토픽이 생성됩니다.
-- 토픽조회
>> 각 MSK connect의 config/offset/status 정보
__amazon_msk_connect_configs_OracleCDC_c2a9-50d5-4095-a08f-169074c4-3
__amazon_msk_connect_status_OracleCDC_c2a9-50d5-4095-a08f-169074c4-3
__amazon_msk_connect_offsets_OracleCDC_c2a9-50d5-4095-a08f-169074c4-3
>> CDC 대상 테이블별 토픽
OracleCDC.스키마명.테이블명Config 토픽에서 컨넥터 구성 정보를 확인할 수 있고
Offset 토픽에서 Oracle의 경우 현재 SCN 값 / MySQL의 경우 pos 값을 확인 가능합니다.
Status 토픽의 경우 컨넥터의 상태 정보가 기록되기 때문에 오류 발생 시 이력을 확인해 보거나
해당 토픽을 Consume하여 알림 등으로 활용할 수 있습니다.
실제 CDC한 테이블의 토픽 메세지입니다.
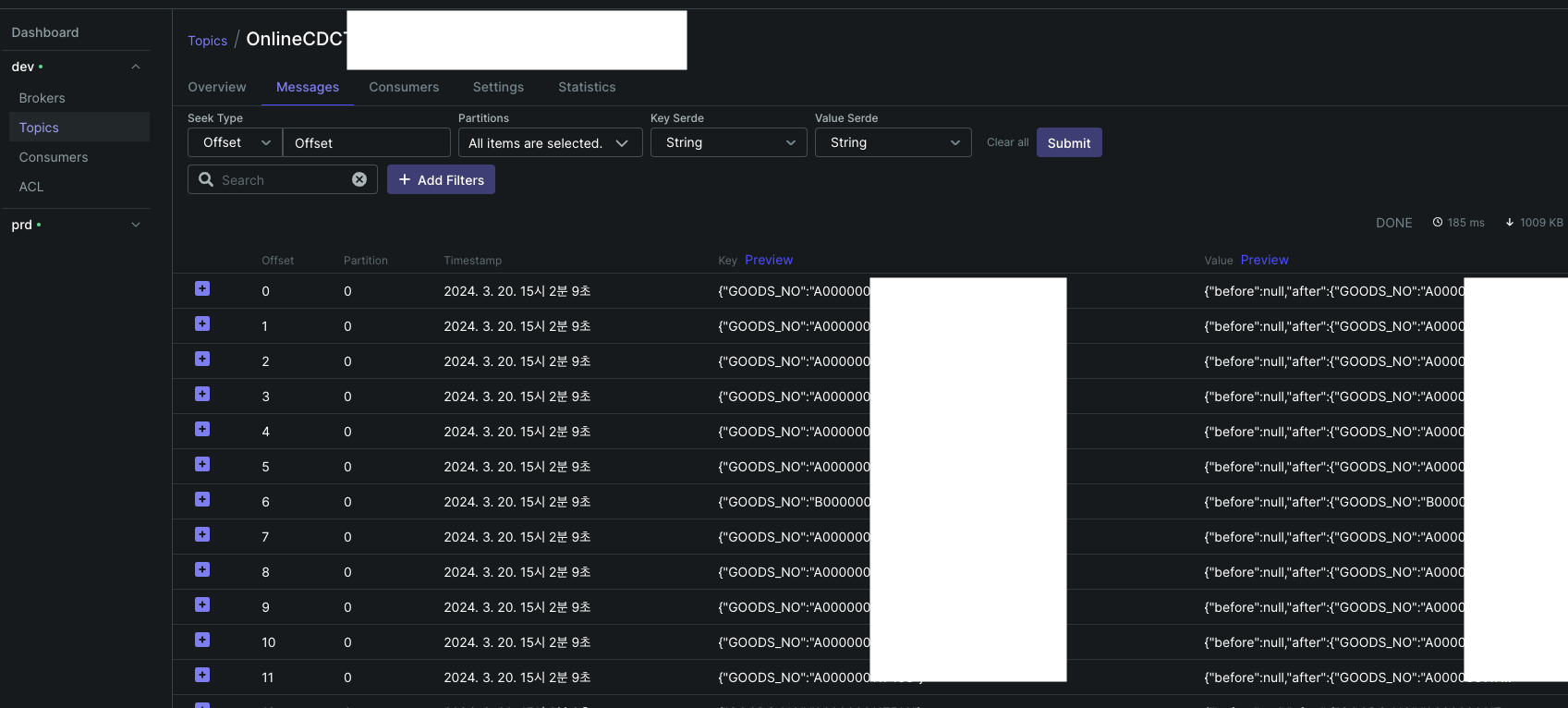
{
"before": {
"GOODS_NO": "A000000114",
"LANG_CD": "ko",
"SYS_MOD_DTIME": 1705011056000,
"SYS_MODR_ID": "tester"
},
"after": {
"GOODS_NO": "A000000114",
"LANG_CD": "ko",
"SYS_MOD_DTIME": 1705011163000,
"SYS_MODR_ID": "tester2"
},
"source": {
"version": "2.5.1.Final",
"connector": "oracle",
"name": "OnlineCDCTest",
"ts_ms": 1704978763000,
"snapshot": "false",
"db": "db명",
"sequence": null,
"schema": "스키마명",
"table": "테이블명",
"txId": "610107007bce02",
"scn": "4102020916306",
"commit_scn": "410202091630",
"lcr_position": null,
"rs_id": "0x004c4d.00106e.00",
"ssn": 0,
"redo_thread": 1,
"user_name": "WHITEBEAR" 🌟 사용자 계정 🌟
},
"op": "u", 🟢 스냅샷(R)/등록(c)/수정(u)/삭제(d)
"ts_ms": 1704978765267,
"transaction": null,
"ChangedFields": [ 🟠 수정된 필드
"SYS_MOD_DTIME",
"SYS_MODR_ID"
]
}SMT구성으로 Before / After / ChangeField가 구분돼서 확인됩니다.😻
메세지 포맷 변경 참고 - < Debezium >
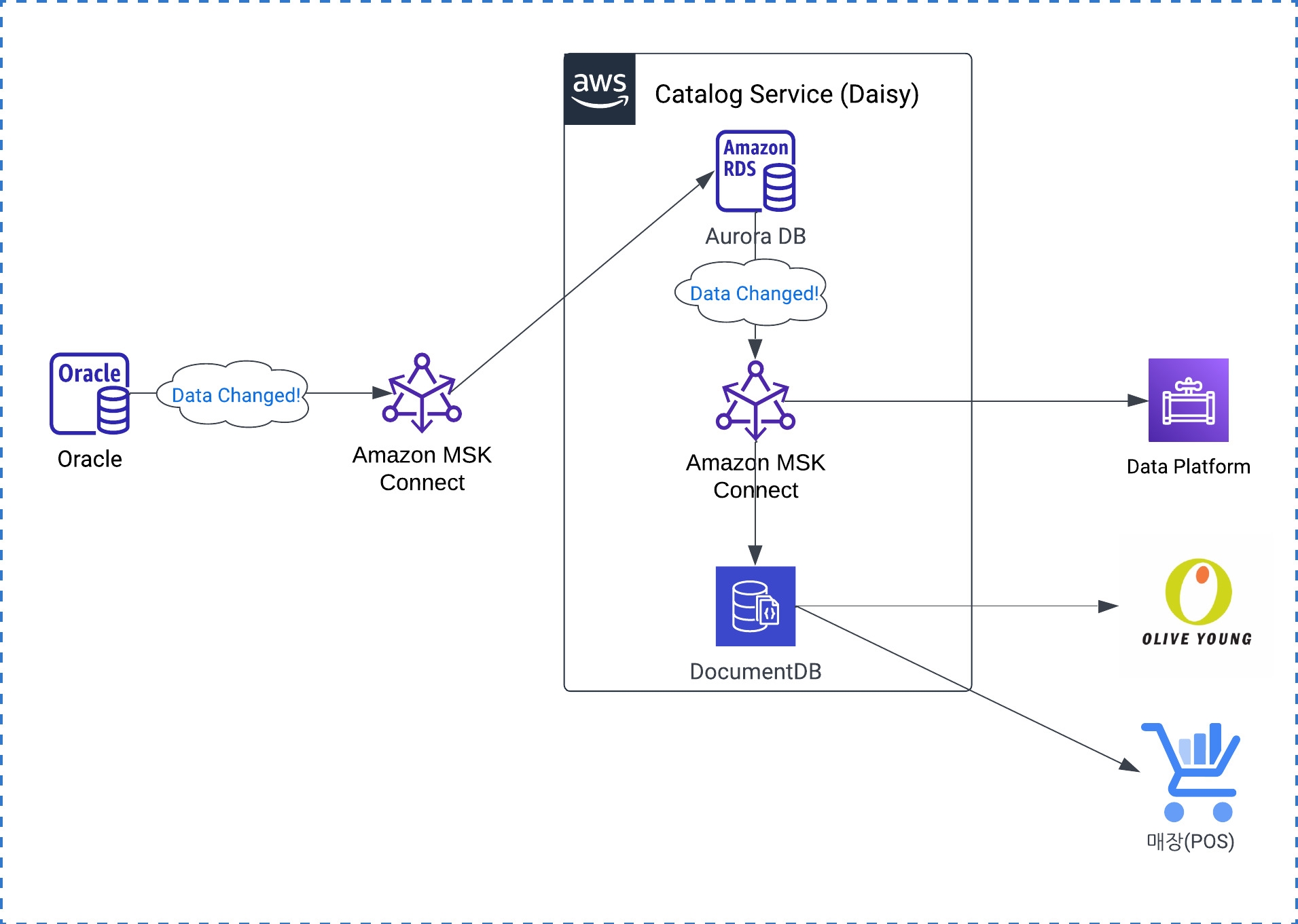
올리브영 상품스쿼드에서는
- 기존 Oracle DB의 상품데이터의 Aurora DB로 동기화
- Aurora DB 변경/관리 데이터를 Document DB로 동기화
위와 같이 2개의 MSK Connect를 활용하여 Catalog Service를 제공하기 위해 개발 진행 중입니다.😊
마무리
지금까지 Debezium CDC를 MSK Connect로 구성하는 방법에 대해 소개해 드렸습니다.
다음 포스팅에서는 Debezium을 적용하면서 겪을 수 있는 이슈& 트러블 슈팅, 운영 DB 도입과정 등 더 자세한 정보와 팁을 공유해 드리겠습니다.
Debezium MSK Connect를 고민하시는 분들에게 도움이 되었으면 좋겠습니다. 😊

