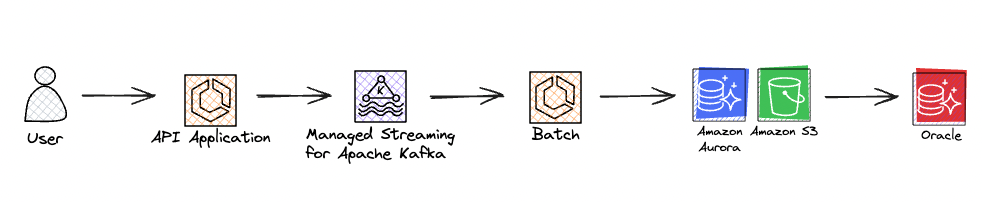
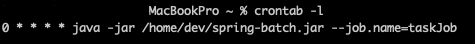하나의 데이터 추출 요청에 하나의 Job 이 실행되고, 다수의 Partitioning 작업이 진행되어 엑셀을 생성하는데 효율적임
여러 엑셀 파일을 만들고, 최종적으로 한 개로 병합 작업 방식을 채택
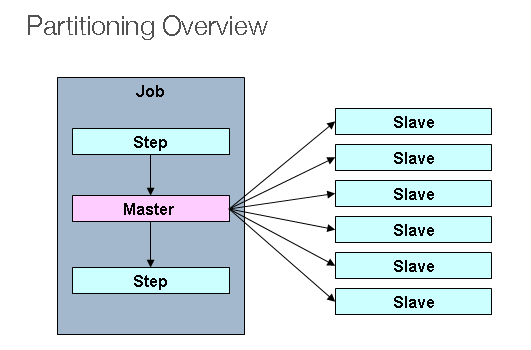
Partitioning은 하나의 Job에서 다수의 Secondary를 생성
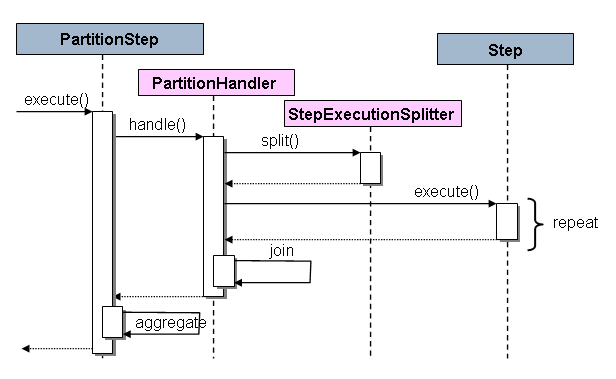
PartitionStep의 동작 방식
내부적으로 Step을 분할하여 반복 실행하도록 실행되는 구조
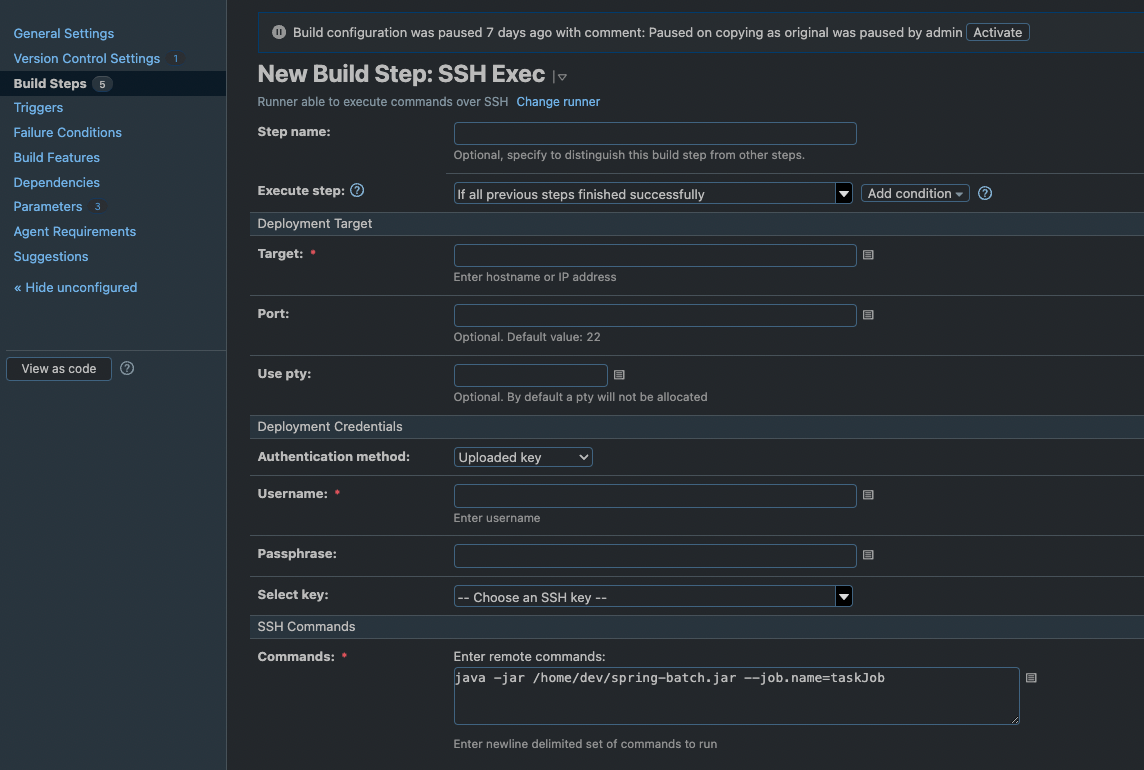
PartitionStep 코드는 아래와 같이 작성
PartitionStepBuilder 객체를 통해서 PartitionStep를 생성
@BeanpublicSteppartitionMainStep(){return stepBuilderFactory.get("partitionMainStep").partitioner("subStep",partitioner(null,null,null))// partitioner 사이즈 및 옵션 부여.step(partitionSubStep())// step 분할 repeat 대상 .taskExecutor(taskExecutor)// 동기 or 비동기, task 옵션 설정.build();}
아래는 PartitionStep 을 생성할 때 PartitionStepBuilder의 build()를 호출하여 객체를 생성하게 됩니다.
publicStepbuild(){PartitionStep step =newPartitionStep();
step.setName(getName());super.enhance(step);if(partitionHandler !=null){
step.setPartitionHandler(partitionHandler);}else{TaskExecutorPartitionHandler partitionHandler =newTaskExecutorPartitionHandler();
partitionHandler.setStep(this.step);if(taskExecutor ==null){
taskExecutor =newSyncTaskExecutor();}
partitionHandler.setGridSize(gridSize);
partitionHandler.setTaskExecutor(taskExecutor);
step.setPartitionHandler(partitionHandler);}if(splitter !=null){
step.setStepExecutionSplitter(splitter);}else{boolean allowStartIfComplete =isAllowStartIfComplete();String name = stepName;if(this.step !=null){try{
allowStartIfComplete =this.step.isAllowStartIfComplete();
name =this.step.getName();}catch(Exception e){if(logger.isInfoEnabled()){
logger.info("Ignored exception from step asking for name and allowStartIfComplete flag. "+"Using default from enclosing PartitionStep ("+ name +","+ allowStartIfComplete +").");}}}SimpleStepExecutionSplitter splitter =newSimpleStepExecutionSplitter();
splitter.setPartitioner(partitioner);
splitter.setJobRepository(getJobRepository());
splitter.setAllowStartIfComplete(allowStartIfComplete);
splitter.setStepName(name);this.splitter = splitter;
step.setStepExecutionSplitter(splitter);}if(aggregator !=null){
step.setStepExecutionAggregator(aggregator);}try{
step.afterPropertiesSet();}catch(Exception e){thrownewStepBuilderException(e);}return step;}
아래 PartitionStep Execute를 실행하여 진행하게 되구요.
protectedvoiddoExecute(StepExecution stepExecution)throwsException{if(hasReducer){
reducer.beginPartitionedStep();}// Wait for task completion and then aggregate the results Collection<StepExecution> stepExecutions =getPartitionHandler().handle(null, stepExecution);
stepExecution.upgradeStatus(BatchStatus.COMPLETED);
stepExecutionAggregator.aggregate(stepExecution, stepExecutions);if(stepExecution.getStatus().isUnsuccessful()){if(hasReducer){
reducer.rollbackPartitionedStep();
reducer.afterPartitionedStepCompletion(PartitionStatus.ROLLBACK);}thrownewJobExecutionException("Partition handler returned an unsuccessful step");}if(hasReducer){
reducer.beforePartitionedStepCompletion();
reducer.afterPartitionedStepCompletion(PartitionStatus.COMMIT);}}