

안녕하세요~!
커머스 서비스 개발팀 백엔드 개발자 酒(주)술사 하라버지입니다.
커머스 서비스 개발팀에서 담당하고 있는 전시영역에는 많은 GNB탭이 존재합니다. 그 중에서도 제가 이번에 소개드리고자 하는 부분은 현재 서비스 개편을 준비중인 랭킹GNB와 관련된 내용으로 신규 구축중인 판매랭킹 시스템을 소개해보려고 합니다.
Why consider developing a new architecture?
올리브영 온라인몰 랭킹 GNB는 전체 영역 중 유입량 순위가 상위권일 뿐만 아니라 랭킹 GNB 전시를 통해 상품의 상세페이지로 전환하는 비율이 높은 영역으로 고객(유저)분들께서 많이 활용하고 계시는 영역이지만 현재 판매랭킹에서는 전체를 포함 19개의 카테고리별 판매랭킹만 제공하고 있습니다.
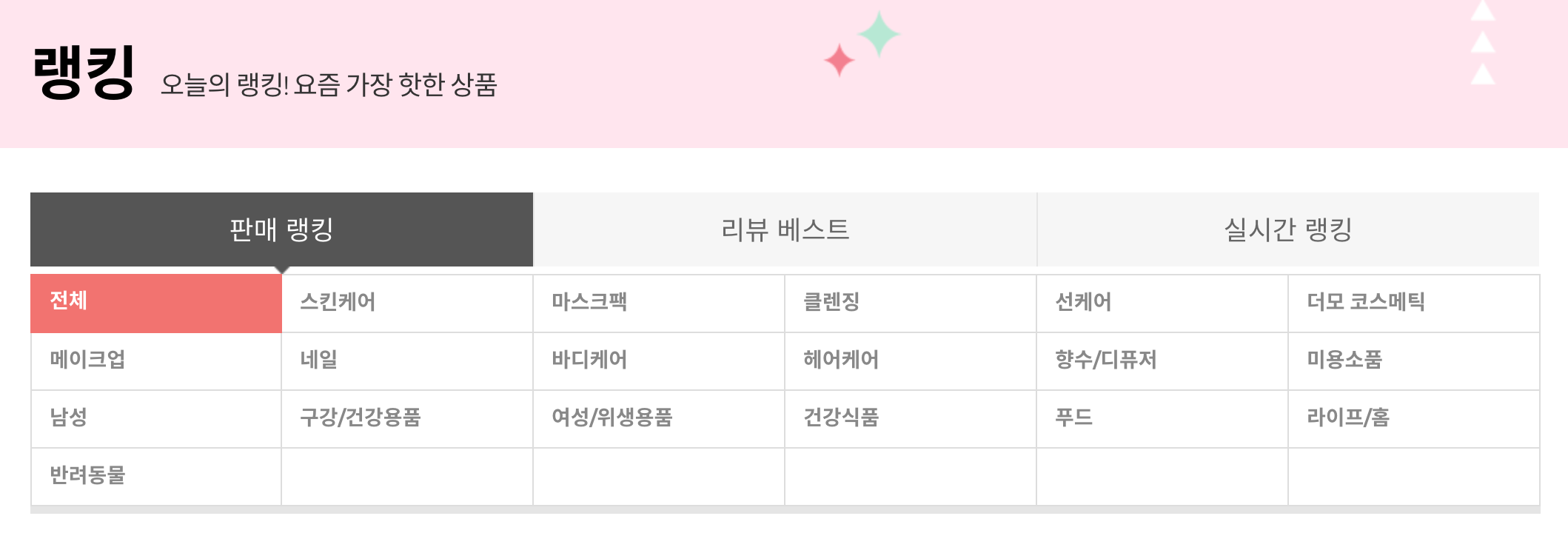
높은 유입률과 전환률을 반영하여 고객(유저)분들에게 다양한 체험을 제공할 수 있도록 기존 대비 더 세분화된 판매 랭킹을 제공하고 더불어 데이터의 전문성 및 신뢰도를 높이는 랭킹 서비스 개편을 기획하게 되었습니다.
But… ?!
클래식 아키텍쳐에서 랭킹서비스를 개편하는데 이슈들이 발견되었습니다 🥲
현재 서비스되고 있는 판매 랭킹시스템의 경우 오라클 프로시져를 사용하여 전체 카테고리와 카테고리별 랭킹을 각각 쿼리로 산출하여 Merge(Union) 하는 방식이었습니다. 랭킹이 세분화되어 산출 기준이 추가된다면 다음과 같은 문제점이 예상되었습니다.
- 기존 프로시져방식으로 추가된 신규 랭킹들을 각각 산출 후 Merge(Union)한다면 동일한 타겟데이터 집계가 불필요하게 반복적으로 발생하고 그만큼 랭킹 배치 수행시간이 지연된다.
- 병렬 배치로 전환하는 경우 수행시간 지연은 축소할 수 있으나 여전히 동일한 타겟데이터 집계가 반복하여 발생되는 부분은 해결 할 수 없다.
- 랭킹 종류가 추가될수록 DB 자원 소비의 비효율성이 증가되는 구조로 확장성측면에서 불리하다.
- 기준별 판매 랭킹을 산출할 때마다 여러 테이블의 조인을 진행하는 방식으로 랭킹 데이터의 산출근거 파악이 어렵다.
위와 같이 예측되는 이슈들을 어떻게 해결할 것인지, 그리고 과연 기존 시스템을 활용하여 요구사항대로 개발할 수 있을지에 대한 많은 고민이 생겨버렸습니다.
그래서 결정했습니다.
How to?
프로덕트측면에서 요구되는 다양한 기준의 랭킹 산출 시스템을 구성하기 위하여 다음의 목표를 가지고 아키텍쳐를 고려하였습니다.
- 랭킹 집계를 위한 별도의 파이프라인을 구성하여 분리된 스토리지를 가져갈 수 있도록 구성하여 요구사항을 수렴하면서 기존 온라인몰에 부하는 최소화
- 스토리지(집계)와 연산자원(산출)을 분리하여 자원의 커플링을 최소화
- 서비스의 확장성 : 랭킹타입 추가, Open Search 연동, 실시간 데이터 Queuing 도입, 분석서비스 연동으로 랭킹산출 시각화등 확장성 고려
위의 목표를 바탕으로 SQS를 이용한 판매데이터 수집용 파이프라인 구성 및 RDB 별도 구성으로 온라인몰 DB와 분리등 여러방안을 모색하였으나 랭킹이 가진 준실시간성을 고려하여 항상 온라인상태로 유지되는 온프레미스 환경이나 클라우드 환경의 애플리케이션 서버를 구성하는 것은 불필요하다고 판단되었고 아래의 AWS 서비스를 이용하여 Serverless 환경으로 구성하기로 방향을 잡았습니다.
AWS Glue
AWS Glue는 데이터 준비 및 ETL (추출, 변환, 로드) 프로세스를 간소화하고 관리하기 위한 다양한 기능을 제공하고 있습니다. 또한 AWS Glue Studio - Visual ETL 기능도 제공하고 있어 비교적 수월하게 시각적으로 ETL 프로세스를 정의할 수 있습니다.
AWS Glue의 대표기능은
- 데이터 카탈로그 구축 및 관리 기능 제공
- 데이터 스키마를 자동으로 추론하는 기능과 연결된 DB에서 데이터 추출, 변환 및 로드 작업등 ETL 데이터 파이프라인 간소화 가능
- 소스에서 데이터의 형식, 열 및 스키마를 자동으로 스캔하고 데이터 포멧을 변환시켜주는 Crawler 제공
으로 볼 수 있습니다.
간략하게 저희팀에서 PoC와 개발을 진행하며 확인한 Glue 사용법을 설명드리면 다음과 같습니다.
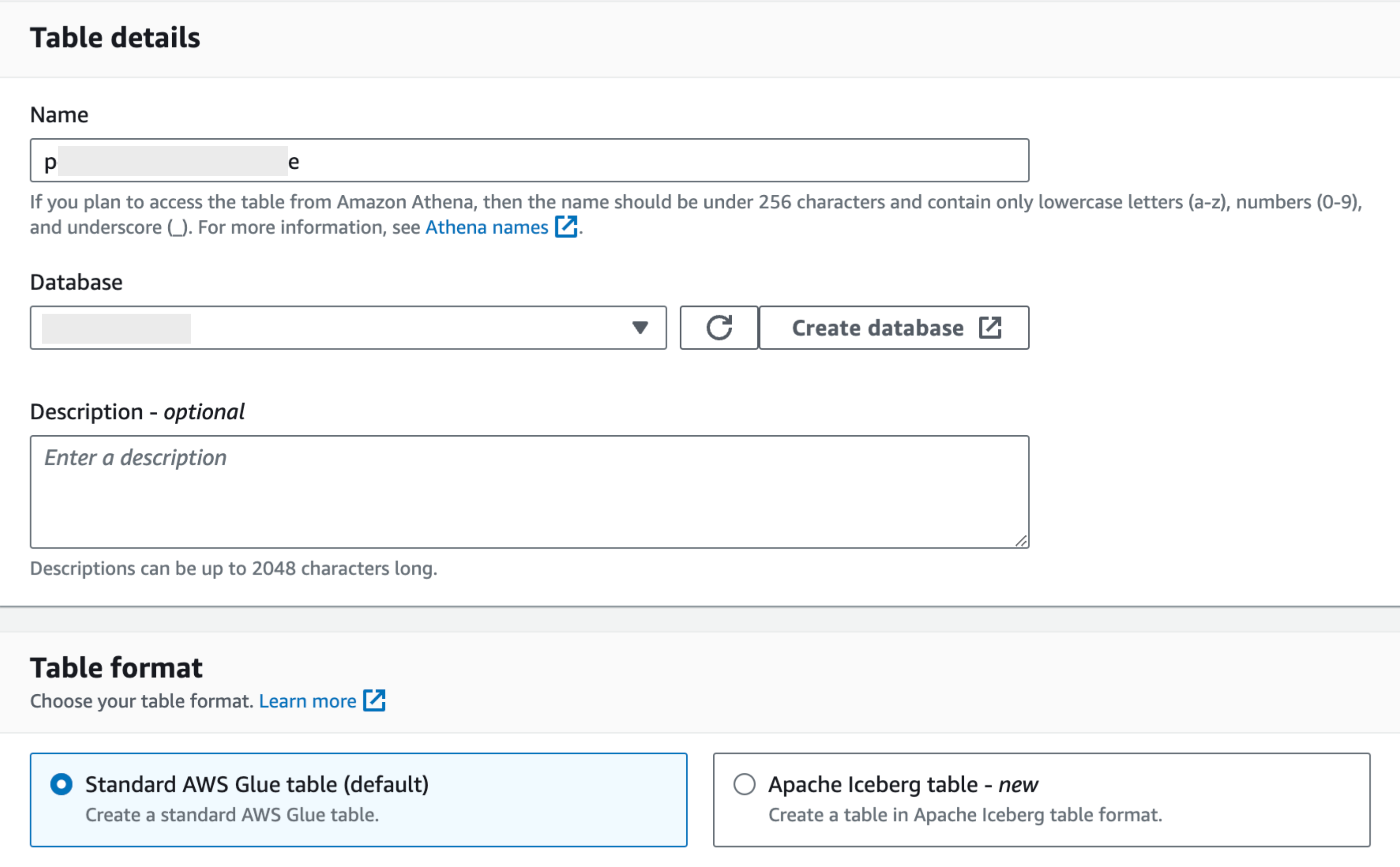
◾️ Glue Database & Table :
ETL 데이터 카탈로그 생성을 위해서는 다음과 같이 Glue Database, Table 생성이 필요합니다.
Database 생성은 비교적 간단한데요, 아래와 같이 원하는 이름을 입력하고 생성해주시면 바로 생성됩니다.
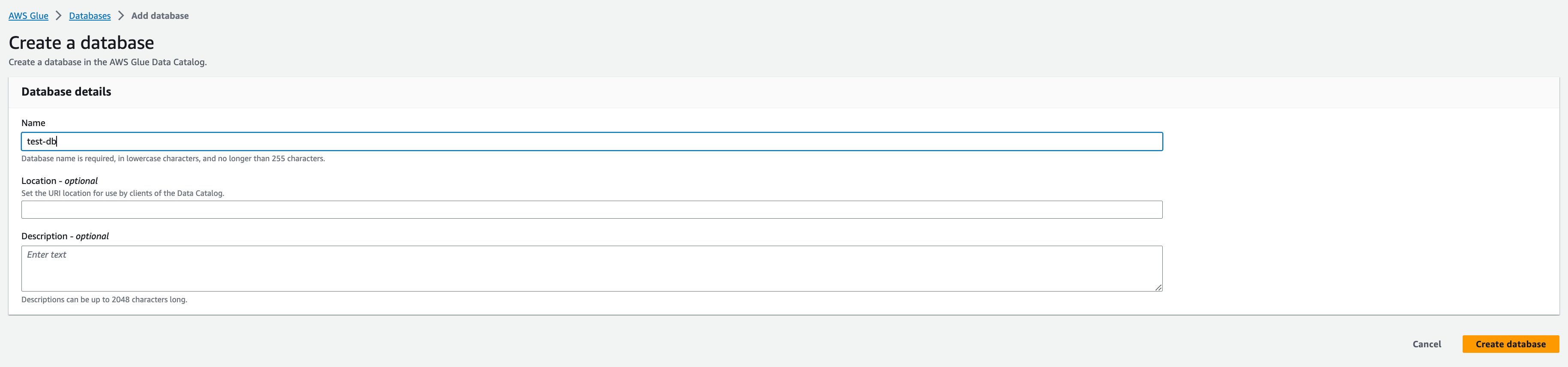
Table 생성은 Kinesis Firehose틀 통해 저장된 S3 버킷의 Raw 데이터를 저장하는 용도로 생성했던 경우를 예를 들어 드리면
- Database : 위에서처럼 사전에 생성해주신 Database를 선택
- Table Format : Default
- Data store : Kinesis Firehose S3 버킷
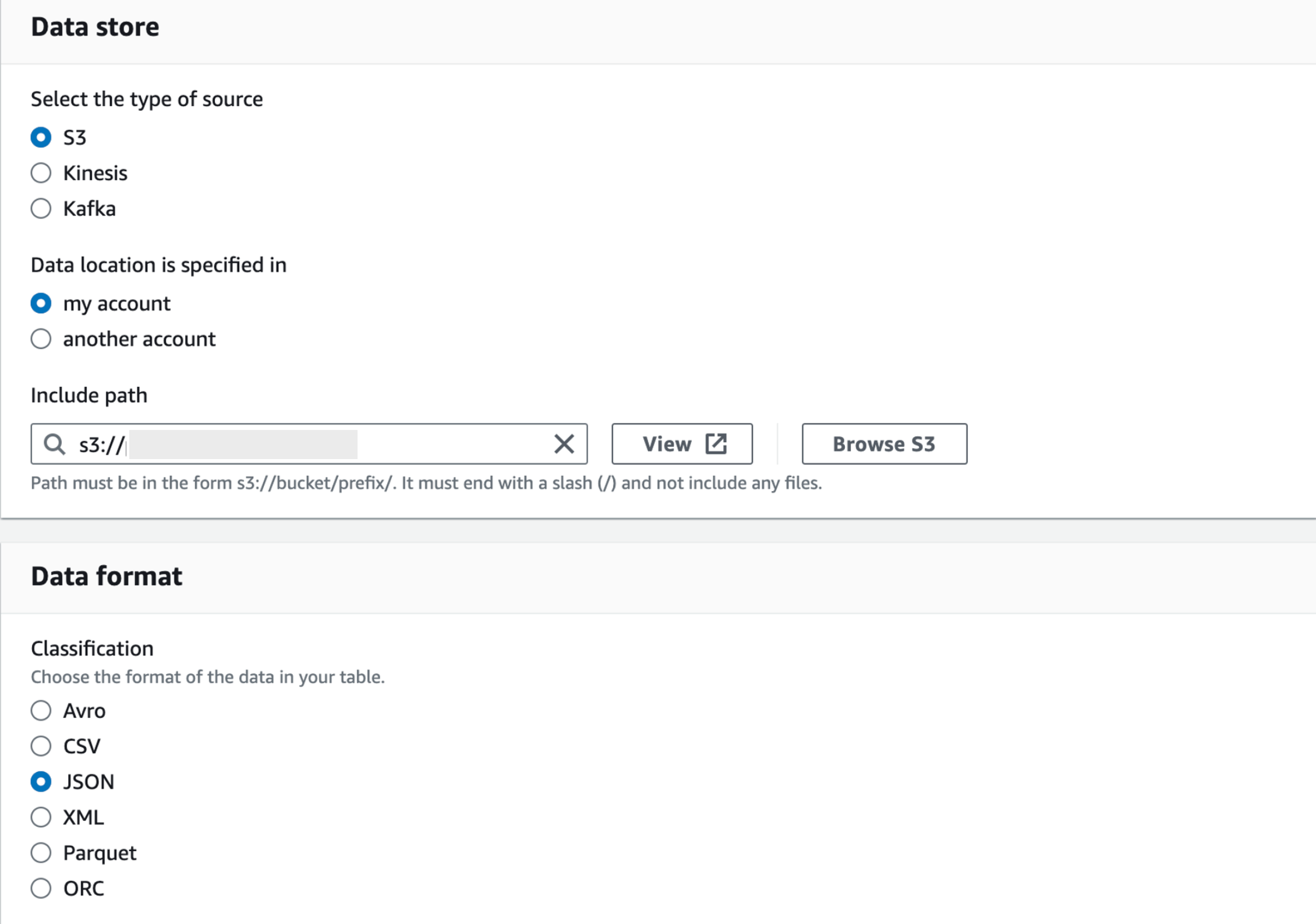
- Data format : 저희팀은 Firehose로 Json 타입의 데이터를 전송하였기때문에 Json을 선택하였습니다.
◾️ Crawler :
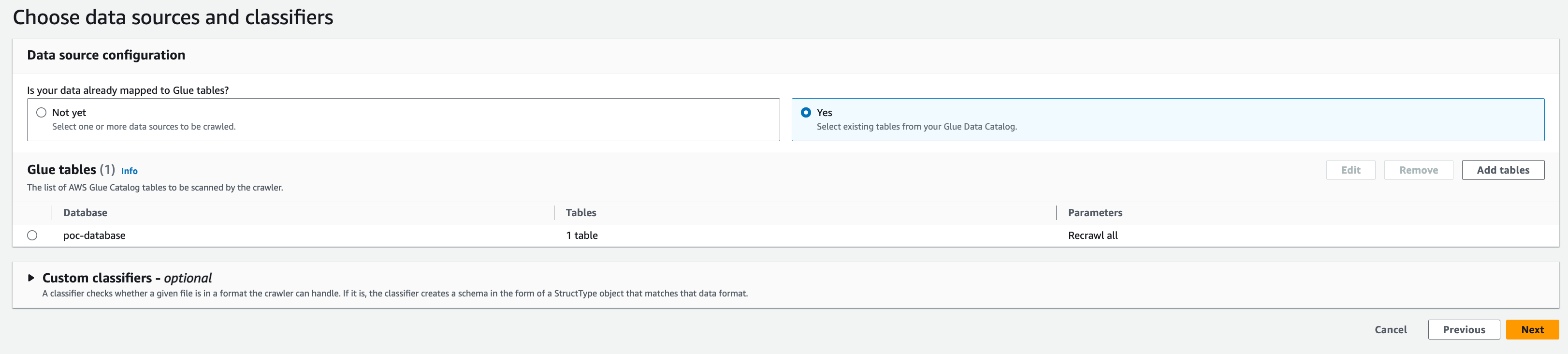
스트리밍 데이터 내 스키마를 스캔하고 변환하기 위한 크롤러 설정은 다음과 같이 진행합니다.
- Crawler 생성 후 이름 입력
- Data source configuration : Yes - Select existing tables from your Glue Data Catalog. (사전에 생성한 Glue Database Table 사용)
- 미리 생성된 Data Catalog를 선택하였기때문에 하단의 Add Table 메뉴를 선택하여 미리 생성해두었던 Glue Table을 매핑 시켜줍니다.
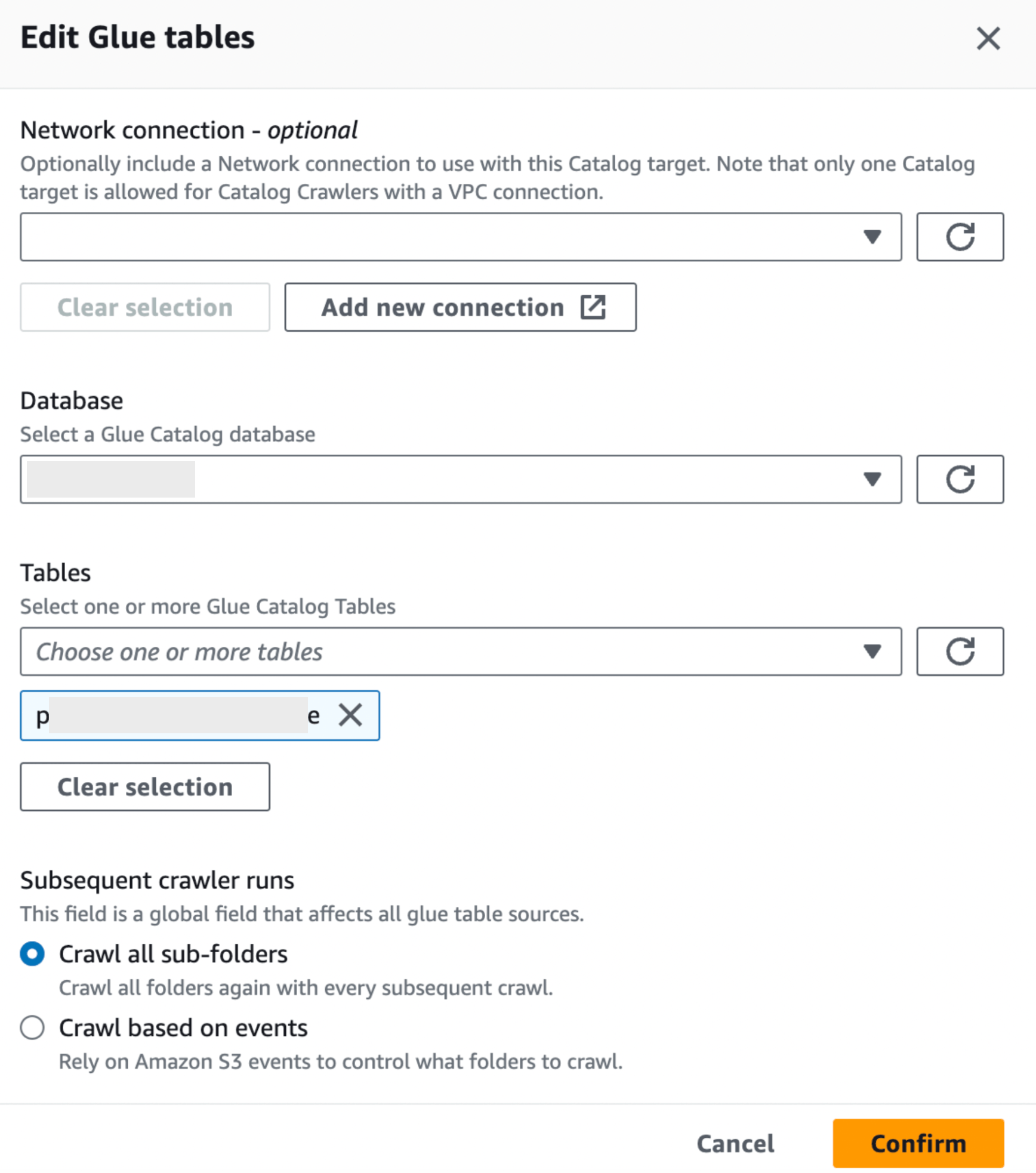
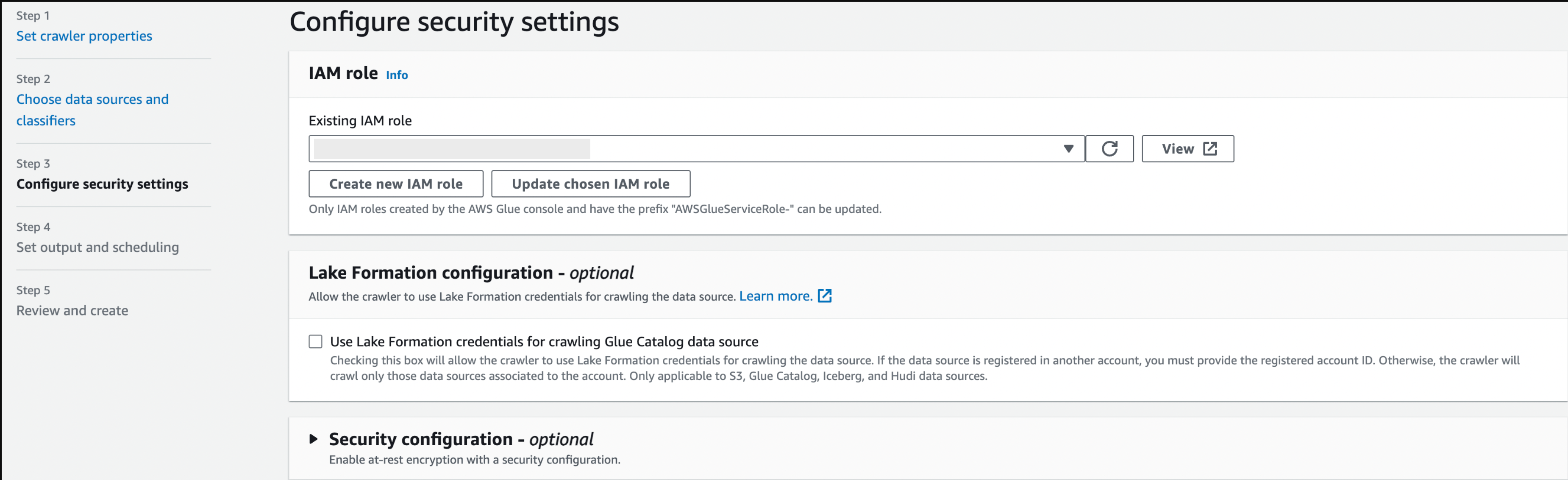
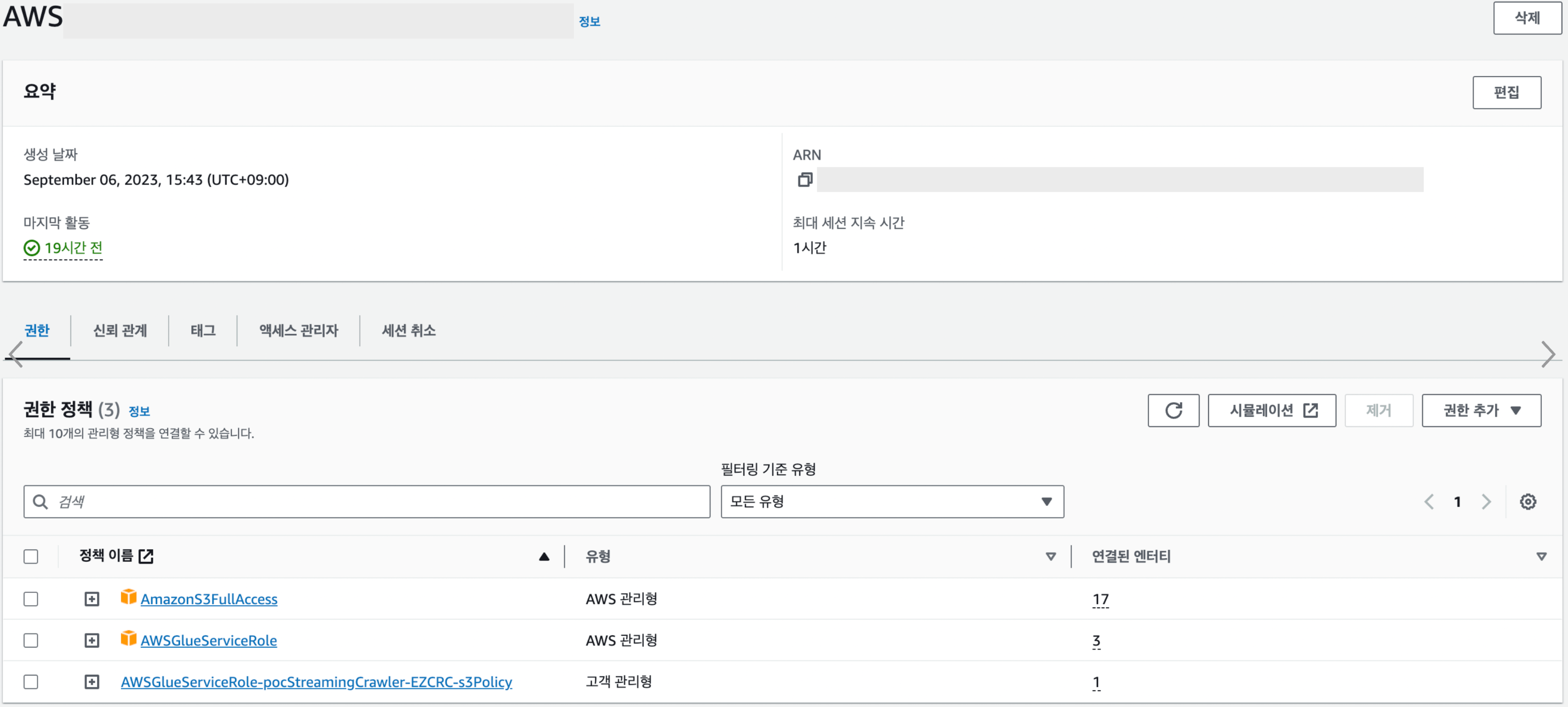
- Crawler의 IAM을 매핑해주고 새로운 role생성해줍니다. (AmazonS3FullAccess 권한 추가)
◾️ Connector
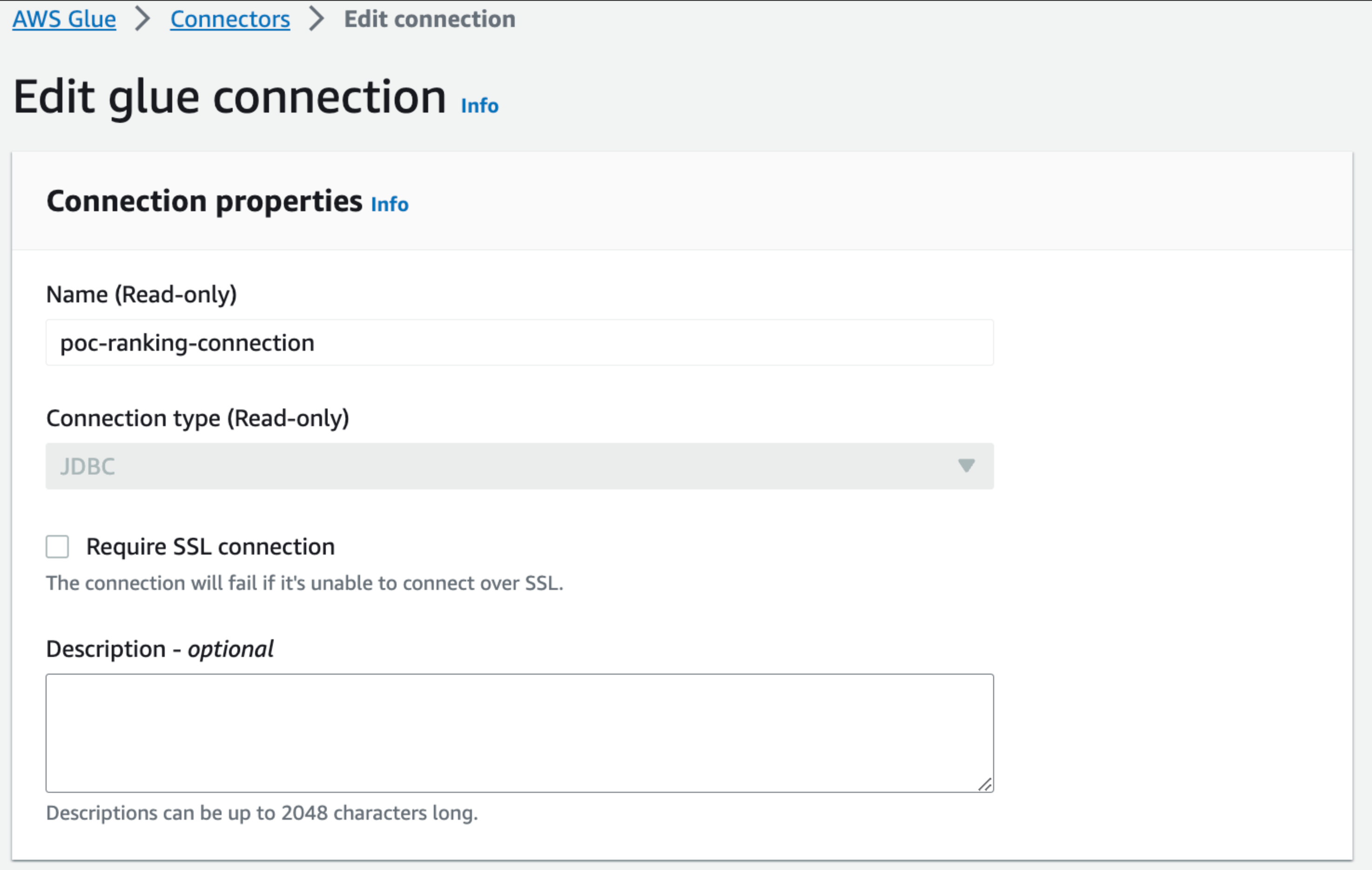
Glue Connector의 경우, ETL Job에서 RDB등 기타 DB에의 연결을 위해서 반드시 추가해야 하는 작업입니다.
- Connector를 추가합니다.
- 접속하고자 하는 DB의 접속정보를 입력합니다. 인증은 AWS Secret Manager에 등록한 정보를 사용할 수도 있으며 직접 ID/PASSWORD를 입력할 수 있습니다.
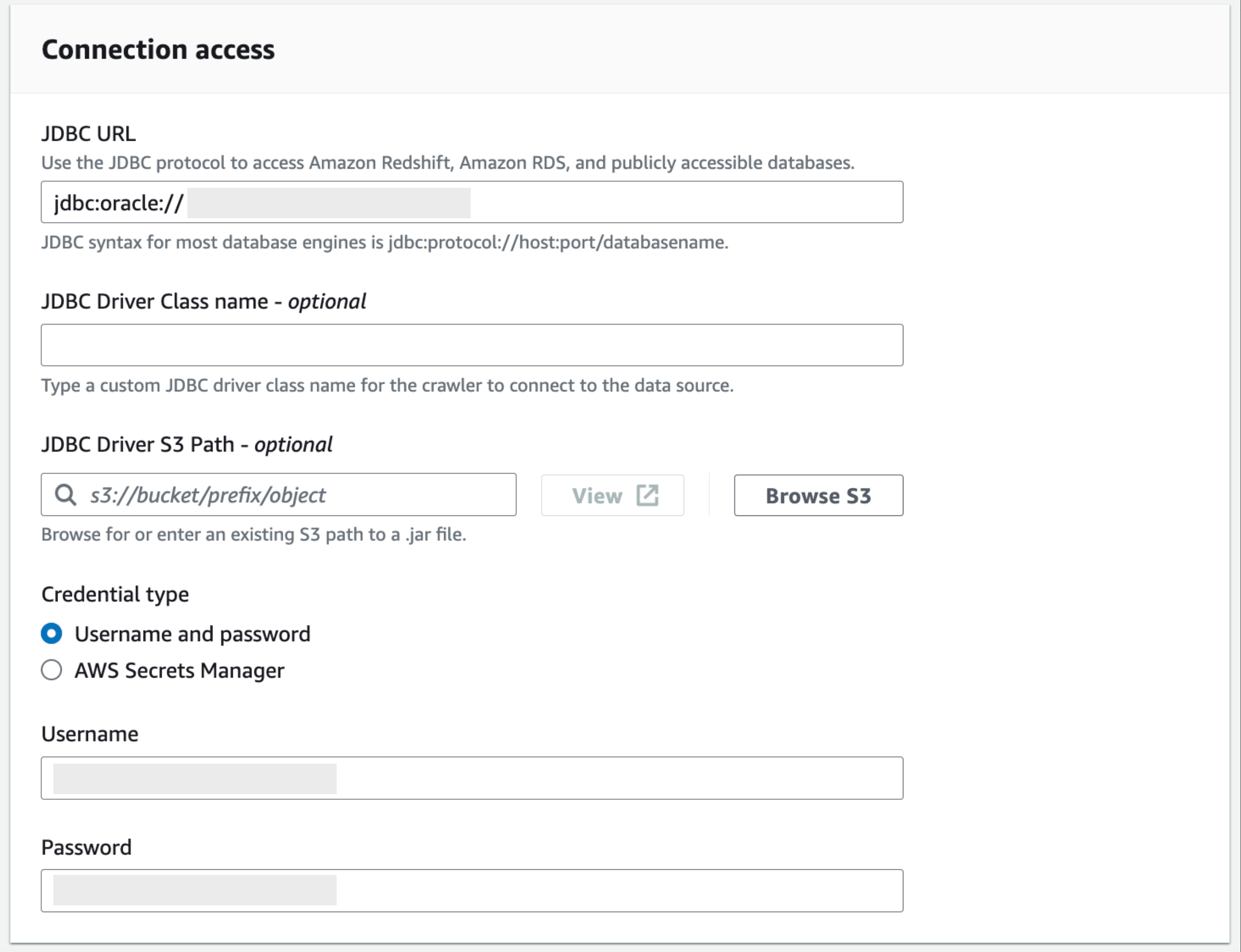
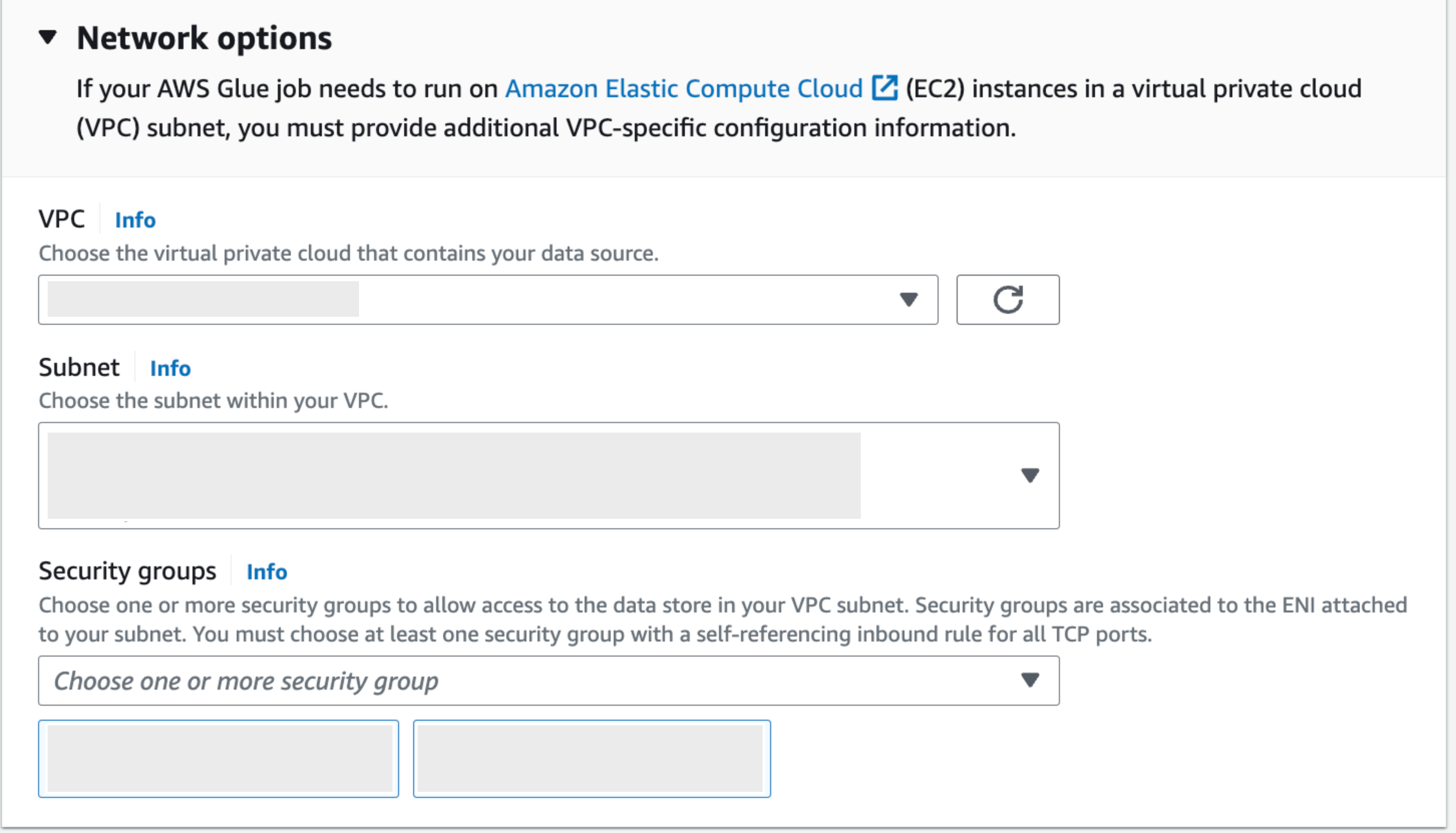
- 네트워크 연결을 위한 VPC 매핑을 진행하여 설정을 완료하고 정상 연결되는지 테스트를 진행합니다.
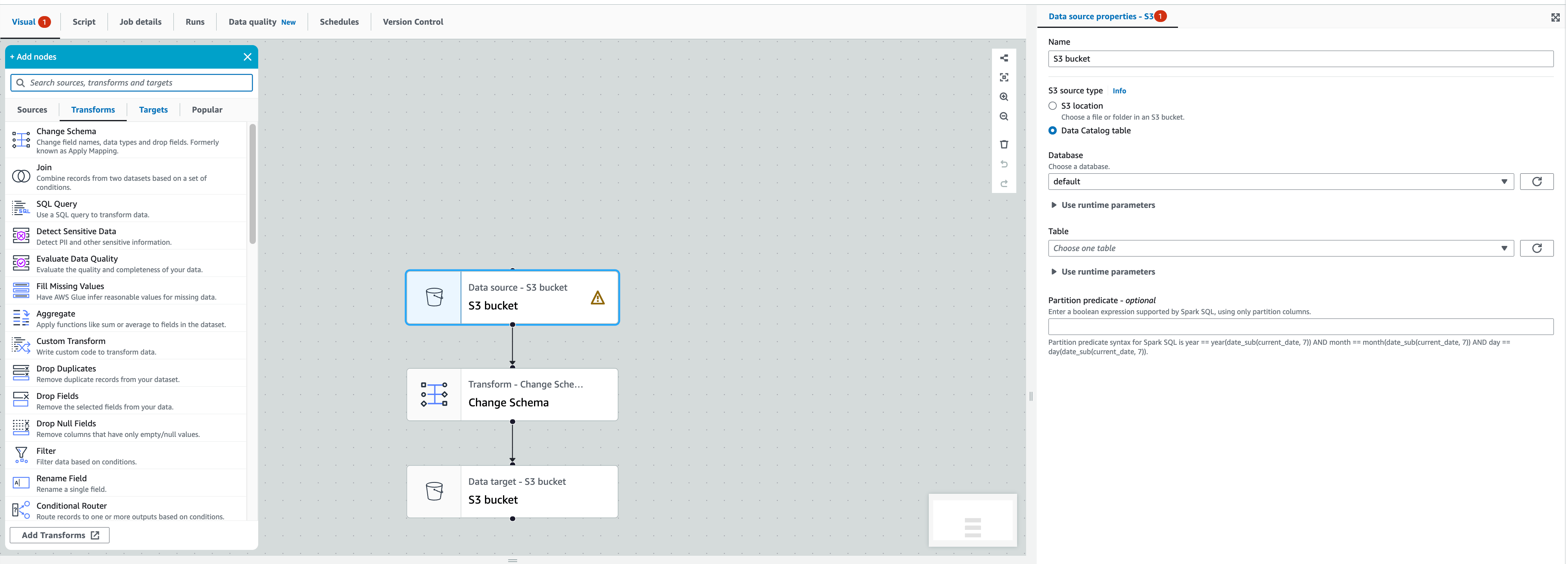
◾️ ETL Job
ETL (추출, 변환, 로드) 프로세스를 AWS에서 제공하는 Visual ETL로 손쉽게 구성할 수 있지만 저희팀에서 원하는 기능을 구현하기에는 추가적으로 제공하는 Python Script를 이용하는 것이 적합하다고 판단되어 Script를 작성하여 구성하였습니다.
주의사항으로는 한 번 스크립트로 ETL Job을 구현하면 다시 Visual 상태로 원복하기 어렵기때문에 필요에 따라 적당한 작성 유형을 선택하시는게 좋습니다.

커스터마이징하며 사용했던 코드들 중 비교적 간단하나 유용했던 코드를 몇가지 공유드립니다. 🙂
- ETL 수행시간 별로 S3 버킷에 저장되도록 동적 Path 적용
- 주기적으로 실행되는 ETL Job의 Hisotry 확인을 용이하도록 수행 시간으로 폴더를 생성되도록 구현하였습니다.
from datetime import datetime
year = datetime.today().year
month = datetime.today().month
day = datetime.today().day
hour = datetime.today().hour
s3_path = "s3 버킷명" + str(year) + "/" + str(month) + "/" + str(day) + "/" + str(hour) + "/"
# Script generated for node S3 bucket
S3bucket_node = glueContext.getSink(
path=s3_path,
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=[],
compression="snappy",
enableUpdateCatalog=True,
transformation_ctx="S3bucket_node",
)- DB 접속 시 Secret Manager에 등록된 정보로 접속정보 구성
- DB 접속 정보는 외부로 유출될 위험성이 있기때문에 Secret Manager에 미리 등록하고 Boto를 사용해서 키를 꺼내오는 식으로 구현하였습니다.
import boto3
# Initialize the AWS Secrets Manager client
secrets_manager = boto3.client('secretsmanager')
# Name of the Secret in AWS Secrets Manager
secret_name = "secret key 입력"
# Get the secret value from Secrets Manager
secret = secrets_manager.get_secret_value(SecretId=secret_name)
secret_dict = json.loads(secret['SecretString'])
# Extracting the value from secret_dict
db_url = secret_dict.get("db url key 입력")
db_user = secret_dict.get("db username key 입력")
db_password = secret_dict.get("db password key 입력")
# Oracle Connection
connection = spark._jvm.java.sql.DriverManager.getConnection(db_url, db_user, db_password)
statement = connection.createStatement()- Data Migration 시 원하는 타겟 데이터만 가져오도록 Dynamic Option 적용
- Visual ETL에서 제공하는 기본 기능으로 쿼리를 작성하는 경우, 예를 들면 1000건의 데이터만 가져오도록 쿼리를 작성하는 경우도 테이블 전체를 가져 온 후 limit처리를 진행하는 문제점이 발견되어 Dynamic 옵션을 적용하였습니다.
query = """SELECT *
FROM SAMPLE_TABLE A
LEFT OUTER JOIN SAMEPLE_TABLE2 B ON A.COLUMN = B.COLUMN
WHERE ROWNUM <= 1000
"""
# Script generated for node JDBC Connection
JDBCConnection_node1 = glueContext.create_dynamic_frame.from_options(
connection_type="oracle",
connection_options={
"useConnectionProperties": "true",
"connectionName": "connection명",
"dbtable": "테이블명",
"sampleQuery": query
},
transformation_ctx="JDBCConnection_node1",
)AWS Athena
Amazon Athena는 데이터 정의 언어(DDL) 및 데이터 조작 언어(DML) 지원하며. 몇몇 예외를 제외하고 Athena DDL은 HiveQL DLL을 기반으로 합니다.
자세한 DML 사용법은 Amazon Athena DML Guide 를 참조하였습니다.
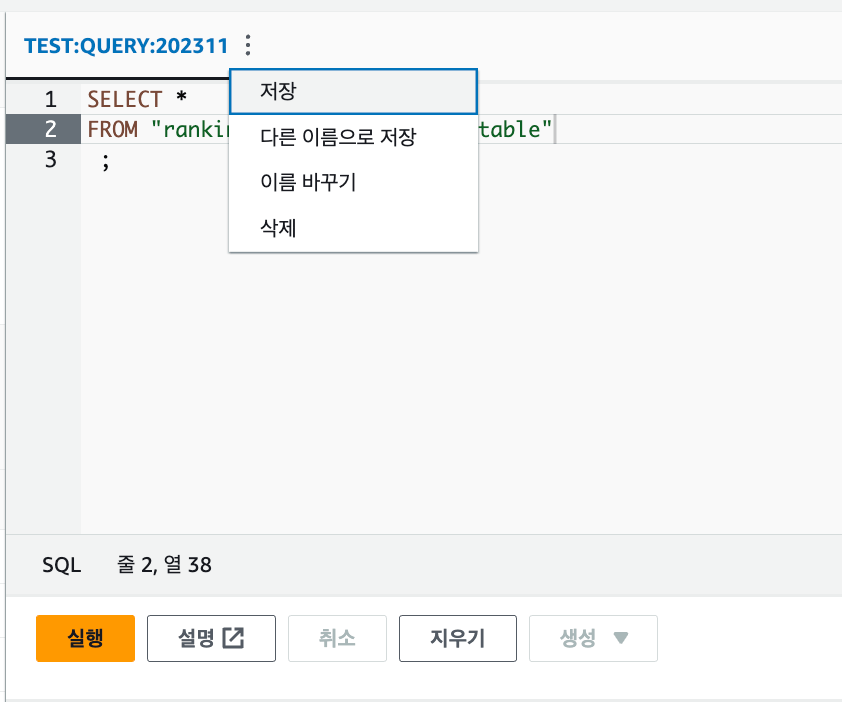
Athena의 기능 중 가장 활용을 많이 했던 기능은 쿼리 저장기능으로 저장 시 발행되는 고유 ID를 이용하여 Step Function등에서 쿼리를 호출하여 사용이 가능합니다.

AWS Step Function
AWS Step Functions은 state machine을 이용하여 여러 AWS 서비스 및 작업 간에 워크플로우를 통합하여 워크플로우를 정의할 수 있고 콘솔을 통해 워크플로우를 시각적으로 디자인하고 수행 시 각 스탭별로 상태를 모니터링할 수 있습니다.
Step Function의 경우, 정의할 수 있는 워크플로우 경우의 수가 워낙 방대하여 이 게시글을 통해서 전부를 공유하기는 어려울 것 같습니다. 🥲
Athena 설명에서 언급했던 저장된 고유키를 이용하여 Step Function에서 쿼리를 수행하는 예제와 Step Function에서 가장 많이 사용했던 Json Path로 input/output parameter를 전달하는 예제를 공유드리겠습니다 😉
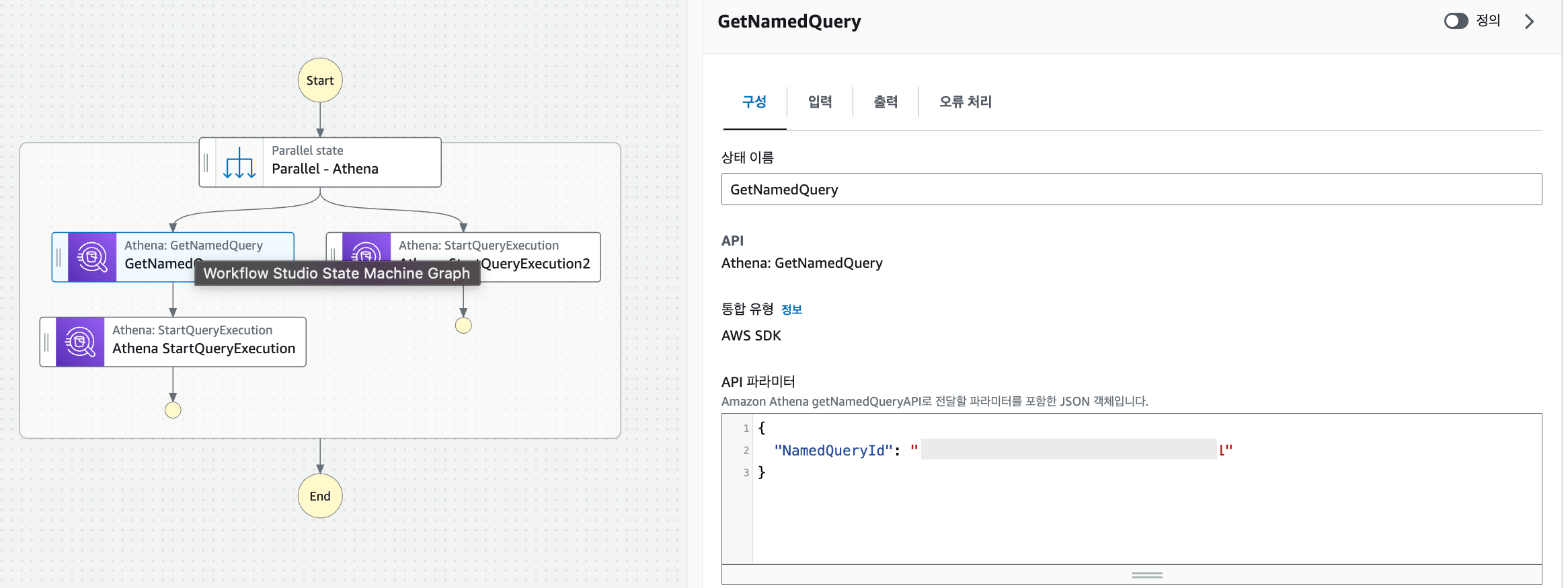
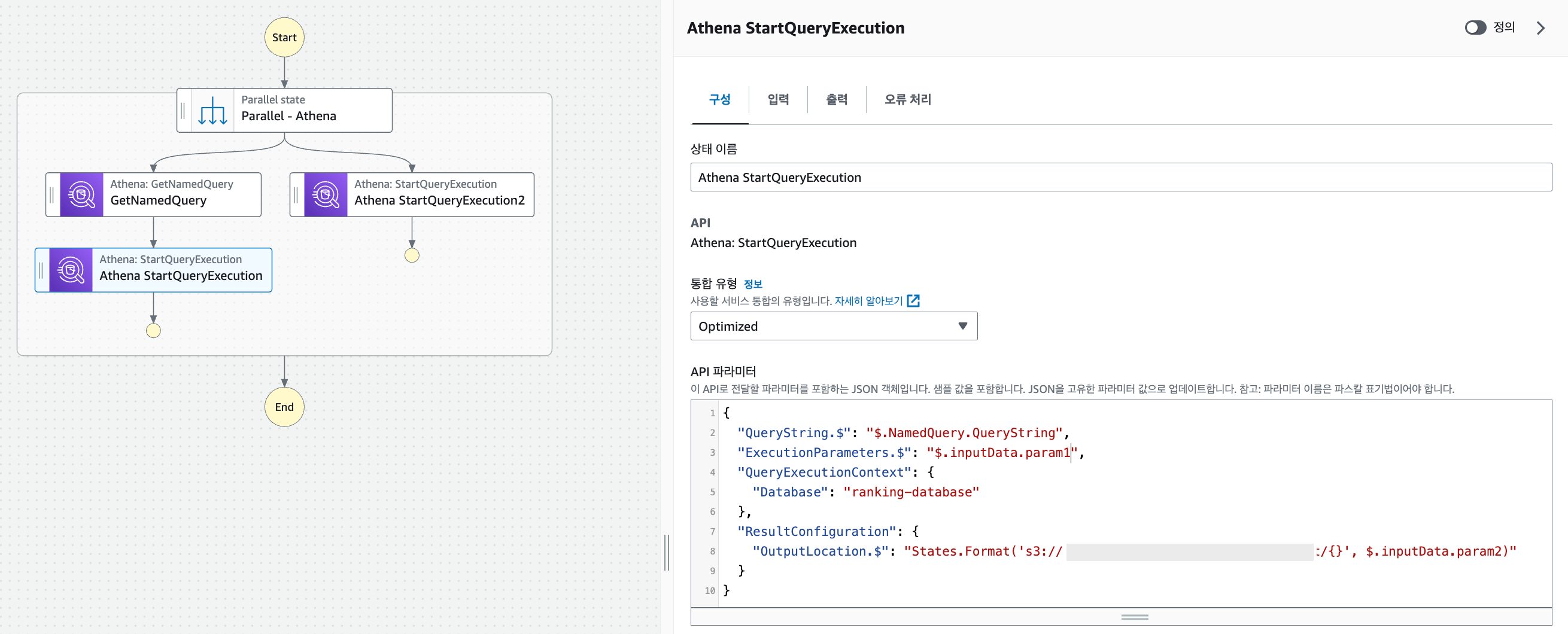
- Athena에 저장된 쿼리를 스트링 형태로 불러오기 위하여 Step Function > GetNamedQuery 작업을 꺼내옵니다.
- GetNamedQuery 작업을 선택하여 API 파라미터를 하기와 같이 저장된 Athena saved query id로 정의해줍니다.
- 다음으로 출력탭으로 이동하여 EventBridge(Step Function 테스트 실행 시에도 전달 가능)등에서 전달될 Input Parameter를 GetNamedQuery 작업 결과값과 합쳐줍니다.

- 위에서 설정한 Output Parameter를 기반으로 실행될 Athena StartQueryExecution 작업을 꺼내어 연결해주고 API 파라미터를 하기와 같이 지정해줍니다.
- QueryString : StartQueryExecution에서 수행될 쿼리를 스트링 형태로 입력, 위의 예제에서는 GetNamedQuery의 수행 결과인 Athena에 저장된 쿼리가 입력됩니다.
- ExecutionParameters : StartQueryExecution에서 수행될 쿼리에 Binding Parameter가 지정된 경우, 이 항목에 입력된 값으로 대체됩니다. 위의 예제에서는 input parmeter를 이용하여 유동적으로 parameter를 사용할 수 있게 설정하였습니다.
- OutputLocation : 수행된 결과 csv파일을 저장할 위치를 지정한다. 위의 예제에서는 해당 Path 역시 Step Function 수행 시 전달되는 Parameter로 유동적으로 지정되게 됩니다.
- 기타 자세한 Step Function의 API 파라미터 참고 : Amazon Step Function API Parameter Guide
- Event Bridge에서 호출 또는 Step Function 직접 실행 시 위에서 사용한 형식과 일치하는 Json Path를 전달하면 각각의 Json path가 매핑되어 실행됩니다..
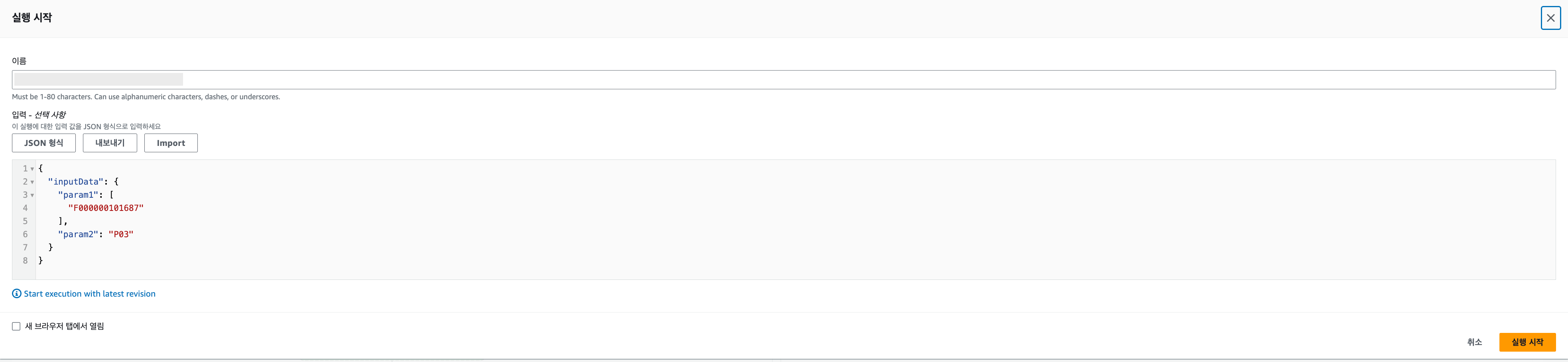
Result!!!
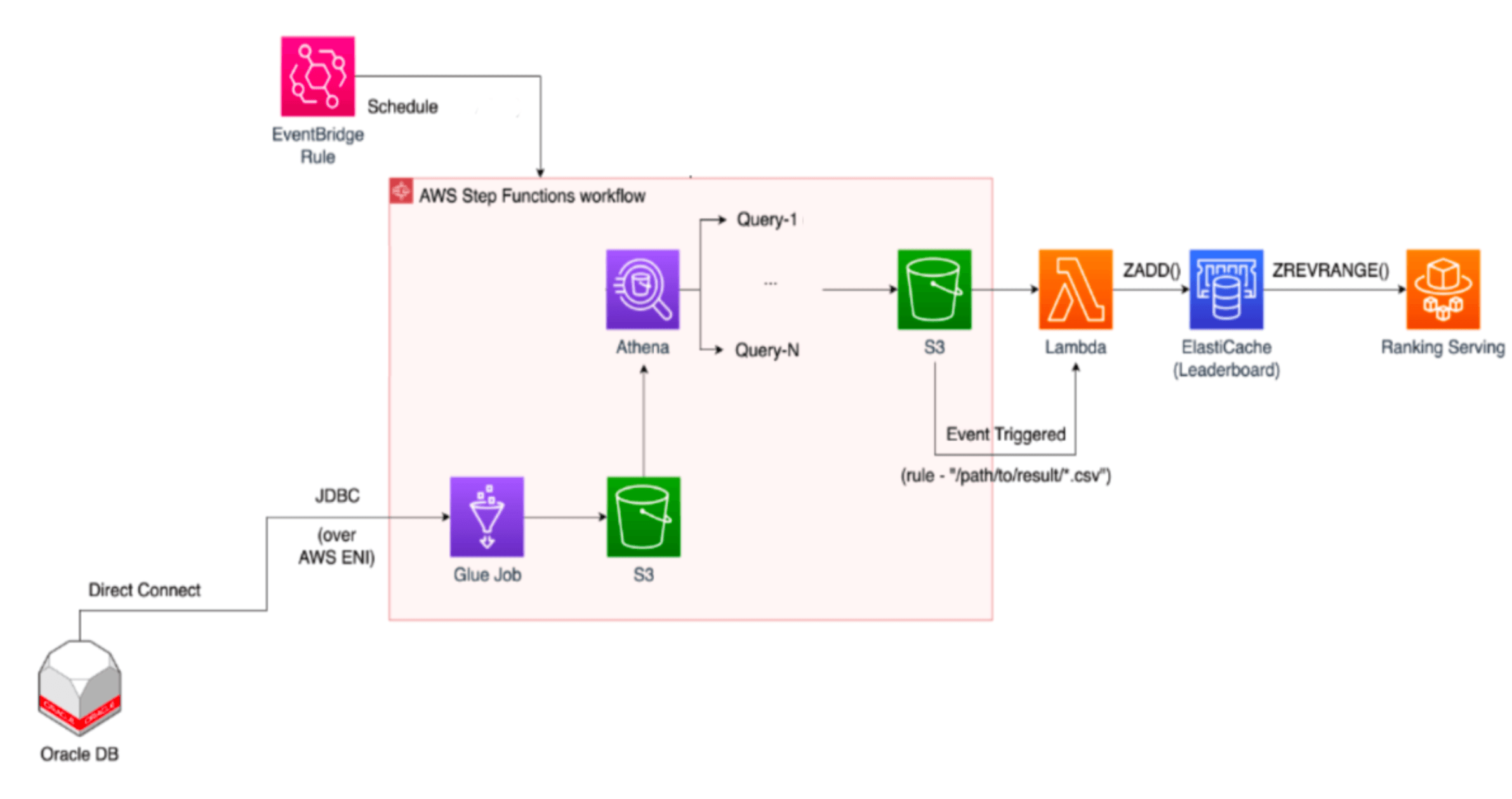
- Glue : 기존 클래식 아키텍쳐 RDB에서 랭킹 산출용 데이터의 ETL을 진행하고 Parquet 파일형식으로 전환하여 S3 버킷에 저장
- Athena : S3에 적재된 parquet 파일에서 다양한 기준으로 랭킹 산출 후 S3 버킷에 CSV파일로 저장
- Step Function : Glue & Athena Pipe Line 구성
위와 같이 Glue, Athena, 그리고 Step Function을 이용하여 요구사항에 부합하는 기능을 하나씩 개발하였고 최종적으로 아래와 같이 랭킹시스템 신규아키텍쳐를 완성할 수 있었습니다.🎉
마무리
아직 고객(유저)분들에게 오픈전이기때문에 개선된 랭킹 웹페이지를 공유드리지 못하는게 많이 아쉽습니다.
하지만 곧 오픈 예정이니 그때까지 많은 기대와 관심부탁드립니다.🙂🙃🙂
올리브영은 앞으로도 쭈~욱! 고객(유저)분들에게 더 나은 경험을 제공해드리고 만족도 높은 시스템을 서비스할 수 있도록 최선을 다하겠습니다.
감사합니다.
References
