
안녕하세요. B2B 물류 스쿼드의 백엔드 개발자, 시나브로우입니다.
저희 B2B 물류 스쿼드에서는 올리브영의 오프라인 발주와 물류 시스템을 담당하고 있습니다.
오프라인 개발 환경에서는 모놀리식 기반의 레거시 시스템에서 MSA 기반의 신규 서비스로 계속해서 개편 중입니다.
현재 발주와 물류 프로세스 개선의 일환으로 AWS MSK Connect 도입을 하고 있습니다.
오프라인 환경에서 AWS MSK Connect를 중심으로 한 비동기 통신 메세지 큐(Asynchronous Communication)와 CDC(Change Data Capture)의 도입은 큰 변화를 가져왔습니다.
이 변화는 일부에서 우려의 목소리도 있었습니다만
이번에는 내부 우려를 완화하고 AWS MSK Connect 에 대한 이해를 돕기 위해 저희 스쿼드에서 진행하고 있는 효과적인 운영 전략을 소개하겠습니다.
MSK 와 MSK Connect 의 기본 구조
MSK 에 대한 우려와 운영 전략을 소개하기에 앞서, MSK 를 이해하는데 도움이 되도록 간략하게 설명드리겠습니다.
MSK(Amazon Managed Streaming for Apache Kafka) 는 AWS에서 제공하는 완전 관리형 서비스인 'Apache Kafka' 를 지칭합니다.
MSK 를 제대로 이해하기 위해서는 Kafka 의 구조에 대한 이해가 필요합니다.
Kafka 기본 구조
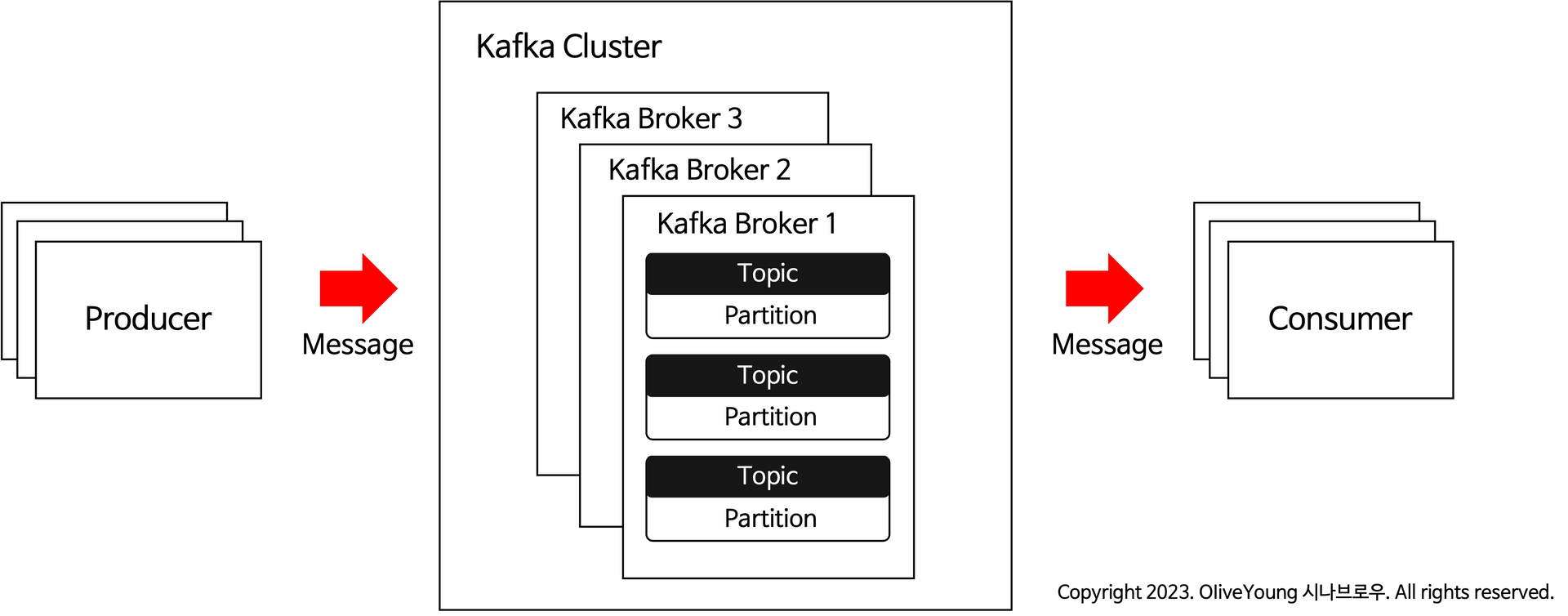
Kafka 는 Broker, Producer, Consumer 로 구성되어있습니다.
Producer 는 메세지를 Kafka Cluster 에 전송하는 역할을 담당합니다. 여기서 메세지는 데이터를 의미합니다.
Kafka Cluster 는 여러 Broker 들로 구성되어 있으며, 각 Broker 내부에는 각각의 Topic 이 있습니다.
이 Topic 을 통해 메세지를 주고받을 수 있습니다.
마지막으로, Consumer 는 이 메세지를 받아들이는 역할을 하며, 받은 메세지를 처리하고 소모합니다.
MSK(Kafka) 의 특징을 간략하게 정리하면 다음과 같습니다.
- Data Consistency (데이터 일관성)
- 애플리케이션은 토픽을 통해 데이터를 주고받기 때문에 데이터 무결성을 보장.
- Asynchronous Communication (비동기 통신)
- Produce to Broker, Broker To Consumer 비동기 통신 지원.
- Message Persistence (메시지 유지)
- Topic Message 기본 7일 저장, re-read 또는 재처리 가능.
- 대량의 데이터 송수신에 유리
- Peak Throughput(MB/s): 605MB/s
- P99 Latency(ms): 5ms(200MB/s load)
다음으로 MSK Connect에 대해 말씀드리겠습니다.
MSK Connect는 외부 시스템과 Kafka 클러스터 간 데이터를 손쉽게 주고받을 수 있는 서비스입니다.
MSK Connect는 CDC(Change Data Capture) 기능을 제공하는데,
CDC는 데이터베이스의 변경된 데이터를 추출하여 비동기적으로 복제하는 기법입니다.
CDC 기능은 MSK Connect를 도입하는 데 있어 주요 동기 중 하나였습니다.
MSK Connect 구조

Source Connector 는 Producer 의 역할을 합니다.
그리고 Sink Connector 는 Consumer 의 역할을 합니다.
Connect 가 제공하는 플러그인을 활용하면, 다른 시스템 간의 호환성을 최대화하며, 이들 시스템을 쉽게 연동하여 사용할 수 있습니다.
글 작성 시점을 기준으로, Connect 가 제공하는 플러그인은 총 197개이며,
Debezium CDC 플러그인 외에도 Elasticsearch, MongoDB, S3, Datadog, BigQuery, Redshift 등과 같은 잘 알려진 외부 자원과 연동할 수 있는 플러그인들을 제공합니다.
Connect 의 특징을 간략하게 정리하면 다음과 같습니다.
- RDMS, NoSQL 에 대한 Source/Sink Connector 지원
- 이기종 간 CDC 지원
- 시스템 간 호환성이 좋음
저희 스쿼드는 이러한 특성을 활용하여 MSK Connect를 도입하고,
CDC 기법으로 데이터를 실시간으로 추출하며 Consumer 에서 데이터를 처리함으로써 배치 시스템의 사용을 줄이고 있습니다.
다음 세션에서는 본격적으로 MSK에 대한 내부 우려를 완화하고, 효과적인 운영 전략을 소개하도록 하겠습니다.
MSK 가 죽는다면?
MSK 클러스터는 여러 broker 로 구성되며, 다중 가용 영역(Multi-AZ)에서 Kafka broker 를 운영합니다.
특정 broker 에 문제가 발생해도 다른 broker 에는 영향을 주지 않고, broker 장애 발생 시, 해당 broker 는 자동으로 복구됩니다.
Topic 을 생성할 때 'Replication Factor' 를 설정하면,
하나의 브로커에 문제가 발생하더라도 다른 브로커에 복제본이 존재해 데이터 손실을 막을 수 있습니다.
예를 들어, 'Replication Factor' 를 3으로 설정하면,
Topic은 'Leader Partition' 1개와 'Follower Partition' 2개로 구성됩니다.
여기서 Topic의 원본이 'Leader Partition'이며, 복제본은 'Follower Partition'입니다.
Partition 은 다수의 브로커에 분산 저장되고, 'Leader Partition'이 저장된 브로커에 장애가 발생하면,
다른 브로커에 저장된 'Follower Partition' 이 'Leader Partition' 으로 승격됩니다.
이 'Leader Partition' 으로 승격과정에서 해당 Partition 이 위치한 브로커 또한 Topic 의 리더 브로커로 변환됩니다.
'Leader Partition' 으로 승격된 'Follower Partition' 은 장애가 발생한 'Leader Partition' 을 대체, 서비스를 계속 유지할 수 있습니다.
또한, 'Leader Partition' 으로 승격 후, 'Leader Epoch' 가 발생하며,
변경된 리더의 정보가 복구된 팔로워로 전달되고, 장애 시간 동안 소실된 데이터도 변경된 리더를 통해 복구가 가능합니다.
쉽게 말하면, 'Leader Epoch' 를 통해 장애 후 복구 과정에서 리더와 팔로워 간의 메시지 일관성을 유지하며 데이터 손실을 방지합니다.
정리하면, MSK 클러스터와 'Replication Factor' 설정을 통해 데이터를 여러 브로커에 분산 저장하며,
장애 발생 시 다른 브로커에 저장된 'Follower Partition' 을 'Leader Partition' 으로 승격하여 대체함으로써, 서비스를 지속적으로 유지할 수 있습니다.
그렇지만, 'Replication Factor' 설정 시 주의가 필요하며, 'Partitions' 설정과의 관계도 함께 고려해야 합니다.
Topic 의 Partitions 과 Replication 의 연관 관계
Topic 은 레코드를 논리적으로 저장하는 단위로, 하나의 Topic 은 최소 하나 이상의 Partition 으로 구성됩니다.
앞서 언급했듯이, Replication Factor 를 설정해 MSK를 안정적으로 운영할 수 있지만, 복제본이 저장될 용량도 염두에 둬야 합니다.
설정한 Replication Factor 값 만큼의 배수로 저장 공간이 필요하게 됩니다.
예시로, Replication Factor가 2라면 저장 공간이 2배, 3이라면 3배 필요합니다.
또한, Partitions 설정도 Replication Factor 설정과 함께 고려되어야 합니다.
데이터의 양이 많은 Topic의 경우, Partitions 설정을 통해 여러 저장 공간으로 데이터를 분산 저장하며, 이를 통해 전체 처리율을 향상시킬 수 있습니다.
여기서 Topic 의 Partitions 설정은 Replication Factor(복제 계수) 와 상호 작용하며, 총 저장소 개수(Segment Size)를 결정합니다.
예를 들어, Partitions 가 4 이고 Replication Factor 가 2인 경우, 총 8개의 저장소가 생성되는 방식입니다.
간단히 말해, 두 설정이 곱해져 총 저장소 개수가 결정됩니다.
따라서, 데이터의 특성과 크기에 따라 Partitions 설정과 Replication Factor 설정이 적절히 이루어져야 합니다.
또한, Replication Factor 설정에 의해 늘어나는 Topic 데이터 용량 문제를 해결하기 위한 데이터 경량화 작업도 필요합니다.
저희 스쿼드는 Topic 데이터 용량을 줄이기 위해 Avro 포맷을 활용하고 있습니다.
Avro 포맷을 이용한 데이터 경량화 작업에 대해서는 뒷 세션에서 좀 더 상세히 다루도록 하겠습니다.
MSK Connect 가 죽는다면?
CDC(Change Data Capture) 수행 중 MSK Connect가 실패할 경우, '장애 시간 동안 대상 데이터가 소실되지 않을까?' 라는 우려가 있었습니다.
Oracle을 기준으로, CDC를 사용하면 DB의 SCN(System Change Number) 정보가 Connect에 저장됩니다.
SCN 정보는 amazon_msk_connect_offsets[CONNECTOR_NAME][CONNECTOR_ID] 와 같은
connect-offsets internal topic으로 저장되며, 이는 internal topic으로 관리됩니다.
SCN (System Change Number) 는 Oracle 데이터베이스의 모든 트랜잭션을 일련번호로 나타낸 CDC 데이터 버전 값이라고 보면 됩니다.
Oracle 데이터의 변경 정보는 이 고유한 SCN을 통해 알 수 있게 됩니다.
MSK Connect가 장애 이후 복구되면, MSK Connect 는 저장된 SCN 값을 기준으로 마지막으로 처리된 이후의 변경 내용을 재처리합니다.
이러한 방식으로 MSK Connect는 장애 발생 시에도 데이터 소실 없이 CDC를 지속적으로 수행할 수 있습니다.
Avro Format 과 AWS Glue Schema Registry 를 사용한 효과적인 데이터 압축
앞서 언급했듯이, Replication Factor를 통해 복제본을 저장하게 되면 데이터 저장 용량이 증가합니다.
또한 대량의 데이터를 일반적인 Json Format으로 저장하면, MSK에 상당한 저장 공간이 필요합니다.
따라서 MSK에 저장되는 데이터는 경량화할 필요가 있습니다.
저희 스쿼드는 데이터를 효율적으로 경량화하고 저장하기 위해 Avro Format 과 AWS Glue Schema Registry 를 활용하고 있습니다.
MSK Connect 에 저장된 Avro Format 메세지

직렬화해서 저장된 데이터의 형태는 위의 그림과 같습니다.
MSK Connect 의 CDC 로 추출한 데이터의 메타 정보는 AWS Glue Schema Registry 에 저장합니다.
메타 정보 이외의 데이터의 실제 값은 binary 형태로 위와 같이 topic 에 저장됩니다.
MSK Connect 의 데이터 저장 및 데이터의 메타 정보 저장에 대한 자세한 플로우는 아래 그림과 링크를 참조하세요.
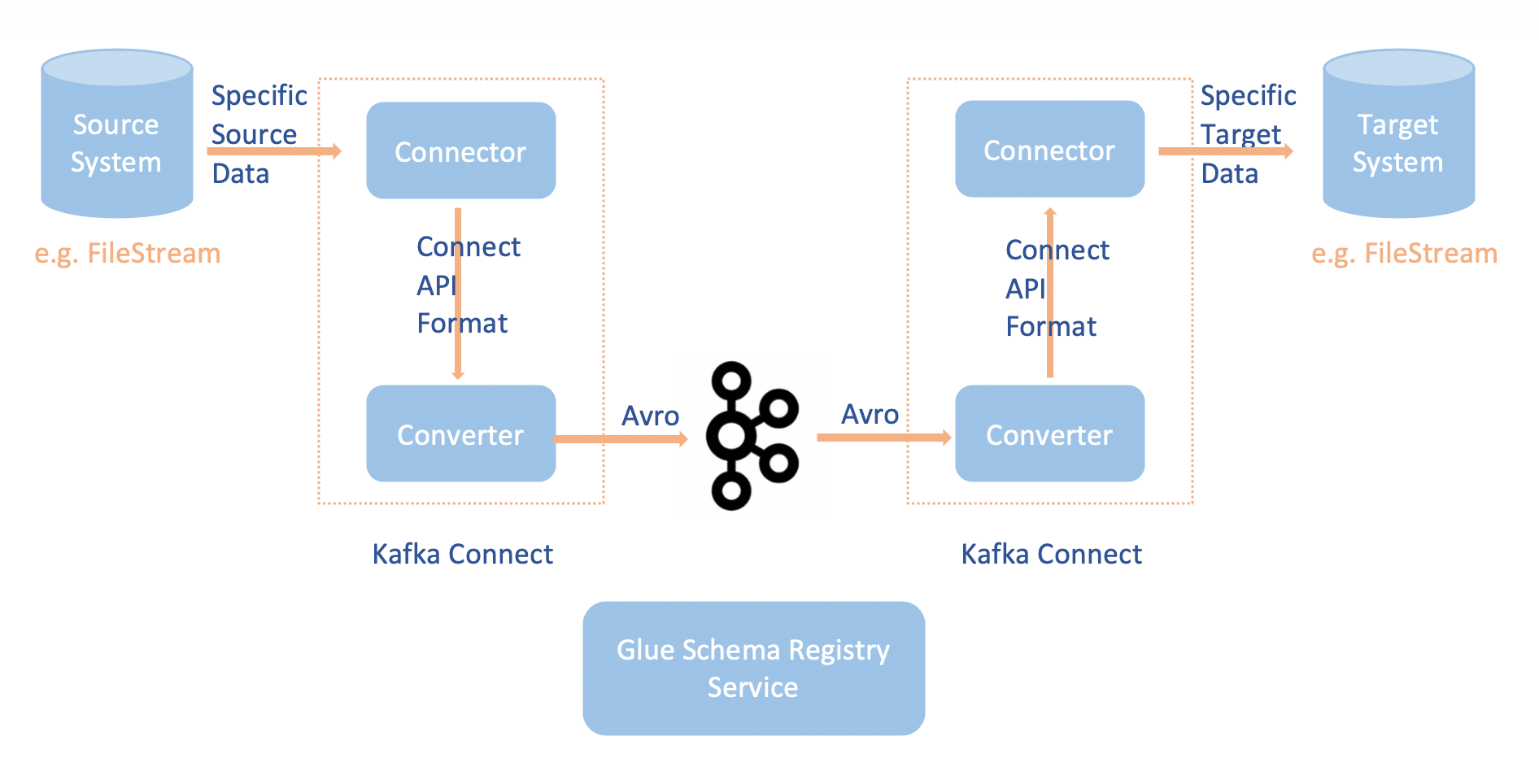
데이터의 메타 정보는 AWS Glue Schema Registry 의 Schema 로 생성되며, 이 Schema 정보는 고유 Schema Id 를 통해 호출이 가능합니다.
Schema 와 Schema Id 는 캐시되기 때문에 MSK Connect 를 통해 동일한 Schema 로
이벤트를 계속 생성하는 한 Schema Registry 와 다시 통신할 필요가 없습니다.
topic 에는 데이터와 함께 Schema Id 가 저장되기 때문에
실제 Schema 정보를 레코드 마다 저장하지 않는다는 점에서 Json Format 보다 데이터 압축효과가 큽니다.
Avro 와 Schema Registry 를 활용한 자세한 정보는 Confluent 공식 문서를 참조하는 것이 좋습니다.
https://www.confluent.io/blog/schemas-contracts-compatibility/
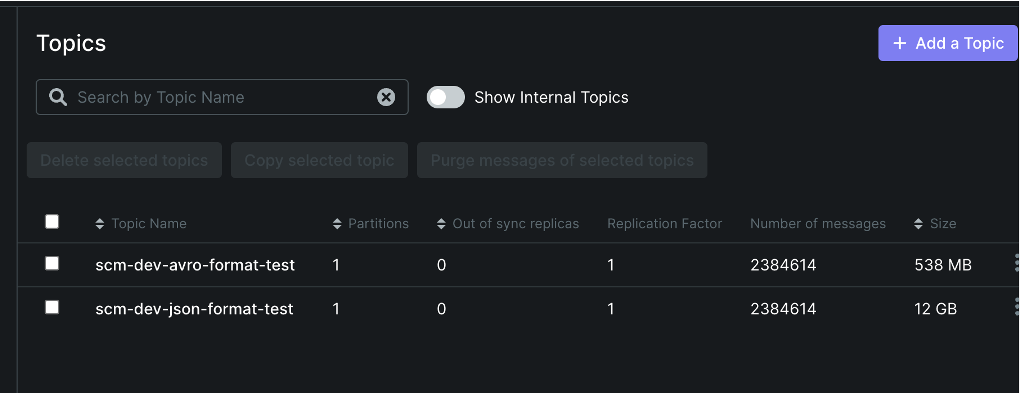
실제 topic 에 저장되는 데이터 크기를 비교해보았습니다.
동일한 데이터 약 238만 건을 기준으로, Json Format 은 12G이며 Avro Format 은 538MB로 확인되었습니다.
Avro Format 으로 데이터를 24배 압축한 셈이죠.
물론 topic 에 저장되는 메세지 크기는 필드의 수, 명칭의 길이, 값의 길이 등에 따라 변할 수 있지만,
Json Format 과 Avro Format 간의 용량 차이는 뚜렷하게 나타났습니다.
Avro Format 이점을 간략하게 정리하면 다음과 같습니다.
- 메세지 용량 감소
- Json Format 보다 빠른 전송 가능
- 스키마 중복 제거
Topic 메세지 Dead Letter 처리
'Broker에서 Consumer 로 메세지를 전달하는 과정에서 네트워크 문제로 메세지 소실될 수 있지 않을까?' 라는 우려도 있었습니다.
그러나, Consumer는 메세지를 정상적으로 받으면 Ack(Acknowledgment)을 보내며, 받지 못했을 경우 Broker가 메세지를 재전송할 수 있습니다.
'enable.auto.commit' 옵션을 이용해 Ack를 자동 또는 수동으로 처리할 지 선택이 가능합니다.
'enable.auto.commit' 값을 false 로 지정하여, 저희 스쿼드에서는 수동 Ack 전략을 사용해서
Consumer 가 메세지를 정상적으로 전송받은 시점에서 명시적이고 안전한 Ack 처리를 하고 있습니다.
또한, Consumer에서 'isolation.level' 을 'read_committed' 로 설정해 커밋된 트랜잭션만 읽도록 구성하고 있습니다.
이러한 설정을 통해서 메시지 전달의 정확도를 높이며, 메시지가 한 번만 전송되고 처리될 수 있도록 하고 있습니다.
네트워크 이슈로 발생하는 Dead Letter는 Ack 설정을 통해 재처리가 가능합니다.
그렇다면 네트워크 이슈 외에 Dead Letter는 어떤 상황에서 발생할까요?
Connect 에서 발생 가능한 오류는 대개 직렬화 및 역직렬화(Serde) 오류입니다.
Consumer로 메세지가 전달될 때 발생하는 Dead Letter의 대부분은 Serde 오류인 경우가 많습니다.
Serde 오류는 개발 및 테스트 단계에서 캐치할 수 있지만,
만일을 대비해 DLQ(Dead Letter Queue)를 설정하여 모든 Dead Letter 발생을 처리하도록 했습니다.
DLQ 는 메시지 처리에 실패하거나 처리되지 않은 메시지를 별도로 관리하기 위한 대기열(queue)을 의미합니다.
errors.tolerance = all
errors.log.enable = [true|false]
errors.deadletterqueue.context.headers.enable = ture
errors.deadletterqueue.topic.name = <DLQTopicName>'errors.tolerance = all' 및 'errors.deadletterqueue.topic.name = <DLQTopicName>' 설정을 통해 실패한 데이터를 지정된 DLQ로 전달하고, 이후의 메시지는 정상적으로 처리됩니다.
또한, 'errors.deadletterqueue.context.headers.enable = true' 설정을 활성화하면, 메시지 헤더에 실패 원인을 저장할 수 있습니다.
정리하자면, Consumer 가 메시지를 수신할 때 Json Format과 Avro Format 간의 포맷 불일치 또는 Serde 오류가 발생할 경우,
오류 레코드를 DLQ(Dead Letter Queue) 로 전송하여 Consumer나 Connect 가 서비스를 지속적으로 중단 없이 제공할 수 있습니다.
그 밖에, 비즈니스 로직으로 인해 오류가 발생한 데이터는 S3에 엑셀 파일로 백업하여 관리하고 있습니다.
보다 상세한 내용은 아래의 블로그 내용을 참조해주세요.
https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/
MSK Connect 모니터링
AWS MSK를 사용하면 Amazon CloudWatch와 기본 연동이 가능해, 주요 지표를 모니터링할 수 있습니다.
그러나 올리브영에서는 더 효율적인 운영을 위해 DataDog 와 AWS MSK 를 연동하여 모니터링하고 있습니다.
AWS MSK 에서 제공하는 Prometheus 와 Prometheus Exporter를 이용하면, MSK의 지표를 DataDog으로 전달할 수 있습니다.
Prometheus Exporter 에서 JmxExporter, NodeExporter 를 활성화하여 DataDog 과 연동해서 수집할 수 있는 지표는 다음과 같습니다.
- JMX Exporter - Apache Kafka JMX 지표를 표시합니다.
- Node Exporter - CPU 및 디스크 지표를 표시합니다.
| Metric Name | Discription |
|---|---|
| aws.kafka.bw_in_allowance_exceeded | 브로커의 최대 수신 대역폭이 초과되어 패킷이 제한된 횟수 |
| aws.kafka.bw_out_allowance_exceeded | 브로커의 최대 송신 대역폭이 초과되어 패킷이 제한된 횟수 |
| aws.kafka.bytes_in_per_sec | 클라이언트로부터 초당 수신되는 바이트 수 |
| aws.kafka.bytes_out_per_sec | 클라이언트로 초당 송신되는 바이트 수 |
| aws.kafka.consumer_response_send_time_ms_mean | 소비자가 응답을 보내는 데 걸리는 평균 시간 |
| aws.kafka.cpu_credit_balance | 브로커의 CPU 크레딧 잔액 |
| aws.kafka.cpu_system | 커널 공간에서 CPU 사용량의 비율 |
| aws.kafka.cpu_user | 사용자 공간에서 CPU 사용량의 비율 |
| aws.kafka.fetch_consumer_local_time_ms_mean | 리더에서 소비자 요청이 처리되는 데 걸리는 평균 시간(밀리초) |
| aws.kafka.fetch_consumer_request_queue_time_ms_mean | 소비자 요청이 요청 대기열에서 기다리는 평균 시간(밀리초) |
| aws.kafka.fetch_consumer_response_queue_time_ms_mean | 소비자 요청이 응답 대기열에서 기다리는 평균 시간(밀리초) |
| aws.kafka.fetch_consumer_total_time_ms_mean | 소비자가 브로커로부터 데이터를 가져오는 데 걸리는 평균 총 시간(밀리초) |
| aws.kafka.fetch_follower_local_time_ms_mean | 리더에서 팔로워 요청이 처리되는 데 걸리는 평균 시간(밀리초) |
| aws.kafka.fetch_follower_request_queue_time_ms_mean | 팔로워 요청이 요청 대기열에서 기다리는 평균 시간(밀리초) |
| aws.kafka.fetch_follower_response_queue_time_ms_mean | 팔로워 요청이 응답 대기열에서 기다리는 평균 시간(밀리초) |
| aws.kafka.fetch_follower_response_send_time_ms_mean | 팔로워가 응답을 보내는 데 걸리는 평균 시간(밀리초) |
| aws.kafka.fetch_follower_total_time_ms_mean | 팔로워가 브로커로부터 데이터를 가져오는 데 걸리는 평균 총 시간(밀리초) |
| aws.kafka.fetch_message_conversions_per_sec | 브로커에서 초당 패치 메시지 변환 수 |
| aws.kafka.fetch_throttle_byte_rate | 초당 제한된 바이트 수 |
| aws.kafka.fetch_throttle_queue_size | 제어 대기열에 있는 메시지의 수 |
| aws.kafka.global_partition_count | 클러스터 전체 브로커에서의 파티션 총 개수 |
| aws.kafka.global_partition_count.maximum | 클러스터 전체 브로커에서의 최대 파티션 총 개수 |
| aws.kafka.global_topic_count | 클러스터의 브로커 수로 평균화된 토픽 총 개수 |
| aws.kafka.global_topic_count.maximum | 클러스터의 브로커 수로 평균화된 최대 토픽 총 개수 |
| aws.kafka.kafka_app_logs_disk_used | 응용 프로그램 로그에 사용되는 디스크 공간의 백분율 |
| aws.kafka.kafka_data_logs_disk_used | 데이터 로그에 사용되는 디스크 공간의 백분율 |
| aws.kafka.leader_count | 리더 복제본의 수 |
| aws.kafka.max_offset_lag | 토픽 내 모든 파티션에서의 최대 오프셋 지연 |
| aws.kafka.memory_buffered | 브로커를 위한 버퍼 메모리의 크기 |
| aws.kafka.memory_free | 브로커를 위해 사용 가능한 여유 메모리의 크기 |
| aws.kafka.memory_heap_after_gc | 가비지 컬렉션 후 사용 가능한 총 힙 메모리의 백분율 |
| aws.kafka.memory_used | 브로커에서 사용 중인 메모리의 크기 |
| aws.kafka.messages_in_per_sec | 초당 클라이언트로부터 받는 메시지의 수 |
| aws.kafka.network_processor_avg_idle_percent | 네트워크 프로세서가 유휴 상태인 시간의 평균 백분율 |
| aws.kafka.network_rx_dropped | 드롭된 수신 패키지의 수 |
| aws.kafka.network_rx_errors | 브로커의 네트워크 수신 에러 수 |
| aws.kafka.network_rx_packets | 브로커가 받은 패키지 수 |
| aws.kafka.network_tx_dropped | 드롭된 송신 패키지의 수 |
| aws.kafka.network_tx_errors | 브로커의 네트워크 송신 에러 수 |
| aws.kafka.network_tx_packets | 브로커가 전송한 패키지 수 |
| aws.kafka.offline_partitions_count | 클러스터 내에서 오프라인 상태인 파티션의 총 수 |
| aws.kafka.offset_lag | 파티션 수준의 소비자 지연(오프셋 수) |
| aws.kafka.partition_count | 브로커의 파티션 수 |
| aws.kafka.produce_local_time_ms_mean | 팔로워가 응답을 보내는 데 걸린 평균 시간 |
| aws.kafka.produce_message_conversions_per_sec | 브로커의 초당 생산 메시지 변환 수 |
| aws.kafka.produce_message_conversions_time_ms_mean | 메시지 형식 변환에 소요되는 평균 시간 |
| aws.kafka.produce_request_queue_time_ms_mean | 요청 메시지가 대기열에서 보내는 데 걸리는 평균 시간 |
| aws.kafka.produce_response_queue_time_ms_mean | 응답 메시지가 대기열에서 보내는 데 걸리는 평균 시간 |
| aws.kafka.produce_response_send_time_ms_mean | 응답 메시지를 보내는 데 걸리는 평균 시간 |
| aws.kafka.produce_total_time_ms_mean | 평균 생산 시간 |
| aws.kafka.replication_bytes_in_per_sec | 브로커 원본에서 복사본으로 초당 받는 바이트 수 |
| aws.kafka.replication_bytes_out_per_sec | 브로커 원본에서 복사본으로 초당 전송되는 바이트 수 |
| aws.kafka.request_bytes_mean | 브로커의 평균 요청 바이트 수 |
| aws.kafka.request_throttle_queue_size | 제어 대기열의 메시지 수 |
| aws.kafka.request_throttle_time | 평균 요청 제어 시간 |
| aws.kafka.sum_offset_lag | 토픽 내 모든 파티션에 대한 총 오프셋 지연 |
| aws.kafka.swap_free | 브로커를 위해 사용 가능한 스왑 메모리의 크기 |
| aws.kafka.swap_used | 브로커에서 사용 중인 스왑 메모리의 크기 |
| aws.kafka.traffic_bytes | 클라이언트(생산자 및 소비자)와 브로커 간의 전체 네트워크 트래픽(바이트), 브로커 간의 트래픽은 제외 |
| aws.kafka.volume_queue_length | 지정된 시간 동안 완료를 기다리는 읽기 및 쓰기 작업 요청의 수 |
| aws.kafka.volume_read_bytes | 지정된 시간 동안 읽은 바이트 수 |
| aws.kafka.volume_read_ops | 지정된 시간 동안의 읽기 작업 수 |
| aws.kafka.volume_total_read_time | 지정된 시간 동안 완료된 모든 읽기 작업에 소요된 총 시간(초) |
| aws.kafka.volume_total_write_time | 지정된 시간 동안 완료된 모든 쓰기 작업에 소요된 총 시간(초) |
| aws.kafka.volume_write_bytes | 지정된 시간 동안 쓴 바이트 수 |
| aws.kafka.volume_write_ops | 지정된 시간 동안의 쓰기 작업 수 |
더욱 상세한 지표 내용을 확인하고 싶으시다면, DataDog의 공식 문서를 참조해주세요.
https://docs.datadoghq.com/ko/integrations/amazon_msk/
위의 지표 외에도, 저희 스쿼드는 DataDog의 Kafka 관련 플러그인을 활용하여 Metrics 지표를 수집하며,
커스텀 Metrics 지표와 결합하여 더욱 풍부한 모니터링 대시보드를 구성하여 운영하고 있습니다.
끝으로
지금까지 올리브영 B2B 물류 스쿼드의 AWS MSK Connect 효과적으로 운영 방법을 소개하였습니다.
MSK Connect 에 대한 궁금증과 우려를 해소하고자 하며, MSK Connect 도입을 고려하시는 분들을 위해 이 글을 작성하였습니다.
글이 예상보다 길어져서 다큐멘터리가 된 것 같습니다.
그럼에도 불구하고 이 글이 누군가에게 유용한 정보가 되길 바라며, 여기서 마무리하겠습니다.
신기술에 관심 많으시고 저희 스쿼드와 함께 오프라인 서비스를 개선하고 싶은 분이라면, 채용공고를 확인해주세요!
더 발전된 모습으로 다시 만나 뵙겠습니다.
지금까지 올리브영 B2B 물류 스쿼드, 시나브로우였습니다.
감사합니다.
