올리브영의 인벤토리 담당 스쿼드는 자사의 핵심 경쟁력인 옴니채널 전략을 뒷받침하기 위해, 대규모 데이터 속에서도 높은 처리량과 낮은 지연을 유지하며 중단 없는 재고 서비스를 제공하는 것을 목표로 합니다. 하지만 재고 정합성을 지켜내는 일은 결코 쉽지 않은 여정인데요. 이번 글에서는 다양한 옴니채널 재고 데이터를 안정적으로 서빙하기 위한 여러 기술적 접근과 구조적 개선 과제들을 소개해 드리고자 합니다.
🔍 매장 재고는 어디서, 어떻게 쓰일까?
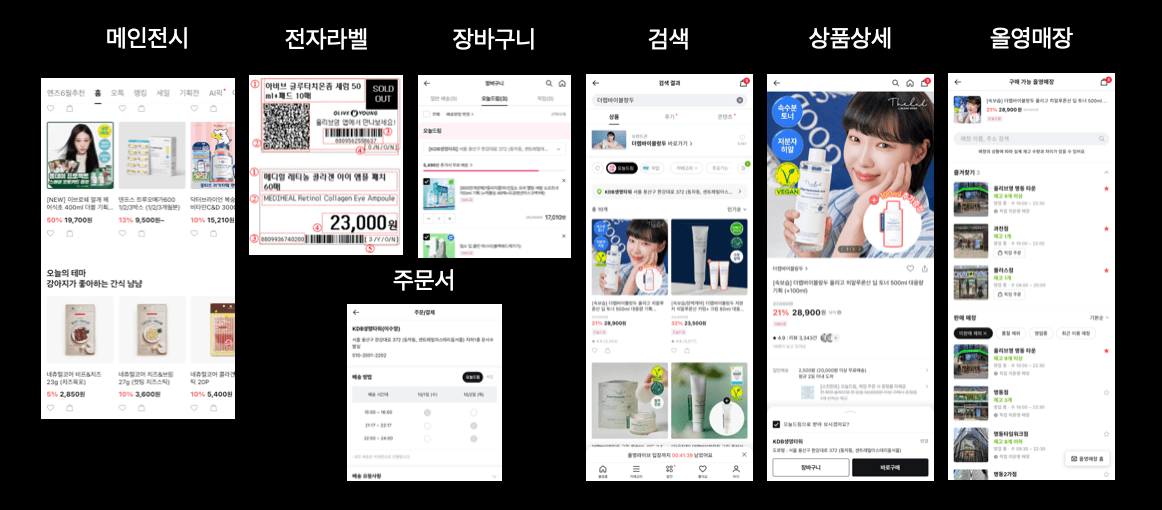
올리브영은 전국 수많은 오프라인 매장의 상품 재고를 실시간으로 관리하고 있습니다. 이러한 재고 데이터는 온·오프라인을 잇는 수많은 서비스의 신뢰도와 고객 경험을 좌우합니다. 그 중에서도 가장 대표적인 사용처는 여러분도 자주 이용하시는 온라인몰 앱입니다. 자세한 설명을 위해 올리브영의 대표 서비스 중 하나인 '오늘드림' 이용을 위해 고객이 앱에 접속했다고 가정해 보겠습니다. 원하는 상품을 검색하고 결제에 이르기까지, 거의 모든 구매 여정 전반에서 매장 재고 데이터가 사용되고 있죠. 아래 자료에서 보실 수 있듯, 고객이 실제로 앱에서 가장 처음 마주보는 전시 영역을 비롯해 상품 상세 페이지, 검색, 장바구니, 주문서까지 다양한 영역에서 사용 중이며, 밸류체인 내 유관부서 및 담당자들이 확인할 수 있도록 내부 시스템에서도 사용하고 있습니다.
⚙️ 매장 재고 데이터 파이프라인 구조
다양한 사용처에 지연 없이 정확한 재고를 높은 처리량으로 전달하기 위해 인벤토리 시스템은 다음과 같은 실시간 데이터 파이프라인 아키텍처를 구축하여 운영하고 있습니다. 매장 운영 주기에 따라 '기초재고 생성'과 '실시간 재고 변동 처리'의 두 사이클로 파이프라인이 운영됩니다.
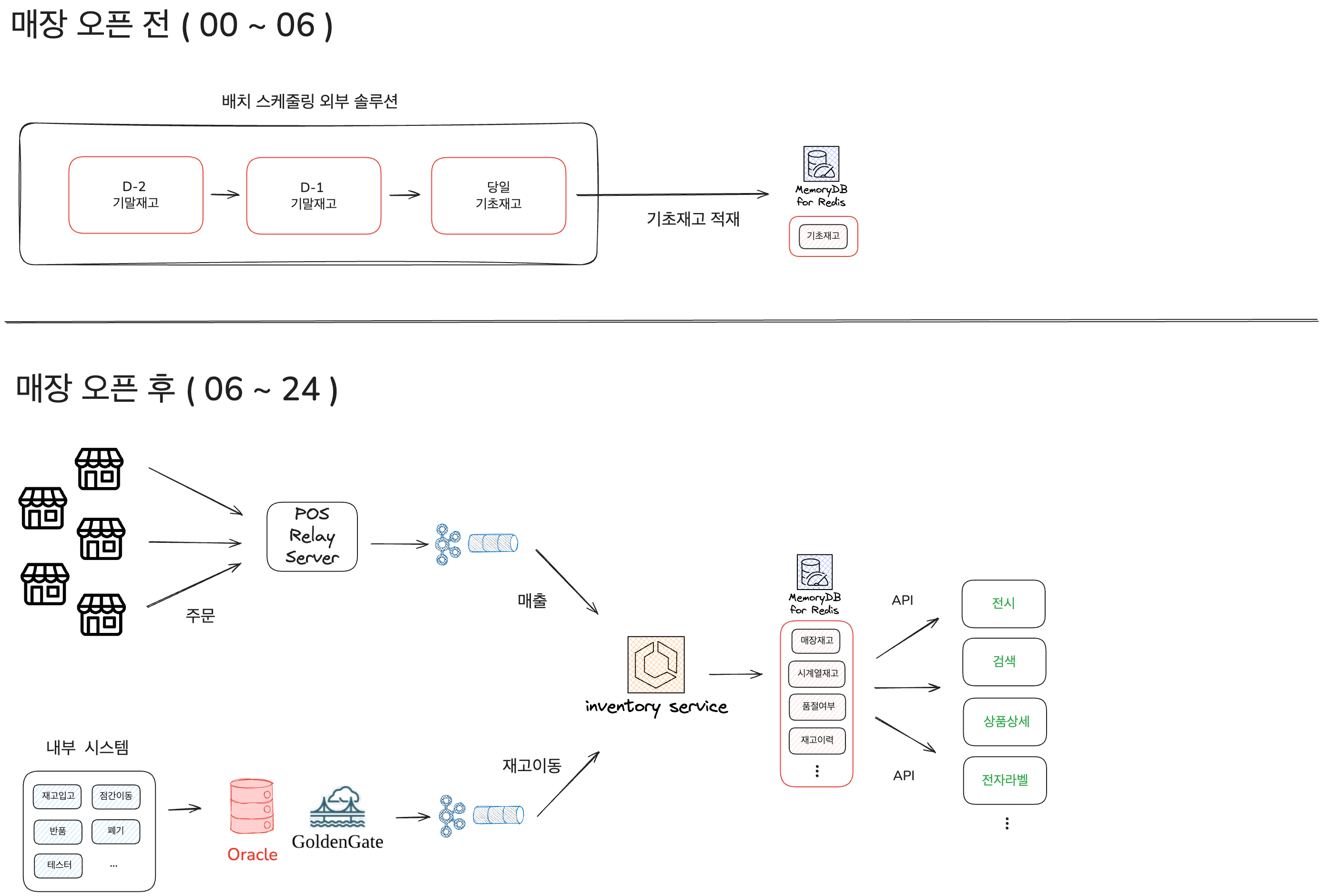
1. 기초재고 생성 (00~06시)
오프라인 매장 오픈 전, 전일(D-1) 기말재고(전일 영업 마감 시점의 최종 재고)를 정산하는 '수불' 과정을 거쳐 당일에 필요한 기초재고(당일 영업 시작 시점의 재고)가 산출됩니다. 저희는 이 과정에서 약 1,400여 개 매장에 1,200만여 건의 기초재고를 생성하는 데 평균 1~2시간이 소요됩니다. 기초재고는 파이프라인의 출발점으로, 여기서 정합성이 틀어지면 이후 모든 처리가 오염되기 때문에 높은 정합성과 안정성이 요구됩니다.
💡 참고: '수불'이란 전일 기말재고를 기준으로 입고, 출고, 매장 간 이동, 매출 등 전날의 모든 변동분을 정산하여 당일 기초재고를 만드는 마감작업입니다.
2. 실시간 재고 변동 처리 (06~24시)
- 오프라인 매장 주문 : 전국 매장 POS에서 발생한 주문 데이터(TR)는 POS Relay Server에서 카프카 메시지로 변환되어 토픽에 발행되고, 인벤토리 서비스가 이를 구독해 실시간 매출 이벤트를 처리합니다.
- 내부 ADMIN 시스템 : 재고 입고, 매장 간 재고 이동, 반품, 폐기, 테스터 등 물류 및 재고 운영에서 발생하는 변동은 RDB(Oracle)에 먼저 반영됩니다. 이후 CDC 솔루션인 Oracle의 GoldenGate를 통해 카프카 이벤트 스트림으로 발행되어 인벤토리 서비스로 유입됩니다.
인벤토리 서비스는 수신한 이벤트를 단순 수량 계산을 넘어 다음과 같이 다양한 형태로 모델링하여 적재합니다.
| 구분 | 내용 | 활용 |
|---|---|---|
| 매장재고 | 매장별 상품의 현재 판매가능수량 | 상품 상세·장바구니·주문서 등 구매 여정 전반에서 실시간 조회 |
| 시계열재고 | 시간대별 재고 변동 스냅샷 데이터 | 특정 시점 재고 조회 및 변동 추이 분석 |
| 품절여부 | 매장재고에서 파생되는 품절 상태 플래그 | 전시 노출 여부 등 재고 가용성 판단 |
| 증정품재고 | 프로모션·행사용 증정품의 가용 수량 | 일반 상품 재고와 별도 관리 |
| 재고이력 | 재고 변동 이벤트의 감사 로그 (OpenSearch) | 이력 추적 및 이상 탐지 |
💡 참고: 시계열 재고에 대해서는 2024년 발행된 올리브영 테크블로그 포스트 "재고의 변동을 시계열 데이터로?!"을 참고하셔도 좋습니다.
3. API를 통한 재고 서빙
온라인몰의 전시·장바구니·주문서·검색 등 대규모 트래픽이 몰리는 대외 서비스뿐만 아니라, 오프라인 매장의 전자라벨 시스템 및 PDA까지 중단 없이 실시간 재고 정보를 전달하고 있습니다.
🚧 확장 과정에서 드러난 구조적 한계
올리브영의 트래픽과 비즈니스 규모가 확장되면서 초기 아키텍처는 기초재고 생성, 데이터 적재·처리, 서빙이라는 세 영역에서 구조적 한계에 부딪히기 시작했습니다.
1. 기초재고 생성: 리드타임 증가
매출 증가, 상품 수 확대, 입고·출고·매장 간 이동 등 재고 변동 이벤트가 늘어날수록 기초재고 생성 연산량도 함께 증가했습니다. 그 결과 생성 리드타임이 지속적으로 늘어났고, 이는 옴니채널 운영에서 재고 부정합과 고객 경험 저하의 원인이 되었습니다.
2. 데이터 적재 처리: 단일 파이프라인의 동기식 적재 병목
기존 인벤토리 서비스는 재고 변동 이벤트를 수신한 뒤, 하나의 파이프라인 안에서 모든 데이터 모델을 동기적으로 가공하여 적재했습니다. 매장재고, 시계열재고, 품절여부 등 서로 다른 데이터 모델이 단일 파이프라인에 묶인 높은 결합도 구조였다 보니, 하나라도 지연이 발생하면 그 여파가 전체 파이프라인으로 전파되는 연쇄 지연으로 이어져 실시간성과 안정성 모두에 영향을 미쳤습니다.
3. 데이터 전달: API 조회(pull) 방식에 따른 제약과 효율성 저하
모든 사용처가 단일 API를 통해 재고를 직접 조회하는 방식은 사용처의 성격에 따라 효율이 크게 달랐습니다. 상품 상세·장바구니·주문서처럼 고객의 구매 결정 순간에는 실시간 조회가 가장 정확하고 효율적이지만, 검색·전자라벨 등 자체 데이터 스토어를 보유한 서비스들이 최신 재고 갱신을 위해 주기적으로 인벤토리 API를 호출하면서 문제가 생겼습니다. 변경되지 않은 데이터까지 통째로 조회하면서 양 서비스 간에 불필요한 오버헤드와 과도한 Read 부하가 발생했습니다.
🚀 인벤토리 파이프라인 아키텍처 개편
세 가지 구조적 한계를 해소하기 위해, 메인 인벤토리 서비스의 역할을 최적화하고 각 서비스 목적에 맞게 데이터를 분산하는 이벤트 기반 아키텍처(EDA)로의 전환을 결정했습니다. (현 시점에서 일부 재고 유형은 전환이 진행 중입니다.)
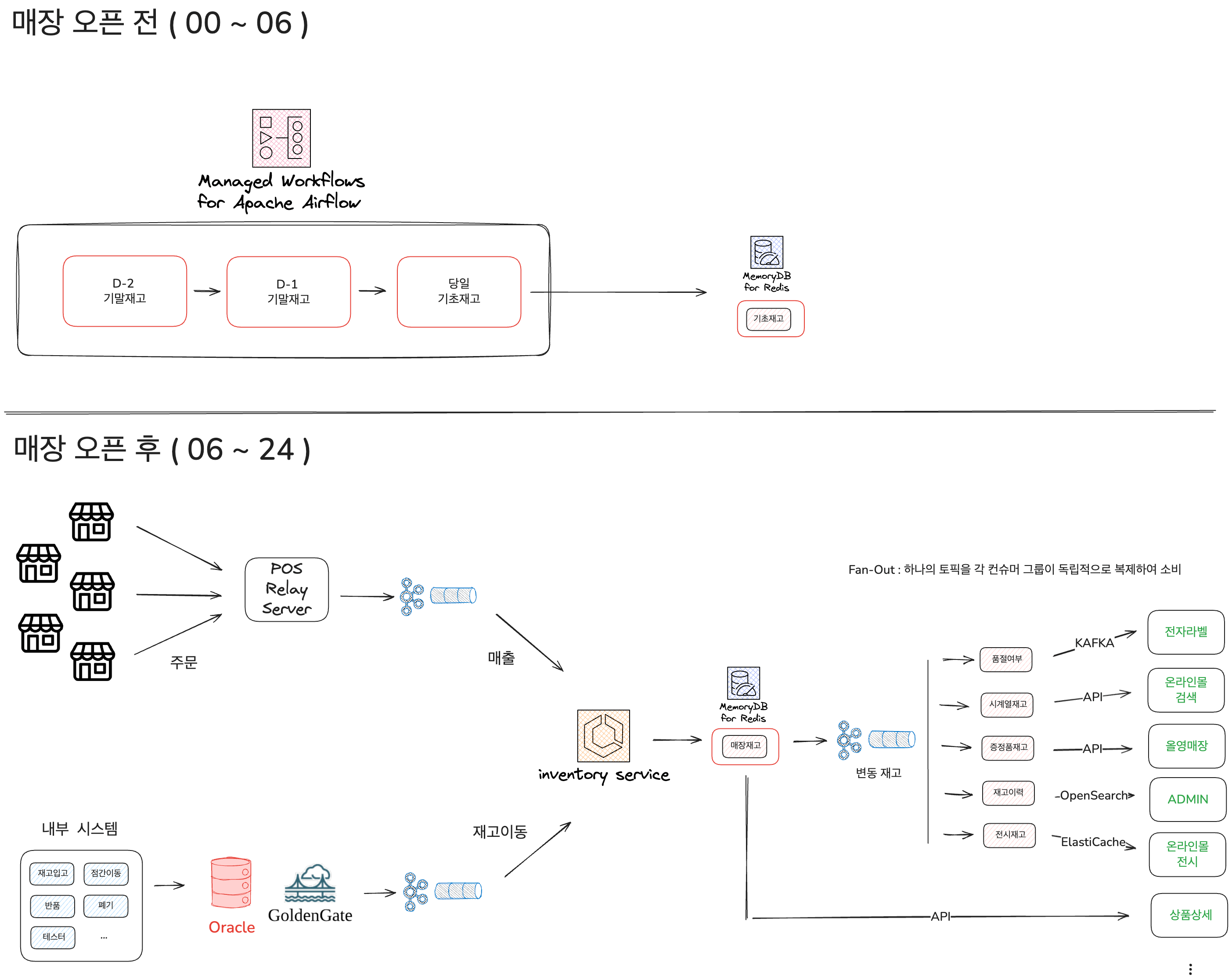
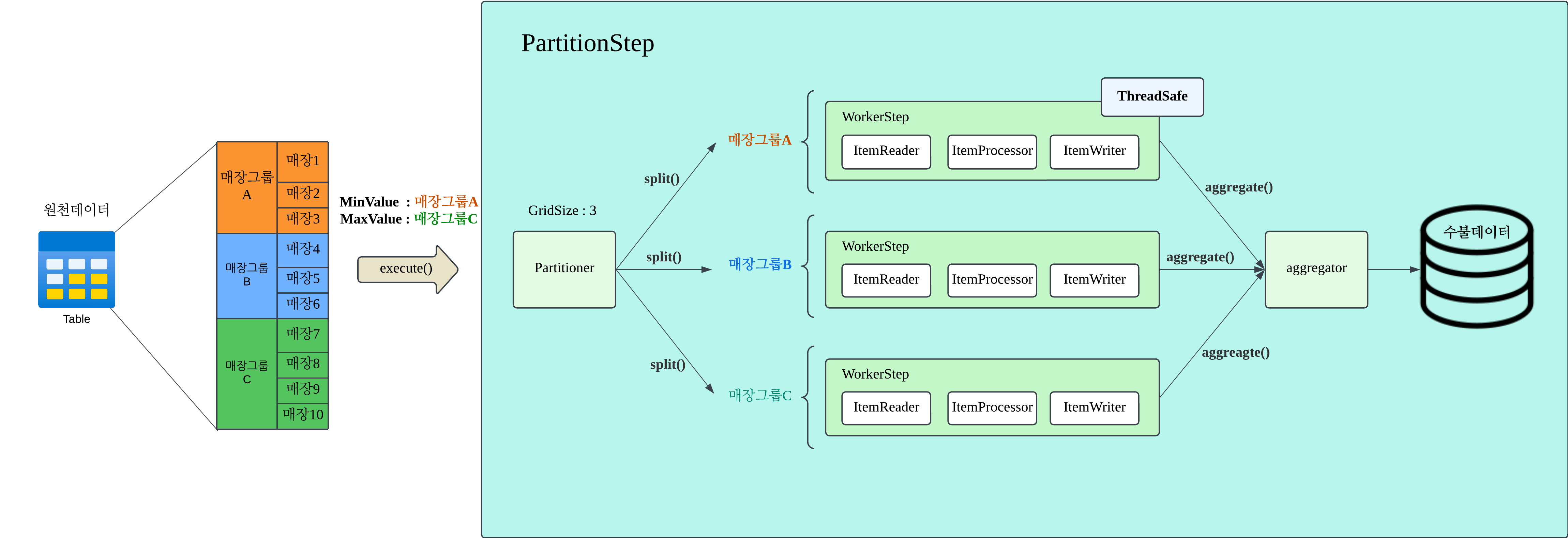
1. 기초재고 생성: Spring Batch Partitioning으로 리드타임 단축
저희는 매장이라는 자연스러운 분할 단위가 이미 존재했기에, 매장 그룹을 파티션 키로 삼는 Spring Batch Partitioning이 가장 합리적인 선택이었습니다. 여러 개의 서브 Step이 독립적으로 수행되어 기초재고 생성 시간을 평균 50분에서 25분으로 50% 단축했고, 기존 약 2만 라인의 프로시저도 전면 제거했습니다. 아래는 약 1,400개 매장을 매장 그룹으로 파티셔닝해 각 WorkerStep에 할당하는 설정 코드 일부입니다.
@JobScope
fun baseStockMainStep() : Step {
return stepBuilderFactory.get(BASE_STOCK_MAIN_STEP)
.partitioner(
BASE_STOCK_PARTITION_STEP,
GroupNoRangePartitioner() //GridSize 기준으로 매장그룹을 나누는 파티셔너
)
.step(baseStockPartitionStep()) //WorkerStep 선언
.gridSize(jobParameterStore.gridSize)
.taskExecutor(rnpTaskExecutor) //멀티스레딩 설정
.build()
}
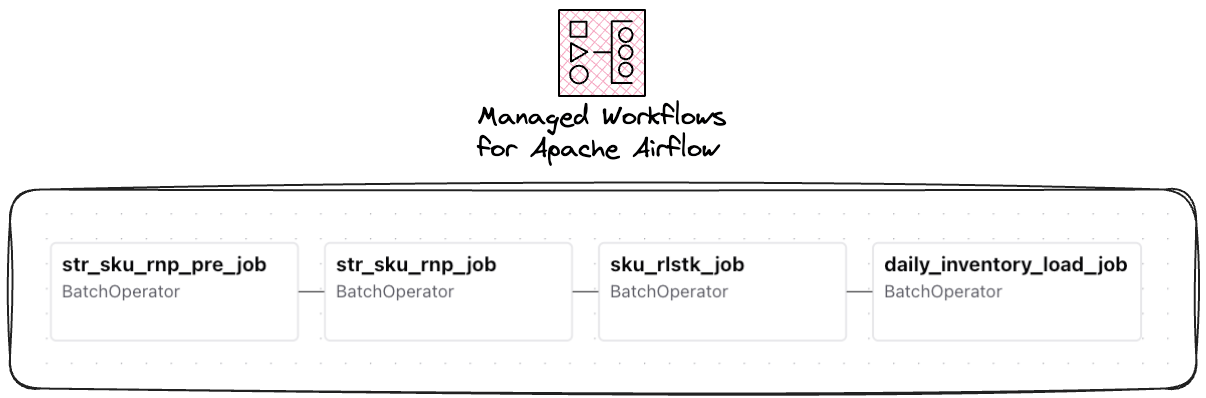
기초재고 로직을 Spring Batch로 전환하면서 워크플로 또한 코드로 관리하고자 했습니다. 직접 구축 대신 AWS Batch 환경과 통합되는 관리형 서비스인 Amazon MWAA를 도입해 기초재고 파이프라인 전체를 안정적인 스케줄링 체계로 자동화했습니다.
2. 데이터 적재 처리: Kafka Fan-Out으로 동기식 병목 해소
인벤토리 서비스의 매출·재고이동 엔드포인트에서는 매장재고만 최우선으로 적재한 뒤, 즉시 변동 재고 토픽으로 이벤트를 발행하고 트랜잭션을 종료합니다.
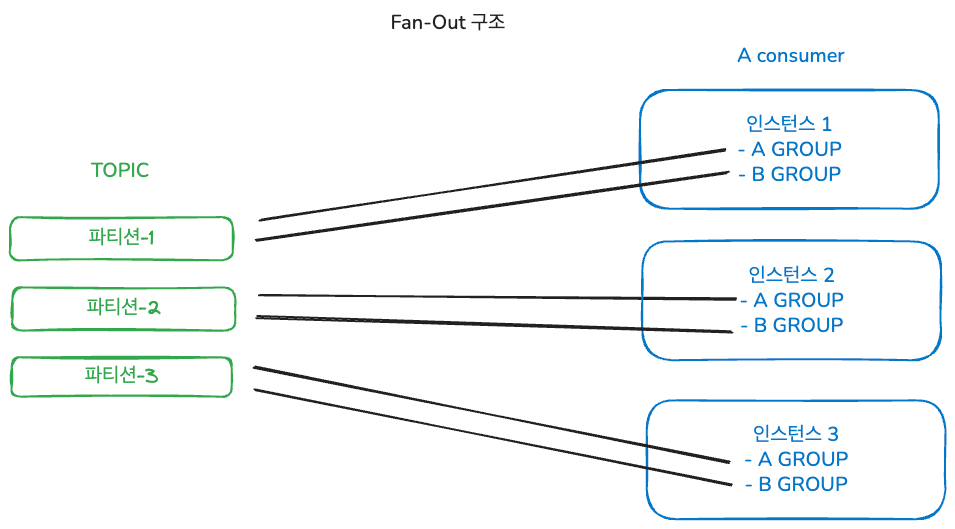
이때 Kafka Fan-Out 구조를 적용해, 하나의 변동 재고 토픽을 품절 여부, 시계열 재고, 재고 이력 등 컨슈머 그룹이 각각 독립적으로 구독하도록 지정했습니다. Kafka는 컨슈머 그룹별로 오프셋을 따로 관리하므로 한 그룹의 처리 지연이 다른 그룹에 전파되지 않아 연쇄 지연과 높은 결합도 문제를 해결할 수 있었습니다.
💡 참고: Kafka Fan-Out 방식은 하나의 토픽에 발행된 이벤트를 여러 컨슈머 그룹이 각각 독립적으로 구독해 소비하는 구조입니다. Kafka는 그룹별로 오프셋을 따로 관리하므로 한 그룹의 지연이 다른 그룹에 영향을 주지 않아 독립적인 처리가 필요할 때 주로 사용됩니다.
3. 데이터 전달: 서비스 성격에 따른 Push/Pull 분리
정합성 요구 수준과 데이터 보유 형태가 사용처마다 달랐기에, 단일 API 방식을 일률 적용하는 대신 서비스 성격에 따라 두 가지 전달 방식으로 분리했습니다.
- 이벤트 기반 PUSH: 자체 데이터 스토어를 가진 서비스들은 변동 재고 또는 품절 여부 토픽을 직접 구독해 각자의 데이터 스토어에 자율적으로 동기화합니다. 이로 인해 불필요한 전체 재고 조회가 없어지고 이벤트가 있는 재고만 갱신하게 됐으며, 특정 사용처의 API 호출을 약 90% 줄일 수 있었습니다.
- 실시간 온디맨드 PULL: 상품 상세·장바구니·주문서처럼 구매 결정 순간에 직결되는 서비스에는 미세한 재고 정합성 오류도 허용되지 않아, 매장재고를 실시간 API로 제공했습니다. 인벤토리 서비스는 매장재고만 적재하므로 지연이 낮고 결합도가 낮아 안정성과 정합성을 모두 보장할 수 있었습니다.
🏁 마치며
단일 동기식 구조에서 이벤트 기반 아키텍처로의 전환은 단순한 기술 개선이 아니라, 인벤토리 시스템이 더 다양한 옴니채널 요구에 유연하게 응답할 수 있는 구조적 토대를 만드는 과정이었습니다. 개편 이후 각 서비스는 성격에 맞는 방식으로 재고를 소비할 수 있게 됐고, 인벤토리 스쿼드는 그 위에서 더 넓은 확장성을 실험할 수 있는 기반을 갖추게 됐습니다. 앞으로도 옴니채널 환경이 확장될수록 인벤토리 시스템이 어떻게 진화해야 하는지, 계속 고민하고 공유하겠습니다. 읽어주셔서 감사합니다.