
들어가며
안녕하세요! 올리브영에서 Back-end 개발을 담당하고 있는 '코드다이버(이시훈)'입니다. 앞서 "올리브영 전자라벨(ESL) 구축기 Part 1: 종이 없는 매장을 만드는 데이터 파이프라인"에서는 전자라벨의 도입 배경과 아키텍처 설계 부분을 다뤘습니다. 이번 글에서는 전국 1,300여 개 매장으로 대규모 확산하는 과정에서 마주한 성능 최적화 기술들을 중점적으로 소개하겠습니다. 특히 아래와 같은 내용을 담고 있으니 참고해 주세요.
🛠️ Engineering Highlights
- Partitioning - 1,300개 매장 배치 처리 시간 13일 → 5분 단축
- Lock Free - 데이터 범위 분할로 DB Deadlock 원천 차단
- Serverless v2 - 트래픽 폭주에 대응하는 오토스케일링으로 비용 40% 절감
🎯 특히 이런 분들께 도움이 될 거예요
- 대용량 배치 처리 속도 문제로 고민하는 백엔드 개발자
- 예측 불가능한 트래픽에 대응하는 DB 인프라 전략이 궁금한 엔지니어
1편에서 이야기한 아키텍처가 설계도라면, 지금부터는 실제 데이터를 태워 가동할 차례입니다. 굳이 비유하자면, 시스템 구축 초기의 파일럿 매장은 '2~4명으로 구성된 우리 가족을 위해 집에서 두쫀쿠를 몇개 만들어 제공'하는 수준과 같았습니다. 하지만 전국 1,300개 이상 매장 적용은 '전국에 근무 중인 수천 명의 올리브영 임직원에게 동시에 일정한 퀄리티의 두쫀쿠를 제공하는 시스템을 운영'하는 것과 같습니다. 메뉴(로직)는 같을지 몰라도, 조리 도구와 조달 방식(아키텍처와 성능 최적화)은 근본적으로 달라야만 했습니다.
이에 압도적인 규모로 전국 매장에 안정적으로 시스템을 도입하기 위해 저희가 치열하게 고민했던 대용량 트래픽 처리와 운영 최적화 이야기, 지금부터 시작합니다.
Chapter 1. 배치가 끝나지 않는다: 병렬 처리의 함정과 Partitioning
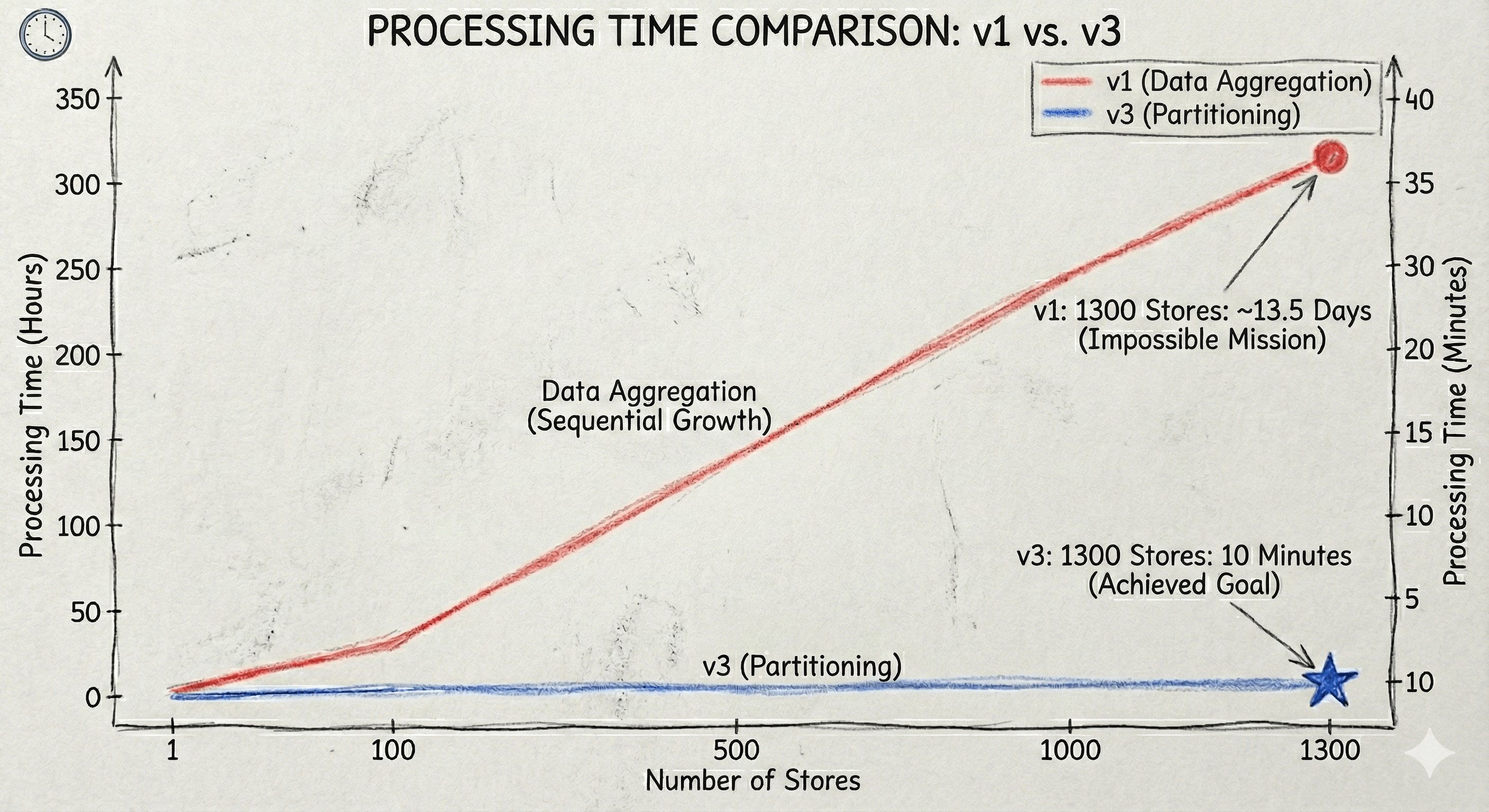
전자라벨 시스템의 배치는 상품 데이터 중 변경된 데이터(Delta)를 찾아내는 고된 작업입니다. 초기 버전(V1) 성능 테스트 결과, 복잡한 데이터 집계(Aggregation) 로직으로 인해 1개 매장을 처리하는 데 평균 15분이 소요되었습니다. 이 속도라면 1,300개 매장을 순차적으로 처리할 경우 약 13일(15분 × 1,300개)이 걸린다는 충격적인 결과가 도출됩니다. 매장 오픈 시간(오전 10시)까지 작업을 끝내야 하는 저희에게 이는 말그대로 '불가능한 미션'이었습니다.
| 항목 | 측정 및 계산 결과 | 비고 |
|---|---|---|
| 단위 매장 처리 시간 | 약 15분 | 복잡한 집계(Aggregation) 로직 |
| 전체 대상 매장 수 | 19,500분 (약 13.5일) | 순차 처리 시 소요 기간 |
| 목표 완료 시간 | 매장 오픈 전 (오전 10시) | 현실적 달성 불가능 |
시도: 단순 병렬 처리의 실패 (V2)
이러한 물리적인 시간을 단축하기 위해 저희는 가장 먼저 Scale-out(병렬 처리) 카드를 꺼냈습니다. Spring Batch의 Multi-threaded Step을 적용하여 수십 개의 스레드가 동시에 여러 매장의 데이터를 집계하고 DB에 갱신을 하도록 설정했습니다.
"스레드 수만큼 속도가 선형적으로 증가하겠지"라는 기대와 달리, 배치를 가동하자마자 성능 향상은커녕 터미널은Deadlock Loser 오류로 뒤덮였습니다. 원인은 긴 트랜잭션과 자원 경합에 있었습니다. 복잡한 Aggregation 로직이 실행되는 동안 트랜잭션이 길게 유지되었고, 병렬 스레드들이 동일한 테이블 내의 인접한 인덱스 범위에 대해 동시에 Write를 시도하며 락(Lock) 경쟁을 벌인 것입니다. 결국 스레드들은 서로가 점유한 자원이 해제되기만을 기다리는 교착 상태(Deadlock)에 빠졌고, 시스템은 아무런 처리도 하지 못한 채 멈춰 섰습니다.
해결: Partitioning으로 완성한 10분의 기적 (V3)
그래서 저희는 '스레드 간의 데이터 간섭을 0으로 만들자'는 원칙으로 구조를 전면 개편했습니다. 해답은 Spring Batch Partitioning이었습니다.
-
Spring Batch Partitioning: 전체 데이터를 PK(Primary Key) 범위 기반으로 논리적 격리를 수행했습니다. (예: ID 1
1000, 10012000...) -
Lock Free 구조: 각 Worker Step은 자신에게 할당된 고유한 PK 범위 내에서만 집계(Aggregation)와 갱신(Update)을 수행합니다.
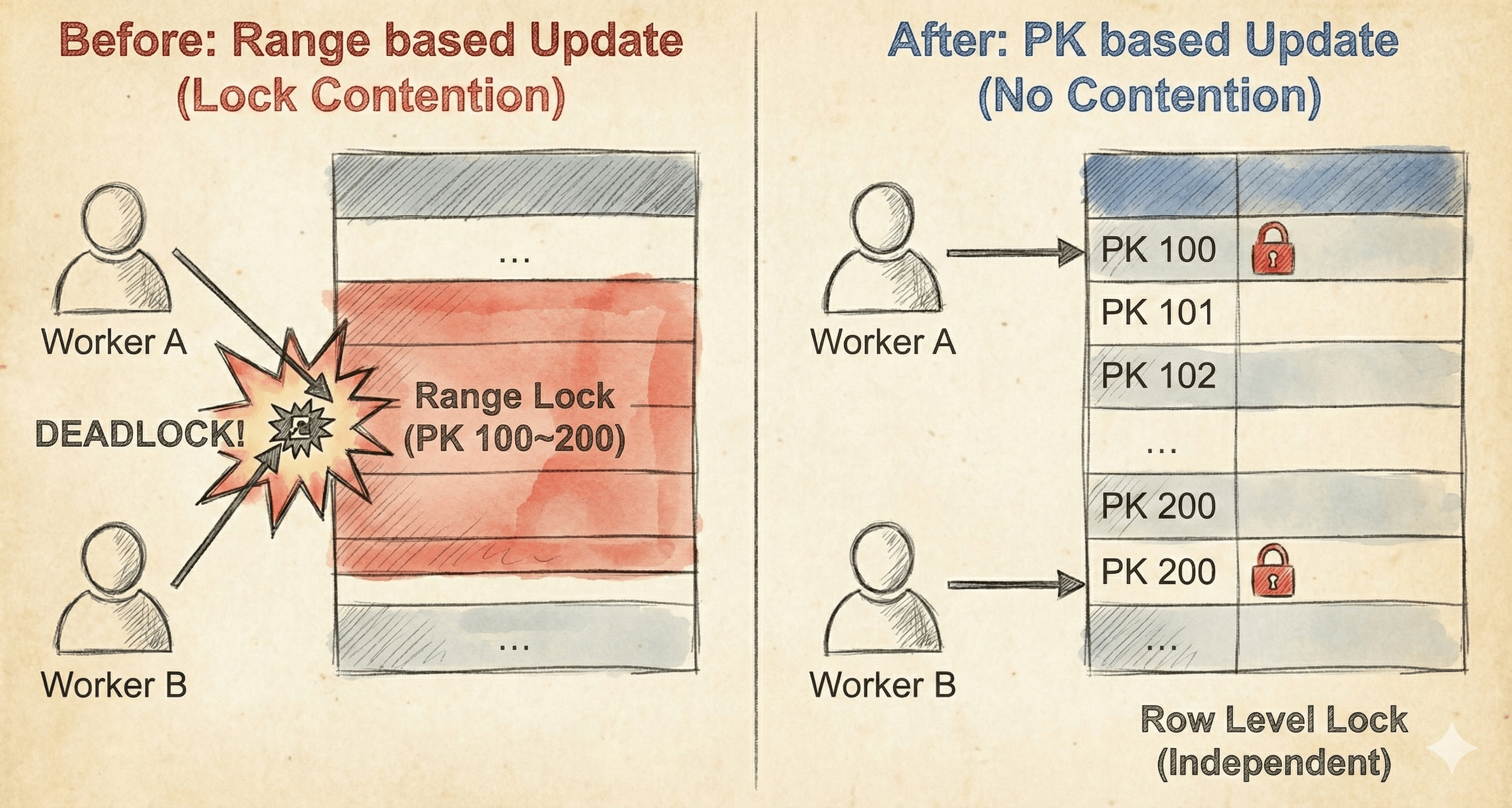
이 방식은 각 워커가 서로 다른 데이터 범위를 처리하므로 물리적으로 자원 침범이 발생하지 않아 DB Lock 경합이 원천 차단되었습니다. Lock이 사라지자 CPU와 I/O 자원을 온전히 데이터 처리에만 쓸 수 있게 되었고, 13일이 걸릴 뻔했던 작업은 단 5분 만에 1,300개 매장 처리를 완료하는 기적 같은 효율을 보여주었습니다.
Chapter 2. 예측 불가능한 폭주를 감당하라: RDS Serverless v2의 탄력성
배치 성능의 문제는 해결했지만, 인프라 운영의 난관이 남았습니다. 우리 서비스의 트래픽은 단순히 '배치 시간'에만 몰리는 것이 아니라, 그 강도(Intensity)를 예측하기 어렵다는 것이 문제였습니다.
- 평시: 적은 양의 데이터 변경만 발생
- 프로모션/올영세일 기간: 평소 대비 수십 배, 수백 배의 변경 데이터가 예고 없이 폭주(Burst)
기존의 RDS On-Demand(고정형 인스턴스) 방식으로는 이 변동성을 감당하기 어려웠습니다. 세일 기간을 대비해 항상 최고 사양(Provisioned)을 유지하자니 비용 낭비가 심했고, 그렇다고 평시에 맞춰두자니 갑작스러운 데이터 폭증 시 장애가 발생할 위험이 있었습니다.
시도: 인프라 스스로 숨 쉬게 하라 (RDS Serverless v2)
저희는 이 딜레마를 해결하기 위해 트래픽 양에 따라 실시간으로 DB 자원을 늘리고 줄이는 Aurora RDS Serverless v2 도입을 결정했습니다. 저희가 주목한 핵심 기능은 데이터 폭주가 시작되는 시점에 지연 없이 대응하는 '즉각적이고 중단 없는 확장(Instant & Seamless Scaling)' 입니다. 이는 운영자가 수동으로 개입하지 않아도 시스템이 스스로 트래픽의 파도에 맞춰 숨을 쉬는 구조를 완성해주었습니다.
| 구분 | 기존 RDS (On-Demand) | Aurora RDS Serverless v2 |
|---|---|---|
| 확장 방식 | 수동 스케일업 (재부팅 필요) | 자동 오토스케일링 (즉시 반영) |
| 다운타임 | 수 분 발생 (서비스 중단) | 없음 (Seamless Scaling) |
| 비용 | 피크 트래픽 기준 고정 비용 | 사용량 기반 종량제 과금 |
검증 및 결과: 예상치 못한 파도타기
도입 후 저희는 Serverless v2가 보여준 야생성에 놀랐습니다. 배치가 시작되고 데이터가 급격히 유입되면, DB의 ACU(Aurora Capacity Unit) 가 수직 상승하며 부하를 받아냈습니다. 반대로 작업이 끝나거나 데이터 양이 적은 날에는 즉시 최저 사양(Min ACU)으로 줄어들어 숨을 고르는 걸 볼 수 있었습니다. 운영자가 "오늘 데이터가 많을까?"를 고민하며 미리 스펙을 올리고 내릴 필요가 없어진 것입니다. 시스템이 데이터의 파도에 맞춰 스스로 서핑을 하는 셈입니다.
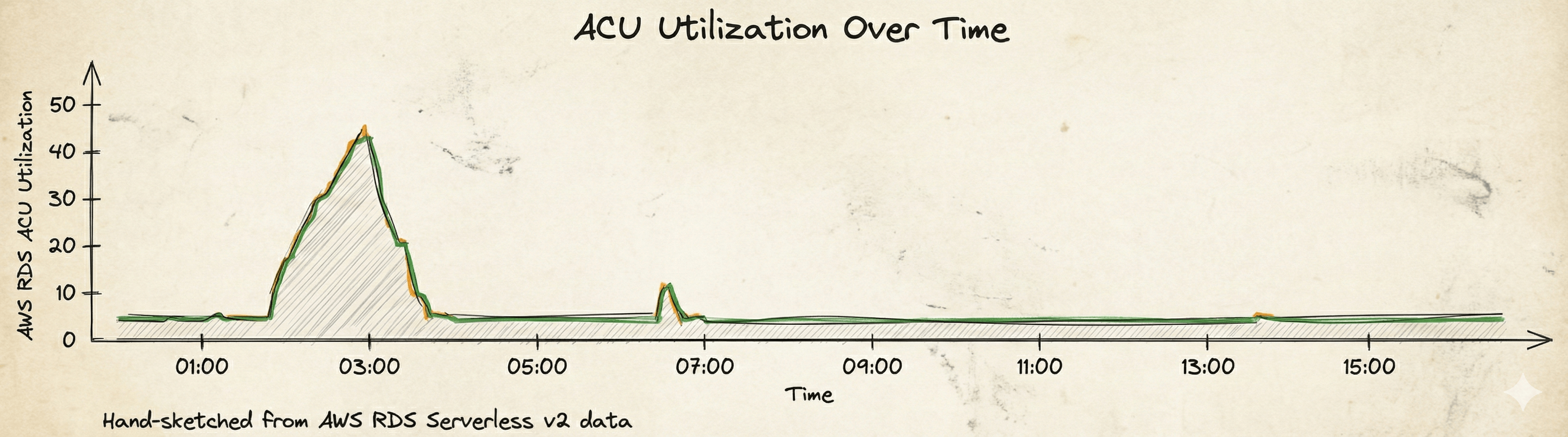
결과적으로 저희는 '성능의 안전판'과 '비용 효율' 이라는 두 마리 토끼를 잡았습니다. 데이터가 적을 땐 확실하게 비용을 아끼고, 폭주할 땐 성능 제한 없이 확실하게 처리하는 '클라우드 네이티브' 환경을 구축함으로써, 고정형 인스턴스 대비 약 40%의 비용 절감 효과를 거둘 수 있었습니다.
마치며: 안정성과 효율성의 균형
이렇게 저희는 1,300개 매장의 데이터를 안정적으로 처리하면서도 비용 효율적인 시스템을 갖추게 되었고, 전자라벨을 도입하며 두 가지 큰 교훈을 얻었습니다.
- Application Level: 대용량 데이터 집계(Aggregation)는 단순한 병렬화가 아니라, '데이터의 분할과 정복(Partitioning)' 을 통해 Lock을 회피해야 한다는 점
- Infrastructure Level: 클라우드의 이점은 단순히 서버를 빌리는 것이 아니라, 상황에 맞게 '탄력적(Elastic)으로 사용하는 것' 에 있다는 점
이제 종이 라벨이 사라진 자리에는 데이터가 흐르고, 그 데이터는 초단위의 실시간 정보로 진화하고 있습니다. 이어지는 다음 편에서는 "파이프라인 위에서 고객과 직원의 경험을 실시간으로 혁신하는 이벤트 기반 재고 시스템" 이야기로 찾아오겠습니다. 계속해서 많은 기대 부탁드립니다.
