
안녕하세요! 😆 지난 포스팅인 'ItemLM: 상품 정보 기반의 임베딩 생성기'에 이어 두 번째로 인사드립니다.
저는 올리브영에서 머신러닝으로 다양한 문제를 풀고 있는 🪄 데이터 사이언티스트 입니다.
지난 글에서 상품 데이터를 효율적으로 다루는 기초 체력을 다뤘다면, 이번에는 최신 오픈소스 모델을 기반으로 상용 모델 대비 95%의 정확도를 유지하면서도 운영 비용은 획기적으로 낮춘, 올리브영의 sLLM(Small LLM) 구축 경험을 공유하려 합니다. 🥂
올리브영의 첫 sLLM 학습기
그 중에서도 자체 학습시킨 sLLM을 서비스에 도입한 첫 번째 사례, '리뷰 테마 추천' 시스템을 소개합니다.
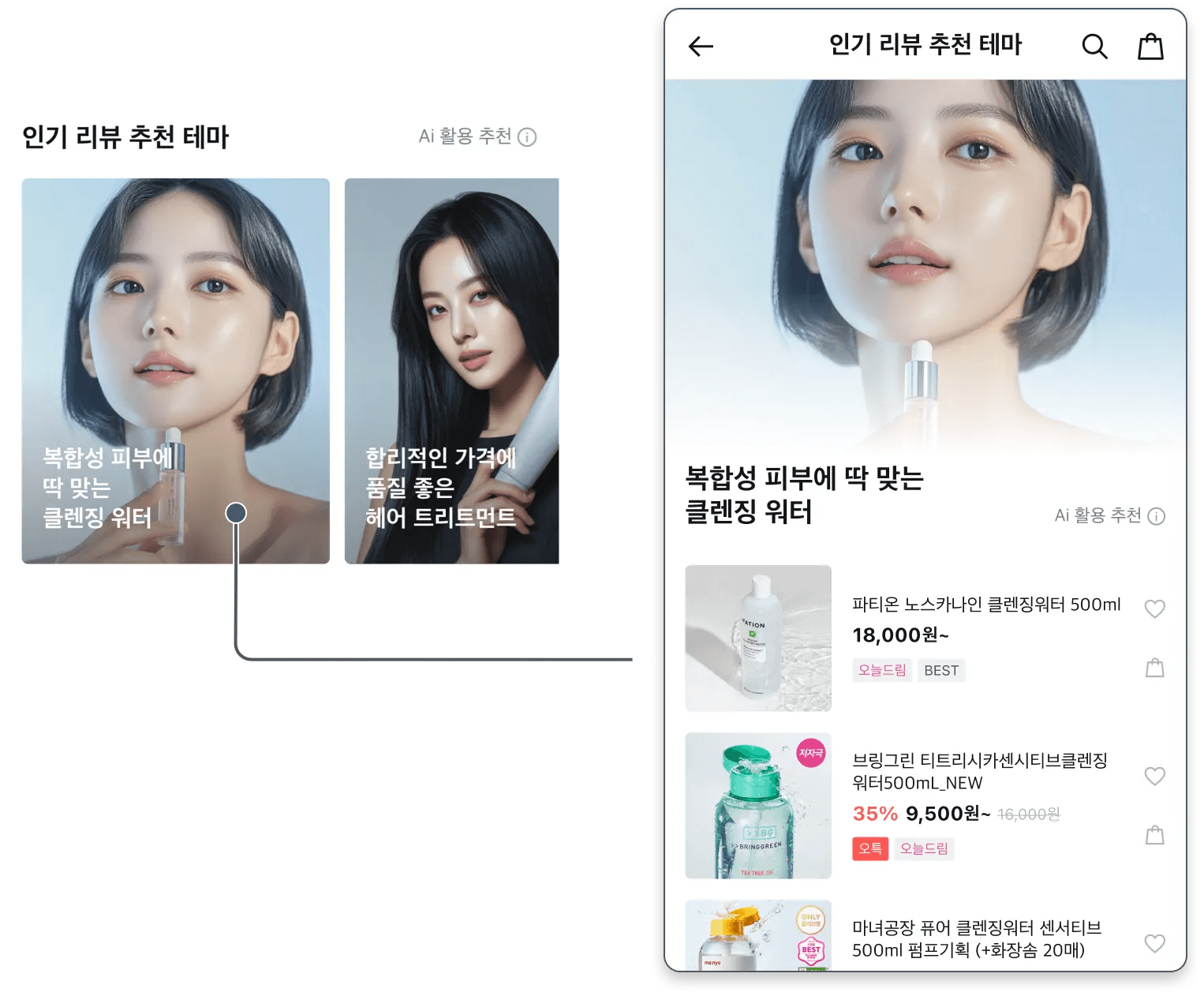
아래 이미지와 같이 올리브영 앱을 켜면 보이는 '인기 리뷰 추천 테마' 영역은 단순히 상품을 보여주는 일반적인 추천이 아닙니다. 사용자들이 남긴 방대한 리뷰 데이터를 sLLM이 분석하여, "복합성 피부에 딱 맞는 클렌징 워터"나 "합리적인 가격에 품질 좋은 헤어 트리트먼트"처럼 사용자의 고민과 니즈에 딱 맞는 '추천 테마'를 매력적인 문구와 이미지로 자동 생성해 제안하는 공간입니다.

실제로 존재하는 생생하고 다양한 상품에 대한 고객의 표현을 녹여 추천 카드로 탄생시킨 건데요, 이 과정은 단순한 모델 개발 그 이상의 도전이었습니다. "고가의 상용 API 없이 Tesla T4 GPU 1장이라는 제한된 환경에서 과연 상용 모델급의 고성능을 낼 수 있는가?"라는 질문에 대한 기술적 해답을 찾아가는 여정이었기 때문입니다. 저사양 GPU 환경이라는 제약을 딛고 상용 모델 못지않은 고품질 sLLM을 완성하기까지 치열하게 고민했던 해결 과정을 '올리브영 리뷰테마 추천 시스템'을 예로 들어 상세히 소개해 보겠습니다.
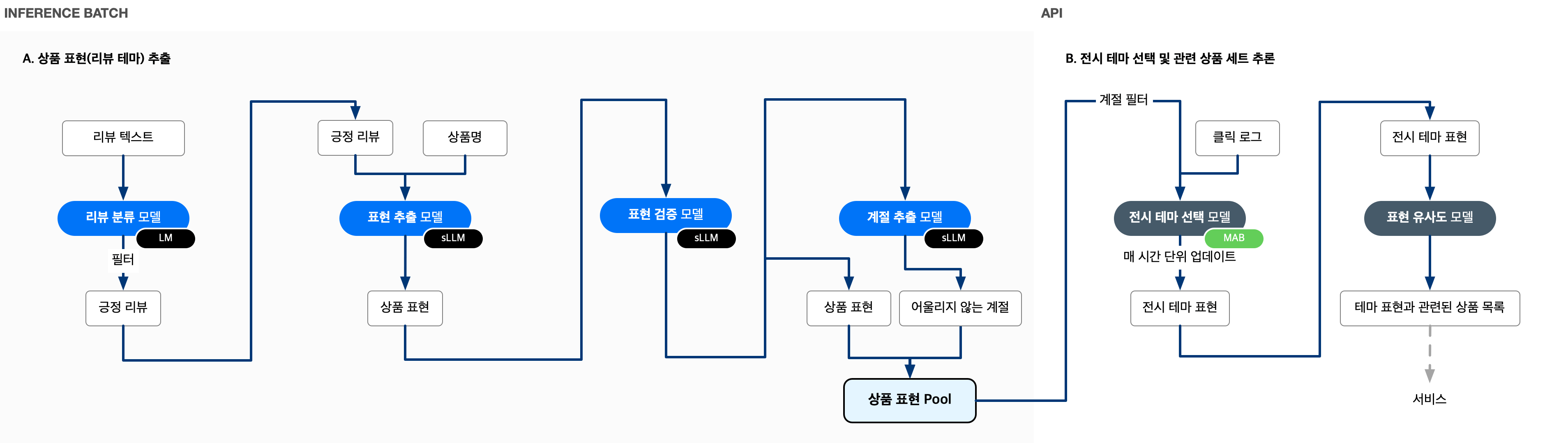
리뷰테마 추천 시스템의 컴포넌트
리뷰 테마 추천 시스템은 리뷰 분류부터 표현 추출, 검증, MAB(Multi-Armed Bandit) 기반 전시 최적화까지 다양한 컴포넌트로 연결되어 있습니다. 본문에서는 전체 구조 중 sLLM이 활약하는 영역에만 집중합니다. 특히 사용자 리뷰를 매력적인 추천 문구로 탄생시키는 '표현 생성 모델'의 학습 과정을 중심으로 심층적인 기술 노하우를 공유합니다.
상용 모델 대신 자체 sLLM을 선택한 이유
이 프로젝트는 "사용자들의 생생한 리뷰로부터 최적의 추천 문구를 자동으로 생성하자"라는 비즈니스 요구에서 출발했습니다.
추천 문구는 "합리적인 가격에 품질 좋은 헤어 트리트먼트"처럼 자연스러우면서도 다양한 조합이 필요했기 때문에, 고정된 패턴만 다루는 규칙 기반(Rule-based) 시스템으로는 품질과 확장성 측면에서 명확한 한계가 있었습니다.
이에 따라 자연어 생성이 가능한 LLM을 사용하기로 결정했고, 특히 상용 LLM API를 직접 호출하는 방식과 오픈소스 sLLM을 자체 학습(SFT)하는 방식을 면밀히 비교 검토했습니다. 최종적으로는 sLLM SFT 방식을 선택했으며, 결정적 이유는 다음과 같습니다.
재현성과 버전 통제
상용 LLM API는 제공사의 모델 업데이트에 따라 동일한 프롬프트라도 응답 품질이나 스타일이 예측 불가능하게 변할 수 있습니다. 리뷰테마 추천처럼 안정적인 품질의 결과를 지속적으로 제공해야 하는 서비스에서는, 학습 데이터, 코드, 체크포인트를 직접 관리하고 언제든 동일한 결과를 재현할 수 있는 구조가 필수적이었습니다.
프롬프트 엔지니어링의 한계 극복
상용 모델을 운영 수준의 품질로 사용하려면, 프롬프트에 조건·예시·제약을 반복해서 추가해야 합니다. 그러나 프롬프트가 길어질수록 토큰 비용이 급증하고 응답 시간이 늘어납니다. 또한 모델이 모든 지시사항을 완벽히 따르기 어려워집니다. 반면 SFT를 통해 지시사항과 출력 형식을 모델에 직접 학습시키면, 훨씬 짧은 프롬프트만으로도 안정적이고 정확한 결과를 얻을 수 있습니다.
운영 비용의 예측 가능성
API 방식은 호출량에 비례해 비용이 급증하는 구조이기 때문에, 트래픽이 급증하는 상황에서 비용 통제가 어렵습니다. 반면 자체 GPU 환경에서 운영하는 sLLM은 시간당 고정된 서버 비용 내에서 명확히 예측·통제 가능하며, 서비스 규모가 커져도 비용 상한선을 관리하기 용이합니다.
비용과 품질을 동시에 잡는 자체 sLLM의 이점
초기에는 상용 LLM API를 그대로 사용하는 방식과 오픈소스 sLLM을 직접 SFT하는 방식을 모두 검토했습니다. 결과적으로 아래와 같은 이유로 소형 오픈소스 LLM을 직접 학습(sLLM SFT) 하는 방향을 선택했습니다.
SFT (Supervised Fine-Tuning)
기초 교육을 마친 신입사원(Base Model)에게 올리브영만의 업무 매뉴얼(데이터)을 집중적으로 가르쳐 우리 부서에 딱 맞는 인재로 만드는 과정입니다.
이 중 가장 중요한 의사결정 기준은 “재현성”과 “버전 통제 가능성”이었습니다.
리뷰테마 추천 시스템은 항상 일정한 품질의 표현을 안정적으로 제공해야 하기 때문에, 언제든 다시 학습/재현할 수 있고 모델, 데이터, 코드를 함께 버전 관리할 수 있는 구조가 필요했습니다.
프롬프트 엔지니어링의 한계: 복잡도와 재현성 문제
상용 LLM을 사용할 때는, 원하는 품질을 얻기 위해 프롬프트에 조건·예시·제약을 계속 추가하게 됩니다. 이 과정이 반복되면, 결국 다음과 같은 문제가 생깁니다.
- 프롬프트가 지나치게 길어져 토큰 비용과 응답 지연이 커짐
- 여러 단계의 호출을 조합하면서 사실상 if 문이 많은 프로그램을 짜는 것과 비슷한 복잡도로 변함
- 프롬프트가 길고 복잡할수록 작은 변경에도 동작이 예측하기 어려워짐
아무리 정교하게 프롬프트를 다듬어도 Task의 복잡도가 임계치를 넘으면 LLM이 모든 지시사항을 완벽히 이행하지 못합니다. 일관된 품질 유지에 명확한 한계가 존재하는 것입니다.
반면 sLLM을 직접 SFT하는 방식은 우리가 원하는 출력 형식과 품질 기준을 데이터에 직접 내재화할 수 있습니다. 덕분에 프롬프트 구성을 단순하게 유지하면서도 결과의 재현성과 버전 통제권을 완벽히 확보하게 됩니다. 결과적으로 리뷰 테마 생성과 같은 도메인 특화 Task에서 sLLM이 상용 모델보다 더 적합한 선택지라고 판단했습니다.
최적의 파운데이션 모델 찾기: Gemma 3와 후보군 비교
프로젝트 초기에는 Gemma2-2B을 기반으로 시작했습니다. 이후 개발 기간 중 Gemma3가 출시되면서 성능과 다국어 지원 면에서 더 적합하다고 판단해 Gemma3-4B로 변경했습니다.
후보 모델군 검토 및 한국어 벤치마크 비교
아래 한국어 벤치마크 성능 비교표와 같이 네이버의 HyperCLOVA X SEED, Qwen 시리즈 등 한국어 성능이 준수한 여러 오픈소스 모델을 함께 검토했습니다. 하지만 서비스 적합성을 고려하여 최종 후보군에서는 제외했는데요, 사유는 다음과 같습니다.
-
HyperCLOVA X SEED 3B
한국어 성능은 가장 우수했으나, MAU 기반 라이선스 제약으로 인해 서비스 적용이 어렵다고 판단.
-
Qwen 2.5/3 시리즈
벤치마크 성능은 우수했으나, 실제 테스트 시 한국어 오타 정정(Typo Robustness) 성능이 상대적으로 낮아 리뷰 기반 생성 Task에는 부적합하다고 판단.
실무 적용을 위한 두 가지 핵심 허들
-
컴퓨팅 효율성
개발 및 운영 환경이 Tesla T4 16GB 기준이기 때문에, 이 조건에서 안정적으로 동작할 만큼 메모리 사용이 가벼우면서도 충분한 성능을 제공하는 모델이어야 했습니다. Gemma는 효율적인 추론을 위해 설계된 아키텍처적 강점을 가지고 있습니다. Sliding Window Attention과 Local-Global Attention 혼합 구조를 통해 메모리 사용량을 최소화하면서도 긴 컨텍스트를 효과적으로 처리할 수 있으며, Multi-Query Attention(MQA)과 Grouped-Query Attention(GQA) 기법을 적용해 추론 속도를 향상시켰습니다. 이러한 최적화 덕분에 T4와 같은 제한된 GPU 환경에서도 안정적으로 동작하면서 실시간 서비스에 필요한 응답 속도를 확보할 수 있었습니다.
-
한국어 처리 능력
실제 사용자 리뷰는 오타, 비문, 구어체가 많기 때문에 한국어 인식 및 오타 복원 능력을 필수 조건으로 설정했습니다. Gemma 3는 140개 이상의 언어를 지원하는 멀티링구얼 모델로 설계되었으며, Gemini 2.0 계열의 SentencePiece 토크나이저(262k vocab)를 사용해 한국어를 포함한 CJK(중국어·일본어·한국어) 언어의 인코딩 효율이 크게 개선되었습니다. 동일한 한국어 텍스트를 처리할 때 이전 세대 대비 토큰 수가 줄어들어 메모리 사용량과 추론 속도가 향상되었으며, 리뷰 데이터처럼 구어체와 오타가 혼재된 텍스트에서도 안정적인 토큰화 성능을 보여주어 실무 적용에 적합했습니다.
왜 Gemma 3-4B 인가
Gemma는 경량화된 실용적인 크기에서 효과적인 성능을 제공하도록 설계된 Google의 오픈소스 LLM입니다.

- Gemma2: 2B, 9B, 27B 세 가지 모델로 제공되며, 가장 작은 2B 모델조차 GPT-3.5를 능가하는 성능을 보여주었습니다. (출처: Chatbot Arena)
- Gemma3: 멀티모달 입력과 더 확장된 다국어 지원을 제공하며, 특히 4B 모델이 Chatbot Arena에서 GPT-4와 유사한 수준의 성능을 기록하여 소형 모델 중 매우 우수한 결과를 보였습니다. (참고: Gemma 3 Model Card)
학습 방법
학습 목표
리뷰 테마 추천 모델의 핵심 목적은 사용자 리뷰에서 상품 추천 카드에 사용할 '테마 표현'을 안정적으로 추출하는 것입니다. 구체적으로는 입력된 리뷰에서 entity, expression, name을 식별하여 구조화된 JSON 리스트 형태로 출력하도록 학습합니다.
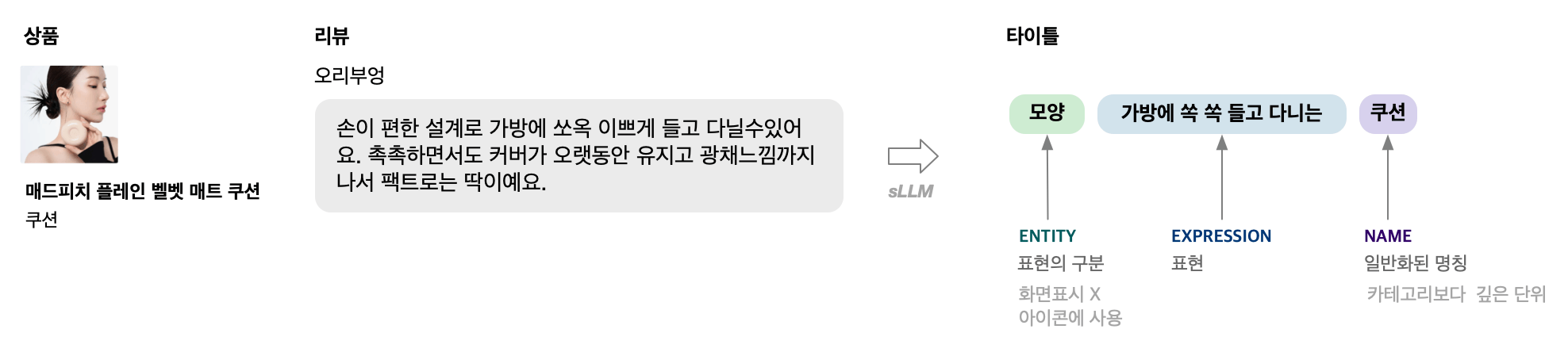
학습 데이터 생성
리뷰 기반 추천 표현을 학습시키기 위해서는 대규모의 입력–출력 쌍이 필요합니다. 그러나 이를 사람이 모두 직접 제작하는 것은 현실적으로 시간과 비용 측면에서 매우 비효율적입니다.
따라서 기본적인 지침과 출력 형식을 정의한 뒤, 오픈소스 LLM으로 생성하고 사람의 검토 및 수정을 거쳐 SFT용 데이터셋을 구축했습니다. 이 방식은 품질을 일정 수준으로 통제하면서도, 필요한 데이터 규모를 빠르게 확보할 수 있다는 장점이 있습니다.
Supervised Fine-Tuning 전략 (Post-Training)
오픈소스 LLM을 특정 도메인(Task)으로 적응시키는 가장 일반적인 방법은 Post-training 단계의 첫 과정인 Supervised Fine-tuning(SFT) 입니다. 대부분의 오픈소스 모델은 다음과 같은 형태로 공개됩니다.
- ~pt : Pre-training만 완료된 Base 모델
- ~it : Instruction finetuning까지 완료된 Chat 모델 (SFT 1차 완료 상태)
이번 프로젝트에서는 Gemma 3-4B-IT 모델을 기반으로, 그 위에 올리브영 리뷰 데이터에 특화된 도메인 적응(Domain Adaptation) SFT를 수행했습니다. (아래 표의 D단계)
즉, 기존 Chat 모델 위에 리뷰테마에 적합한 추가 지식·스타일·출력 규칙을 학습시키는 단계입니다.
우리가 베이스 모델(Base Model)로 선택한 Gemma 3-4B-IT는 이미지와 텍스트를 동시에 처리하는 멀티모달 모델입니다. 따라서 내부적으로 이미지 인코더인 비전 타워(Vision Tower)와 전용 프로세서를 포함하고 있습니다. 하지만 이번 프로젝트는 오직 텍스트 데이터만을 활용하므로 제한된 인프라 자원을 효율적으로 쓰기 위해 모델과 전처리 체인을 텍스트 전용으로 경량화하는 과정이 반드시 필요했습니다.
허깅페이스(Hugging Face)의 가이드에 따르면 멀티모달 기능을 모두 활용할 때는 Gemma3ForConditionalGeneration 클래스를 사용해야 합니다. 하지만 우리는 비전 타워 로딩을 과감히 생략하고 일반적인 LLM처럼 활용하기 위해 Gemma3ForCausalLM 클래스로 모델을 호출했습니다. 이러한 Text-only 최적화 로드 방식을 통해 불필요한 파라미터를 제거하고 오직 텍스트 학습에만 집중할 수 있는 환경을 구축했습니다.
참고
Hugging Face 공식 블로그: Transformers를 활용한 Gemma 3의 세부 추론 가이드
https://huggingface.co/blog/gemma3#detailed-inference-with-transformers
학습 시에는 어차피 LoRA를 사용해 전체 파라미터가 아니라 일부만 업데이트하기 때문에, 학습 속도나 GPU 메모리 사용량이 극적으로 줄어들지는 않습니다. 다만 운영 관점에서는 비전 관련 가중치를 제외함으로써 모델 파일 크기와 로드 시 메모리 사용량이 약 15% 정도 감소하는 효과가 있었습니다.
16GB VRAM 환경을 위한 학습 최적화
16GB GPU(Nvidia Tesla T4) 작은 VRAM 환경에서는 파라미터 규모가 4B 수준인 sLLM이라도 학습 시에 VRAM이 부족하기에 메모리 최적화가 필수적입니다. 그래서 다음과 같은 방법들을 적용했습니다.
모델 연산 효율화를 위한 Precision 설정
보통 VRAM이 작은 환경에서 LLM은 FP16(BF16) 기반의 half-precision 연산을 사용하도록 가이딩되어 있으며, 이는 연산 속도와 VRAM 사용량을 균형 있게 줄여주는 가장 기본적인 설정입니다.
배치 처리 최적화로 메모리 사용량 제어
두 가지의 최적화 방법을 통해서 작은 GPU 메모리에서도 안정적으로 학습이 가능하도록 최적화했습니다.
-
Gradient Checkpointing
중간 활성화를 모두 저장하지 않고 일부 지점만 저장한 뒤 역전파 때 다시 계산해서, 연산량을 늘리는 대신 학습 시 필요한 GPU 메모리를 대략 절반 수준까지 줄이는 방법
-
Gradient Accumulation
GPU 메모리가 작아 한 번에 큰 배치를 올리기 어려울 때, 여러 번의 작은 배치(micro batch)에서 그래디언트를 누적했다가 한 번에 업데이트하여 메모리는 작은 배치 수준으로 유지하면서도 큰 batch size로 학습한 것과 비슷한 효과를 내는 방법
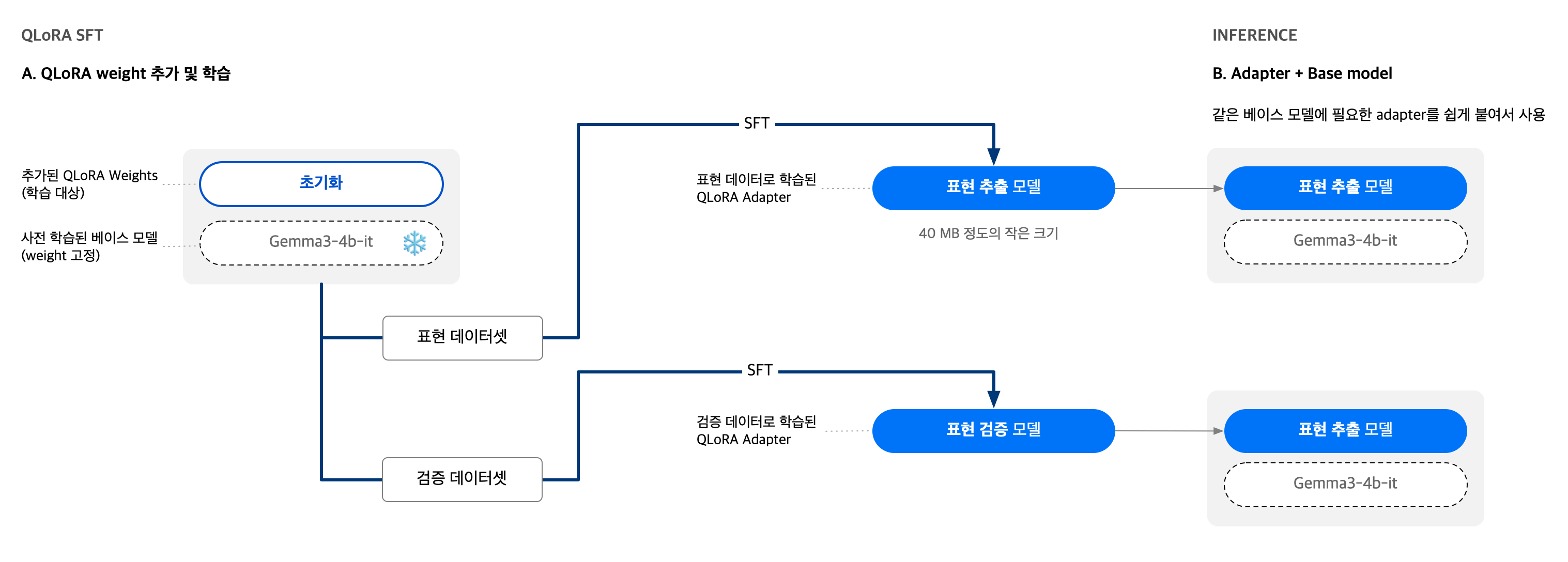
LoRA 및 파라미터 Quantization 학습
가장 중요한 부분으로 SFT를 진행할 때는 전체 파라미터를 직접 학습하지 않고, 특정 모듈에 저차원 어댑터(LoRA) 를 추가한 뒤 이 파라미터만 업데이트하는 방식을 사용했습니다. 이 방식은 전체 모델을 미세 조정하는 것보다 학습 시간과 GPU 메모리 사용량을 크게 줄일 수 있다는 장점이 있습니다.
이번 프로젝트에서는 여기에 더해, 기저 모델 가중치를 4bit로 양자화한 상태에서 LoRA 어댑터를 학습하는 QLoRA 방식을 적용해 학습 시 필요한 VRAM을 추가로 절감했습니다. (연산은 FP16/BF16으로 수행하고, Base 모델 가중치 저장에만 4bit quantization을 적용)
LoRA 기반으로 학습하면 추론 단계에서도 이점이 있습니다. 기존 base model에 학습된 LoRA 모듈만 어댑터처럼 결합해 사용할 수 있기 때문에, 여러 도메인·목적에 맞춰 학습된 LoRA를 빠르게 교체할 수 있고, 전체 모델을 여러 개 따로 관리하는 것보다 저장 공간과 로딩 시간 모두를 크게 줄일 수 있습니다.
LoRA & Quantization
거대한 모델 전체를 수정하려면 엄청난 메모리가 필요합니다. Quantization(양자화)으로 모델의 무게를 가볍게 줄이고, LoRA를 통해 모델의 핵심 지식은 건드리지 않은 채 '얇은 노트' 한 권 분량의 지식만 추가로 학습시키는 효율적인 방법입니다.
프롬프트 단축
SFT 과정에서 프롬프트를 단축하는 이유는 추론 시 토큰 비용을 줄이고 응답 속도를 개선하기 위해서입니다.
프롬프트 단축의 비용 절감 효과
프롬프트를 단축 전 528자에서 98자로 단축(약 81% 감소)하면, 대규모 배치 추론 시 상당한 인프라 비용을 절감할 수 있습니다. 이를 구체적인 수치로 환산해보면 다음과 같습니다. 프롬프트 단축은 자체 GPU 서버(AWS g4dn.xlarge 등)에서 sLLM을 운영할 때 처리량(throughput) 향상에 직접적인 영향을 미칩니다.
** AWS g4dn.xlarge 온디맨드 가격 $0.70/hour 기준
LLM으로 학습 데이터를 생성할 때는 제약조건·지시사항을 모두 포함한 긴 프롬프트가 필요하지만, 자체 학습한 sLLM에서는 지시문 자체를 모델이 내재적으로 학습할 수 있으므로 훨씬 짧은 형태의 프롬프트로도 동일한 품질을 유지할 수 있습니다.
프롬프트 길이가 모델 성능에 어떤 영향을 주는지 검증하기 위해, 다양한 형식을 구성하여 1 epoch씩 학습한 후 비교한 결과 다음과 같은 인사이트를 얻었습니다.
실험 인사이트
- 설명(Rich Desc)을 함께 제공하는 형식이 가장 안정적으로 동작
- 예시(Example based)만 제공하면 품질이 떨어짐
- 설명 없이 한 블록으로 줄인 extreme 단축 버전(TaskTagOnly)은 성능이 가장 낮았음
- 설명과 input 사이의 구조적 구분(ShortDesc, NoInputHeader)을 제거하면 품질이 저하됨
즉, 지나치게 축약하는 것보다 짧더라도 구조, 규칙, 역할을 명확히 보여주는 형태가 가장 효율적이라는 결론을 얻었습니다.
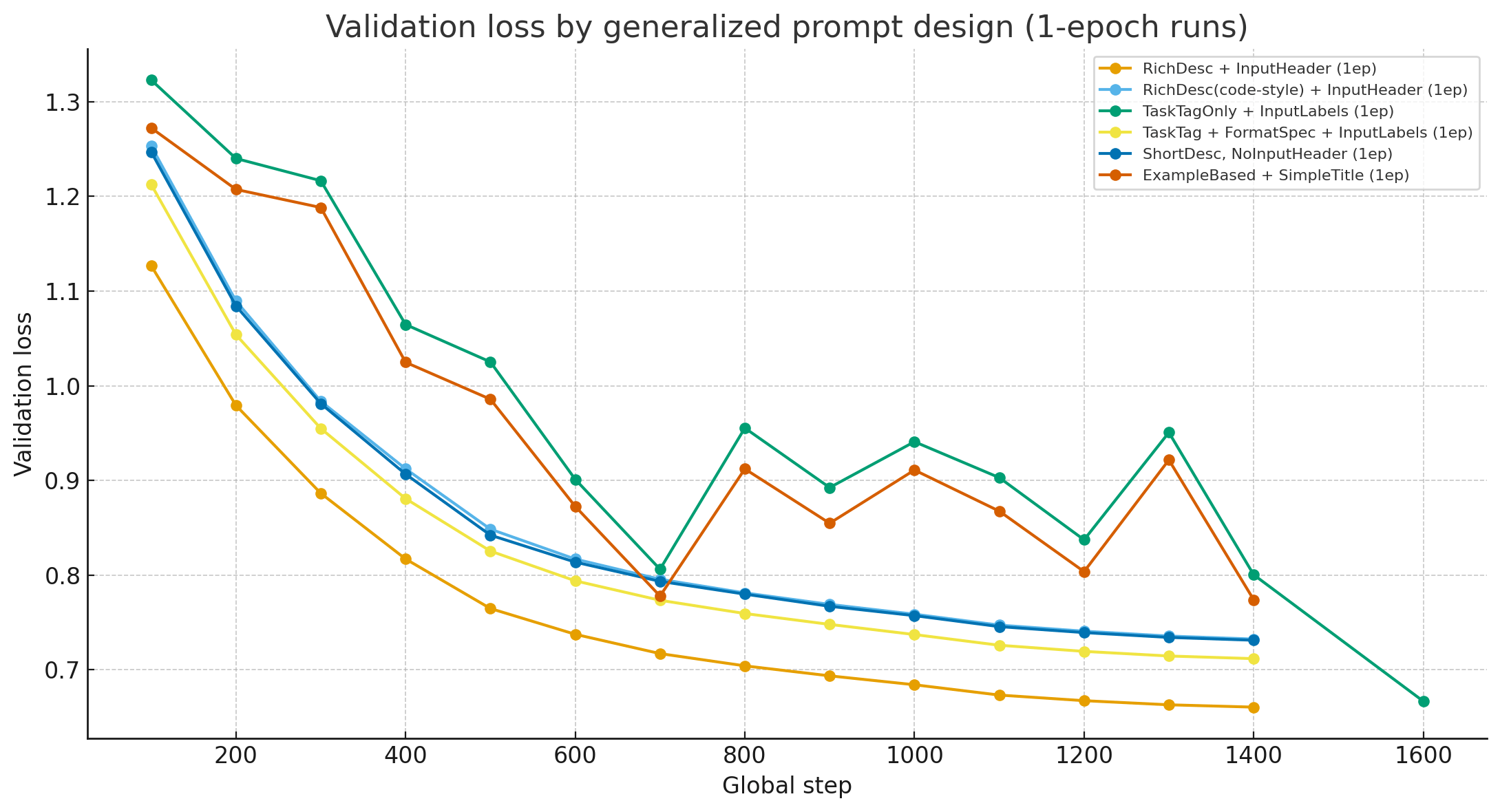
프롬프트 단축 실험 예시
준비된 학습 데이터를 기반으로 SFT를 진행하면서, 다양한 단축 형식을 실험했습니다. 아래는 실제 테스트한 프롬프트 형식 예시입니다.
예시 1: 최소 축약형
#OY-TASK: 올리브영 리뷰 테마 추천용 표현을 추출
상품: {goods_nm}
리뷰: {review}예시 2: 구조적 명시형
<올리브영 리뷰 테마 추천용 표현을 추출>
수식하는 표현은 2 단어보단 많아야해
적절한 표현이 없다면 공백 목록만 반환 [""]
<input review>
상품: {goods_nm}
리뷰: {review}예시 3: 예시 기반 형식
# 올리브영 리뷰 표현 추출
example : ["사용감 : 순하고 자극 없는 '미스트'"]
input : {goods_nm}
"{review}"최종 프롬프트 형식
실험 결과, 다음 구성의 템플릿이 성능 유지 + 토큰 단축 관점에서 가장 우수했습니다.
#OY-TASK: 올리브영 리뷰 테마 추천용 표현을 추출
#FORMAT: 긍정적 표현만, 카테고리+표현, JSON 리스트
상품: {goods_nm}
리뷰: {review}이 템플릿은 아래와 같은 구성을 통해 최소한의 토큰으로도 안정적인 결과를 제공합니다.
- 짧고 명확한 task 명명(#OY-TASK)
- 출력 형태를 강제하는 FORMAT 규칙
- 불필요한 설명 없이 input만 제시
성능 비교
표현 추출 모델 기준으로 정규식의 형식/어미 alignment 검증과 LLM as a judge 방법론으로 LLM을 통해서 문맥을 검증했습니다. 평가/벤치마크를 위한 비교 대상은 모델 개발 시점 Gemini flash 버전인 2.0 기준으로 압축하지 않은 프롬프트로 질의하여 비교했습니다.
평가 설정
위의 정확도 평가는 리뷰 샘플에 대해 내부에서 정의한 기준으로 레이블과 모델 출력을 비교해 산출한 상대 지표입니다.
Gemini 2.0 flash 기반 결과를 기준값 1.0으로 두고, 같은 검증 셋에서 Gemma3-4B의 SFT 모델의 상대적인 정확도를 측정한 값이 0.95입니다.
Gemini는 생성 결과 비교 및 벤치마크(LLM as a judge) 용도로만 사용했고 SFT 학습/레이블 생성에는 사용하지 않았습니다.
실제로 두 모델의 출력을 비교해보면, 유사한 품질의 결과를 생성합니다. 아래는 실제 리뷰에 대한 두 모델의 출력 예시입니다:
예시 1
리뷰: 블랙프라이데이 때 특가로 득템했는데 무난하게 수분 채워주기 좋아요! 안개분사~
Gemini: ["무난하게 수분 채워주는 '미스트' : 효과"]
Ours: ["수분 채워주기 좋은 '미스트' : 보습력"]예시 2
리뷰: 이젠 집에 없으면 안될 제품이에여 몇통째 먹고있는제품인데
젤 괜찮은제품같아요 속쓰림 속부대낌 그런거 없어요 굿굿
Gemini: ["속쓰림 속부대낌 없는 '기능식품' : 효과"]
Ours: ["속쓰림 없이 편안한 '영양제' : 효과"]Key Takeaways
결론적으로 도메인 특화 SFT를 통해 상용 LLM 대비 약간의 정확도 손실(5%p 이내)이 있었지만, 서비스에 필요한 수준의 품질을 충분히 확보할 수 있었습니다.
속도 및 운영 관점 해석
속도는 각 환경에서 측정한 평균 응답 시간입니다.
Gemini 2.0 flash는 GCP API 기준 16개 동시요청 시 약 0.8초이며, Gemma3-4B SFT 모델은 Tesla T4 16GB 환경에서 batch size 16 기준 한 배치를 처리하는 데 약 0.6초가 소요되었습니다. GCP Gemini API의 동시 호출의 한계가 있으나, 자체 LLM은 Scale-Out으로 Throughput을 충분히 늘려 원하는 만큼의 처리가 가능하다는 장점이 있습니다.
자체 sLLM은 배치 처리 전제가 있기 때문에 실제 단일 요청 단위 처리 시간과 전체 처리량(throughput) 관점에서는 상용 LLM 대비 더 유리하게 동작할 수 있으며, 호출량이 증가해도 GPU 인스턴스 단가 범위 내에서 비용 상한을 예측 가능하게 유지할 수 있다는 장점이 있습니다
자체 sLLM을 SFT하며 얻은 것
학습 목표, 품질 기준을 먼저 고정하기
LLM에게 “좋은 품질의, 내가 원하는 느낌의 결과”를 막연히 기대하는 것은 올바른 접근 방식이 아닙니다.
모델이 제대로 학습하려면 어떤 출력이 좋은 결과인지를 구체적인 기준으로 정의해야 합니다. 이를 검증 가능하게 형식화하는 것이 필수적입니다. 그래야만 해당 Task를 안정적으로 학습시킬 수 있습니다.
실제 리뷰 테마 프로젝트 과정에서는 초기 기획 단계의 콘셉트와 서비스 UI가 변경되면서 학습 목표가 여러 차례 수정되었습니다. 그 결과 이미 학습을 마친 모델의 출력을 서비스 직전에 다시 필터링해야 하는 비효율이 발생하기도 했습니다.
이 경험을 통해, 학습 전에 목표와 품질 기준을 충분히 합의·고정해 두는 것이 sLLM 프로젝트의 성패를 좌우하는 핵심 요소라는 점을 다시 한 번 확인했습니다.
Human-in-the-loop 검수의 필요성
리뷰테마 추천은 사용자 화면에 직접 노출되는 콘텐츠이기 때문에 자동 검증 모델만으로는 충분하지 않습니다. 1차적으로는 검증 모델을 통해 필터링을 수행하지만, 최종적으로는 사람이 직접 확인하는 단계가 반드시 필요합니다.
이를 위해서는 정량적·정성적으로 명확한 검증 기준이 정의되어 있어야 하며, 사람이 그 기준에 따라 일관되게 검수할 수 있어야 합니다.
올리브영의 첫 번째 자체 sLLM의 의미
이번 프로젝트는 NVIDIA Tesla T4 16GB라는 매우 한정된 자원 환경에서 sLLM을 학습하고 서비스에 성공적으로 적용할 수 있음을 검증한 올리브영의 첫 사례라는 점에서 큰 의미가 있습니다.
비록 완벽한 결과는 아닐지라도 범용 LLM에 의존하지 않고 비용 효율적이면서도 빠른 개선이 가능한, 우리만의 도메인 특화 sLLM을 구축할 수 있다는 가능성을 명확히 확인했습니다. 이는 향후 올리브영이 도메인 특화 AI를 전방위로 확장해 나가는 데 있어 견고한 기술적 기반이 될 것입니다.
앞으로의 방향성
리뷰 테마 추천은 올리브영 내부에서 sLLM 역량을 쌓는 파일럿 프로젝트이자, 전자신문 등 외부 매체에 '고객 리뷰 기반 생성형 추천' 사례로 소개된 의미 있는 레퍼런스입니다. 우리는 이 첫 번째 버전을 출발점 삼아 기술적 고도화를 진행 중입니다.
참고
CJ올리브영, 자체 'sLLM' 개발... AI가 'K뷰티' 골라준다 (전자신문, 2025년 9월 16일)
표현 품질 개선을 위한 개선 작업
리뷰 텍스트를 기반으로 생성된 추천 표현 중에는 문맥이나 문법적으로 UI에 노출하기 적합하지 않은 문장도 일부 포함됩니다. 이를 개선하기 위해, 생성된 표현을 임베딩 공간에서 클러스터링하고 군집 중심에서 벗어난 outlier 표현을 자동으로 제거하는 방식을 적용하고 있습니다.
이를 통해 더 자연스럽고 안정적인 품질의 표현만 최종 추천에 반영되도록 개선하고 있습니다.
카드 이미지 자동 생성 개발
현재는 UI/UX 팀이 제작·리터칭한 소수의 이미지를 사용하고 있어, 추천 내용이 달라도 유사한 카드가 반복 노출되는 한계가 있습니다. 이에 따라 이미지 생성 파이프라인을 자동화하여, 아래와 같은 목표로 개발을 진행 중입니다. 자동화로 더 많은 이미지를 생성해서 추천 카드를 더 신선하고 자연스럽게 확장 가능한 형태로 전환하려고 합니다.
- 다양한 스타일과 구성의 이미지 생성
- 리뷰·추천 내용과 연동된 맞춤형 시각 요소 생성
- 운영 비용 절감 및 이미지 다양성 확보
더 크고 복잡한 Task를 위한 LLM 개발
시작은 4B 규모의 작은 모델과 간단한 생성 과업이었지만, 이번 경험은 우리에게 큰 자신감을 주었습니다. 앞으로는 더 크고 복잡한 태스크를 수행할 수 있는 대형 모델 학습에 도전하며, 올리브영의 다양한 도메인 문제를 AI로 해결해 나가는 여정을 멈추지 않을 것입니다.
