

들어가며
Redis는 현대 백엔드 시스템 아키텍처에서 빼놓을 수 없는 핵심 구성 요소입니다. 인메모리 데이터 구조 저장소로서 캐싱뿐 아니라 세션 관리, 메시지 브로커 등 다양한 케이스에 유연하고 쉽게 적용할 수 있습니다. 특히 StackOverflow 2024년 가장 인기있는 데이터베이스 기술에서 6위를 차지하며(NoSQL중 2위), 많은 개발자들이 애정하는 데이터베이스로 자리매김했습니다.
저 역시 백엔드 개발자로 다양한 서비스를 운영하며 Redis와 함께해왔는데요. 지금까지 많은 도움을 얻었지만, 돌이켜보니 Redis 초기 도입 과정에서 "이걸 미리 알았더라면 더 수월했을 텐데..."라는 아쉬움이 남는 순간들이 꽤 있었습니다. 🤔 이번 포스트에서는 그때 겪었던 시행착오를 바탕으로, Redis를 도입하거나 활용도를 높이려는 개발자분들께 도움이 될 만한 실전 팁들을 공유해보려 합니다. 제가 겪은 어려움을 반복하지 않으시길 바라는 마음으로 정리한 Redis 사용 꿀팁, 함께 살펴보시죠!
반드시 TTL(Time-To-Live)을 설정하세요
Redis에 데이터를 저장할 때 TTL(Time-To-Live, 데이터 유효 시간)을 설정하는 것은 단순한 선택 사항이 아닌 필수적인 설정입니다. 많은 개발자들이 이 사실을 알고 이행합니다. 그렇다면 왜 TTL을 설정해야할까요? 두가지 관점으로 설명해보겠습니다.
소중한 메모리 자원 낭비 방지
Redis는 빠른 속도를 자랑하는 인메모리(In-Memory) 데이터 저장소입니다. 하지만 메모리는 용량이 한정적이고 비용이 비싼 자원이기 때문에 효율적인 관리가 매우 중요합니다. TTL이 없는 데이터는 메모리에 계속 쌓이게 됩니다.
이렇게되면 결국 물리적인 메모리 한계를 초과하여 메모리 고갈(OOM) 현상을 야기할 수도 있습니다. OOM이 발생하면 Redis 서버는 더 이상 새로운 데이터를 쓰지 못하거나, 심각한 경우 서버가 다운되어 전체 시스템 장애로 이어질 수 있습니다.
OOM이 발생하지 않더라도 불필요한 데이터가 메모리를 계속 점유하고 있다면 비싼 메모리 자원을 낭비하는 것과 같습니다. 더 많은 메모리를 확보하기 위해 스케일업(Scale-up)을 하는 상황을 피할 수 있게 해줍니다.
OOM이 발생하면 Redis 서버는 더 이상 새로운 데이터를 쓰지 못하거나, 심각한 경우 서버가 다운되어 전체 시스템 장애로 이어질 수 있습니다.
서비스 운영에도 도움이 돼요
인프라 자원 외에도 개발 관점에서도 TTL 있다는 것은 복잡도를 낮추고 데이터의 정합성을 유지하는 데 큰 장점을 가집니다.
데이터의 최신성 보장
많은 경우 데이터는 특정 시간 동안만 유효합니다. 예를 들어, '오늘만 보이는 팝업', '1시간 동안 유효한 인증번호', '5분간 유지되는 세션 정보' 등이 대표적입니다. 만약 TTL을 사용하지 않는다면, 개발자는 직접 데이터의 생성 시간을 기록하고, 조회 시마다 현재 시간과 비교하여 데이터의 유효성을 검사하고, 별도의 스케줄러를 통해 기간이 만료된 데이터를 삭제하는 로직을 모두 구현해야 합니다. TTL을 설정하면 이러한 복잡한 로직을 Redis에 위임하여 애플리케이션 코드를 단순하고 명료하게 유지할 수 있으며, 데이터가 항상 최신 상태로 유지되는 것을 보장할 수 있습니다.
캐시 데이터의 정합성 유지
Redis는 주로 데이터베이스의 부하를 줄이기 위한 캐시(Cache) 서버로 많이 활용됩니다. 캐시 데이터는 원본 데이터베이스(Source of Truth)의 복사본이므로, 시간이 지나면 원본 데이터와의 정합성이 깨질 수 있습니다. TTL을 설정하면 캐시 데이터가 일정 시간 후에 자동으로 삭제되도록 하여, 주기적으로 원본 데이터베이스에서 새로운 데이터를 가져오게끔 유도할 수 있습니다. 이를 통해 사용자는 오래된 캐시 데이터가 아닌, 정합성이 보장된 데이터를 제공받을 수 있습니다.
장애 상황에서의 데이터 자동 정리
특정 작업 중에만 일시적으로 사용되는 데이터(예: 작업 진행 상태를 나타내는 플래그)가 있다고 가정해 보겠습니다. 만약 애플리케이션에 예기치 않은 장애가 발생하여 정상적으로 데이터를 삭제하는 로직을 수행하지 못하고 종료된다면, 이 임시 데이터는 '쓰레기 데이터'가 되어 메모리에 영원히 남게 됩니다. TTL을 설정해두면 애플리케이션에 장애가 발생하더라도 정해진 시간 후에 Redis가 알아서 데이터를 정리해주므로, 시스템의 안정성과 데이터의 일관성을 높일 수 있습니다.
이처럼 Redis에서 TTL을 설정하는 것은 단순히 메모리를 아끼는 차원을 넘어, 시스템의 안정성을 담보하고, 개발의 복잡성을 낮추며, 데이터의 정합성을 보장하는 좋은 습관입니다. 따라서 특별한 이유가 없는 한, Redis에 저장되는 모든 데이터에는 반드시 적절한 TTL을 설정하는 습관을 들이는 것이 좋습니다.
하나의 키에 사이즈가 큰 데이터를 저장하지마세요(Big Key Problem)
Redis에 데이터를 저장할 때 사이즈가 너무 큰 데이터를 저장하지 않도록 주의해야합니다. (일반적으로 크기가 1MB를 초과하는 문자열 유형 값이나 10,000개가 넘는 요소를 포함하는 컬렉션 유형 키를 사이즈가 큰 데이터로 간주합니다.)
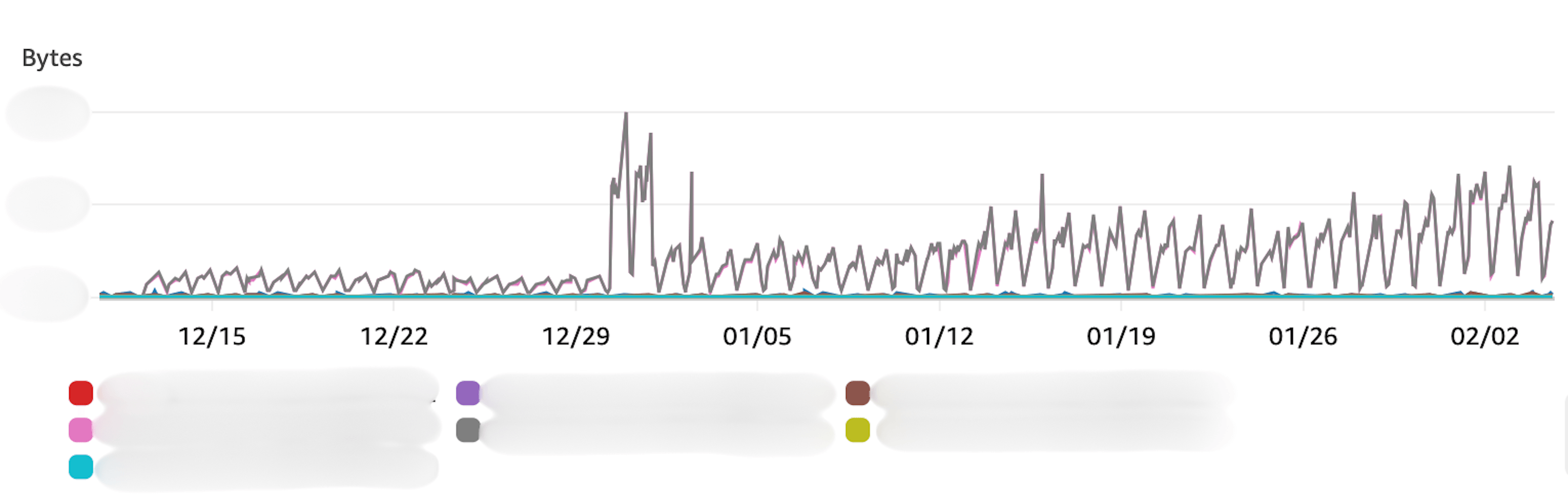
부끄러운 일화 하나를 소개할게요. 어느날 SRE 파트에서 특정 노드의 송/수신 바이트 수가 이상하게 많다는 제보가 있었습니다. 알고 보니 그 원인은 저였습니다🫣. 하나의 String 자료형에 10MB가 넘는 데이터를 저장했기 때문이었죠😂
왜 하나의 키에 사이즈가 큰 데이터를 저장하면 안될까요? 다음과 같은 이유가 있습니다.
메모리 소비 및 단편화
대용량 String은 상당한 양의 RAM을 직접적으로 소비합니다. 큰 연속 블록을 저장하면 메모리 단편화(fragmentation)를 유발하여, 사용 가능한 전체 메모리가 충분하더라도 Redis가 효율적으로 메모리를 할당하기 어렵게 만들 수 있습니다.
성능 저하
많은 양의 메모리를 차지하여 메모리 단편화를 심화시키고 Redis 성능에 영향을 미칩니다. 읽기, 쓰기, 삭제와 같은 큰 키 관련 작업은 더 많은 CPU 시간과 메모리 리소스를 소모하여 시스템 성능을 더욱 저하시킵니다.
과도한 네트워크 리소스 유발
하나의 키에서 대량의 네트워크 트래픽이 발생하여 네트워크 대역폭이 포화되고 서비스에 영향을 미칠 수 있습니다. 예를 들어, 큰 키의 크기가 1MB이고 초당 1,000회 액세스되는 경우 1,000MB(1GB)의 트래픽이 발생합니다.
동기화 지연
사이즈가 너무 큰 데이터는 동기화 지연을 발생시킬 수 있습니다. 예를 들어, RDB 스냅샷과 AOF 파일의 크기를 증가시켜 영속화 작업의 속도를 늦추고 더 많은 리소스를 소모할 수 있습니다
데이터 불균형
Redis 클러스터 모드에서 특정 샤드에 데이터가 편중되어 다른 샤드보다 메모리를 훨씬 많이 사용하는 메모리 불균형이 발생할 수 있습니다. 이 상태에서 특정 샤드의 메모리 사용량이 maxmemory에 설정된 임계값에 도달하면, 메모리 정책에 따라 키를 제거하게 되면 중요한 데이터가 의도치 않게 삭제될 위험이 있습니다.
따라서 Redis에 데이터를 저장할 때는 데이터의 사이즈가 과하게 크지 않나 항상 주의해야합니다.
Redis의 다양한 Data Type을 활용해보세요
Redis를 캐싱과 세션 관리 용도로 사용하는 경우가 많은데, 이 외에도 활용 범위가 넓습니다. 그중에서 Data Type을 활용한 몇가지 사례를 소개합니다. 서비스 운영에 인사이트를 얻을 수 있을 거에요.
정렬이 필요하면 Sorted Set을 고려해보세요
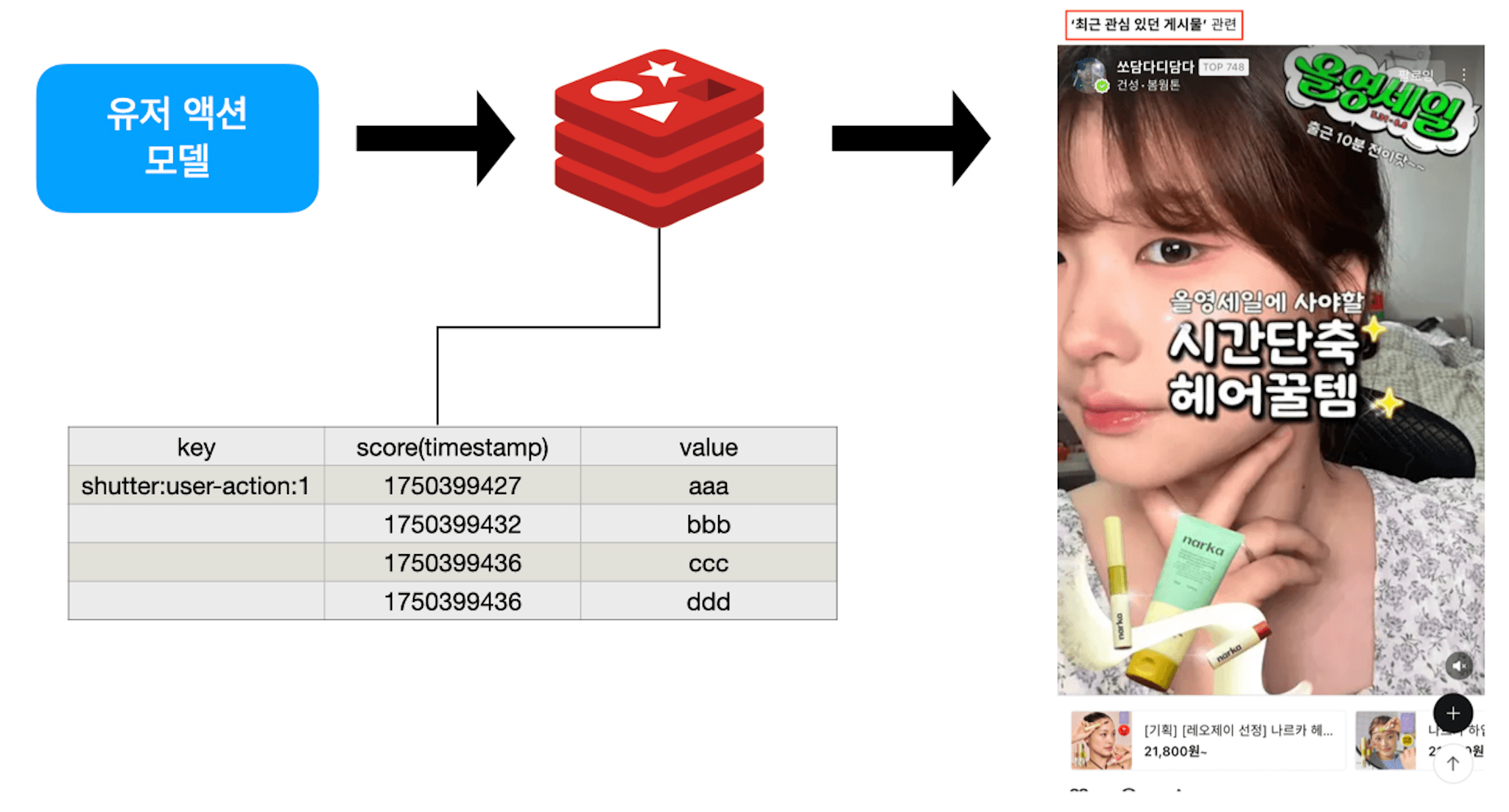
저의 사례를 소개하자면 저는 올리브영의 커뮤니티 서비스 '셔터'를 개발하면서 Redis의 Sorted Set을 활용하고 있습니다. Sorted Set은 Redis가 지원하는 Data Type으로 하나의 key에 여러 Score와 Value로 구성된 자료구조입니다. value는 중복되지 않으며 score 기준으로 정렬될기 때문에 랭킹과 같은 정렬이 필요할 때 매우 유용한 Redis의 Data Type입니다.
셔터에서는 유저의 최근 행동 데이터를 근거로 추천 피드를 구성합니다. Sorted set은 유저가 동작한 시간을 timestamp로 변환해 score에 저장하는 방식으로 활용됩니다. 유저의 행동 데이터를 시간순으로 정렬할 수 있기 때문에 유저의 최근 행동을 기반한 추천 게시물을 피드로 노출할 수 있습니다.
객체를 그대로 저장하기 보단 Hash를 사용하세요
Redis에 데이터를 저장할 때 객체를 직접 직렬화(Serialization)하여 String 형태로 저장하시나요? 그럴 경우 새로운 필드가 추가/삭제 될 경우 곤란해질 수도 있습니다. 예를 들어보겠습니다.
상황 1: 객체를 직접 직렬화한 경우
초기 버전 (V1): User 클래스에 id와 name만 있습니다.
class User implements Serializable {
private Long id;
private String name;
}이 V1 객체를 직렬화하여 user:1 키에 저장했습니다. 이 데이터 안에는 id와 name에 대한 정보만 바이너리 형태로 들어있습니다.
요구사항 변경 (V2): email 필드를 추가해야 하는 상황이 발생했습니다.
class User implements Serializable {
private Long id;
private String name;
private String email; // 필드 추가!
}문제 발생: 새로운 V2 코드가 Redis에서 user:1 데이터를 읽어옵니다.
V2 코드는 이 데이터를 V2 User 객체로 역직렬화하려고 시도합니다. 하지만 데이터 안에는 email 필드에 대한 정보가 없으므로, 역직렬화 과정에서 InvalidClassException과 같은 심각한 오류가 발생하며 애플리케이션이 중단될 수 있습니다. 이처럼 데이터의 구조가 코드의 클래스 구조와 강하게 결합(Tightly Coupled)되어 있어, 코드 변경이 데이터의 호환성을 깨트리는 결과를 낳습니다. 이러한 문제를 해결하는 좋은 방법은 Redis의 해시(Hash) 데이터 타입으로 저장하는 것입니다. 해시는 하나의 키(Key) 아래에 여러 개의 필드(Field)와 값(Value)을 가질 수 있는 자료구조로, 객체를 표현하기에 좋습니다.
상황 2: 해시(Hash)를 사용한 경우 초기 버전 (V1): User 클래스에 id와 name만 있습니다.
HSET user:1 id "1" name "Alice"요구사항 변경 (V2): email 필드를 추가해야 하는 상황이 발생했습니다.
새로운 사용자를 등록하는 V2 코드는 이제 email 필드도 함께 저장합니다. 기존 사용자 정보에 이메일을 추가해야 한다면, 간단히 HSET 명령만 실행하면 됩니다
HSET user:1 email "alice@example.com"V2 코드가 user:1 데이터를 읽으면 id, name, email 세 필드를 모두 정상적으로 가져와 사용합니다.
만약 아직 업데이트되지 않은 V1 코드가 user:1 데이터를 읽더라도, V1 코드는 자신이 아는 id와 name 필드만 사용하고 모르는 email 필드는 그냥 무시합니다. 오류가 발생하지 않습니다.
이렇게 Hash를 이용하면 필드가 추가/삭제되어도 유연하게 대응할 수 있습니다. 이 외에도 다양한 Data Type의 활용 사례들이 많습니다. 서비스 개발에 앞서 사용할 만한 Redis Data Type이 있을지 살펴보시길 권장합니다.
핫키(Hot Key) 만료시 주의가 필요해요
많은 분들이 Redis를 사용할 때 Redis는 메인 데이터베이스가 아닌 원천 데이터베이스의 캐싱을 위해 많이 사용합니다 앞서 말했듯이 캐싱이 목적이라면, Redis에 데이터를 저장할 때 TTL을 설정해야 합니다. 그리고 캐싱하려 저장한 데이터의 TTL이 만료되면, 일반적으로 원천 데이터베이스를 조회합니다.
요청이 집중되는 캐시 키를 흔히 '핫키(Hot Key)'라 부릅니다. 만약 핫키의 TTL이 만료되면 어떻게 될까요? Redis로 관리하던 수많은 요청이 원천 데이터베이스로 몰리게 됩니다. 원천 데이터베이스는 Redis만큼 빠르게 처리할 수 없으니 부하가 발생합니다. 결국 전체 서비스의 장애로 이어질 수도 있습니다.
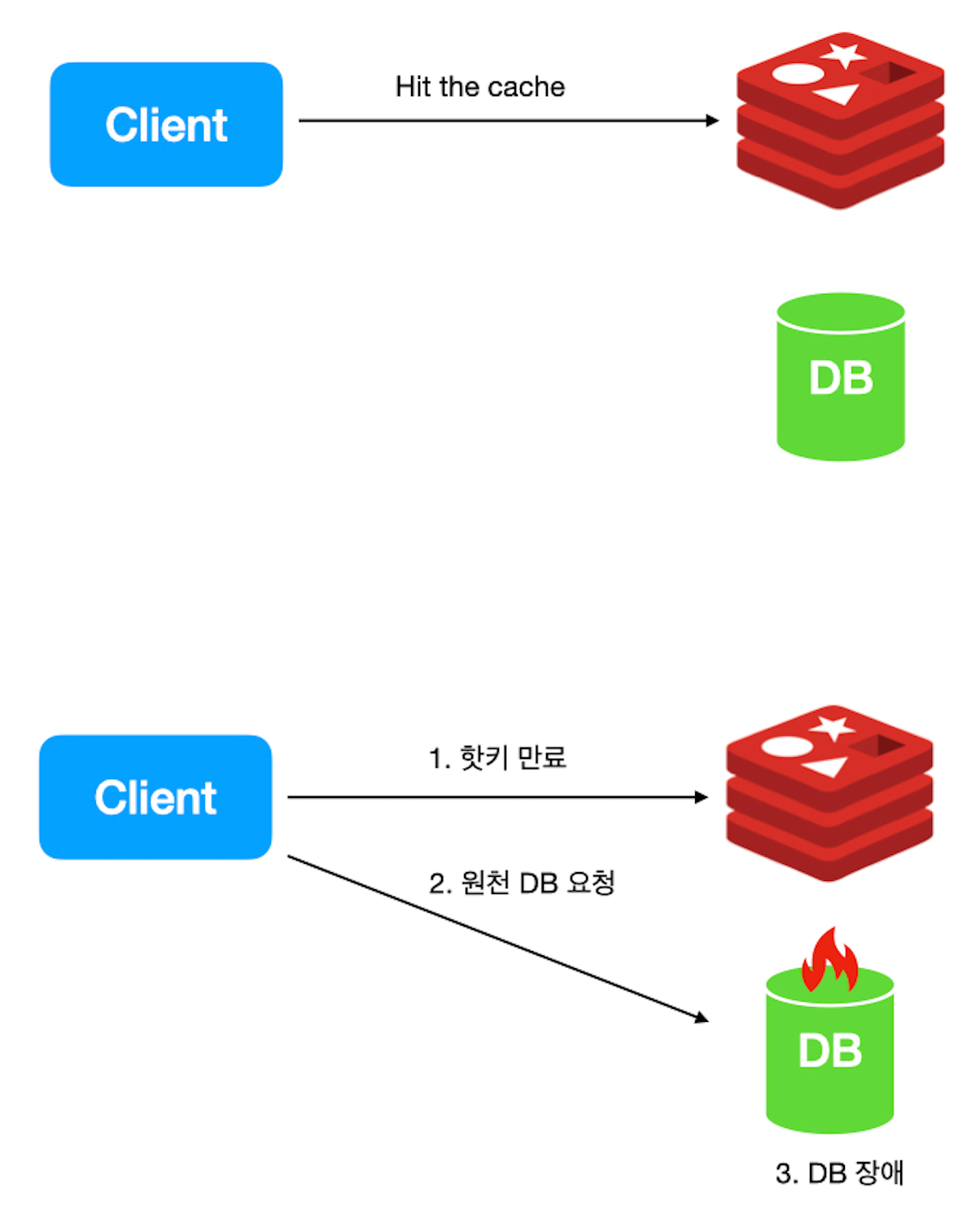
이러한 현상을 해결하기 위해 백그라운드에서 주기적으로 캐시를 갱신하거나 매 요청마다 일정 확률로 캐시를 갱신하는 PER 알고리즘을 적용하는 방식을 고려해보시길 권장합니다.
마치며
개발자로서 Redis를 사용할 때 도움이 될만한 몇가지를 소개해봤습니다. 잘 알려진 내용이라 생각되는 문항들도 있겠지만, Redis를 잘 아시는 분들에게는 리마인드되는 좋은 기회가 되었으면 좋겠습니다. Redis를 처음 사용하시거나 도입을 검토하는 분들에게 실용적인 팁이 되길 바랍니다.
