안녕하세요. 올리브영 플랫폼엔지니어링을 담당하는 무스타파🌙입니다.
지난 5월 15일부터 16일까지 코엑스에서 개최된 AWS Summit Seoul 2025에서 "소중한 우리의 시간을 위한 클라우드 스케일링 자동화"라는 주제로 Community Track에서 발표를 진행했습니다. 정말 많은 분들이 세션에 참석해주셔서 감사했습니다.
이 글에서는 발표에 사용된 슬라이드와 함께 주요 내용을 정리하여 공유하고자 합니다.
목차
올리브영의 클라우드

저희가 AWS 클라우드를 적극적으로 활용하게 된 주요 이유는 계절성 트래픽 대응입니다. 올리브영은 3월, 6월, 9월, 12월, 연 4회 대규모 세일을 진행하는데, 이때 평소 대비 약 10배의 트래픽이 발생합니다.
이러한 급격한 트래픽 증가에 대응하기 위해 AWS 클라우드를 선택했고, 현재는 대부분의 워크로드가 AWS 클라우드 위에서 운영되고 있습니다. 아마도 많은 분들이 비슷한 이유로 클라우드 서비스를 활용하고 계실 것으로 생각됩니다.

E-커머스 업계에서는 마케팅이 매우 중요한 요소입니다. 마케팅 없이는 E-커머스 비즈니스를 제대로 운영하기 어렵습니다.
마케팅 활동으로 인한 트래픽 증가는 매우 빈번하게 발생하며, 매달 약 10회 정도 트래픽 스파이크가 발생합니다. 인플루언서 협업이나 아이돌 굿즈 판매 시에도 트래픽이 급격히 증가합니다.
이러한 예측 불가능한 트래픽들을 어떻게 효과적으로 관리할 것인가 하는 문제가 우리의 핵심 과제였습니다.
실제 트래픽 패턴과 Auto Scaling의 한계
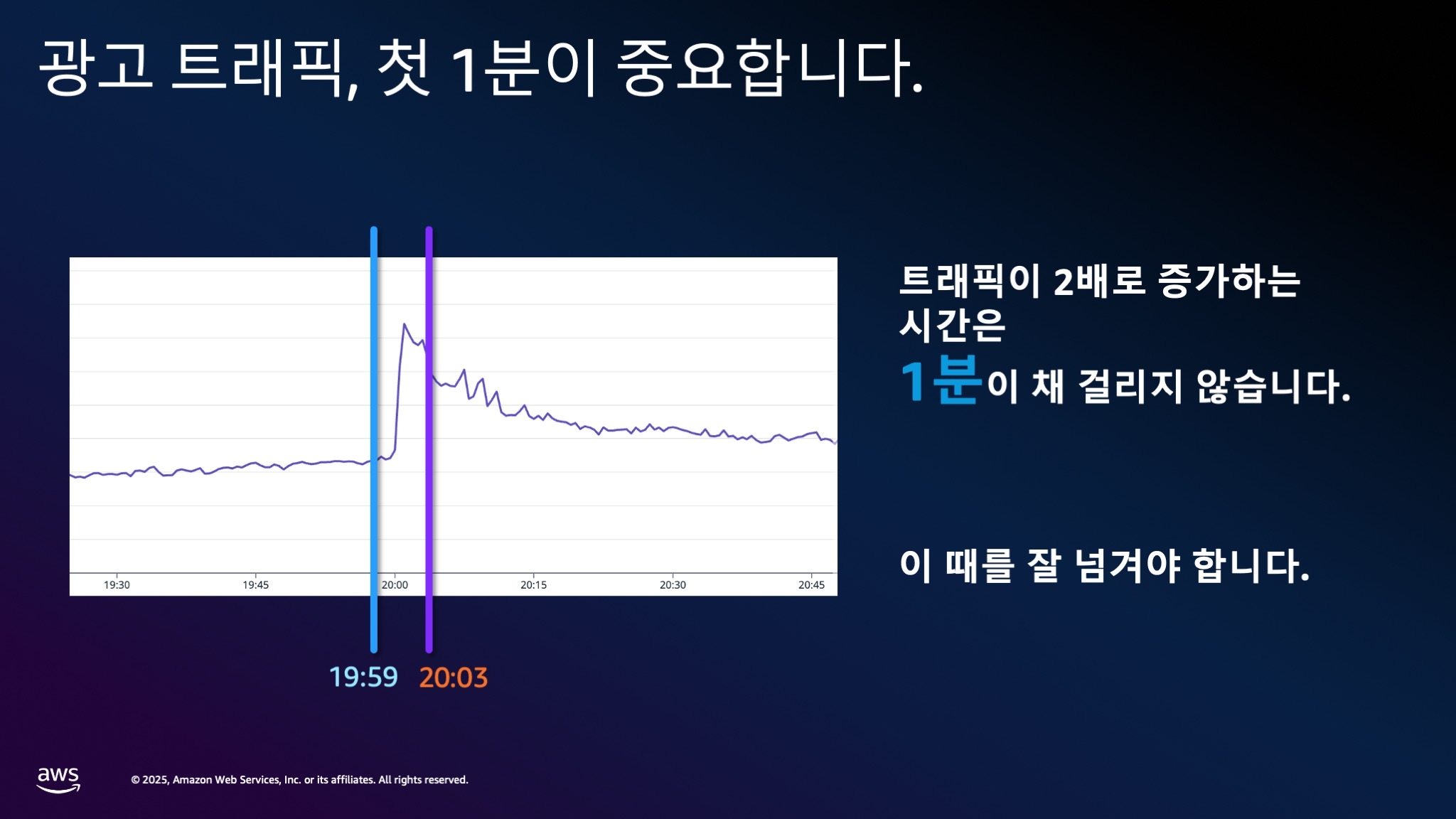
이 슬라이드는 실제로 저희가 자주 경험하는 광고 유입 트래픽 패턴입니다.
이 패턴을 살펴보면, 광고가 시작되는 순간 트래픽이 급격히 증가합니다. 예를 들어, 오후 7시 59분부터 8시 1분 사이에 트래픽이 두 배로 증가하는 경우가 있습니다. 단 2분만에 2배로 증가하는 상황입니다.
이런 급격한 변화에 대응하기 위해 일반적으로 Auto Scaling을 활용합니다만, 현실은 그리 단순하지 않습니다.
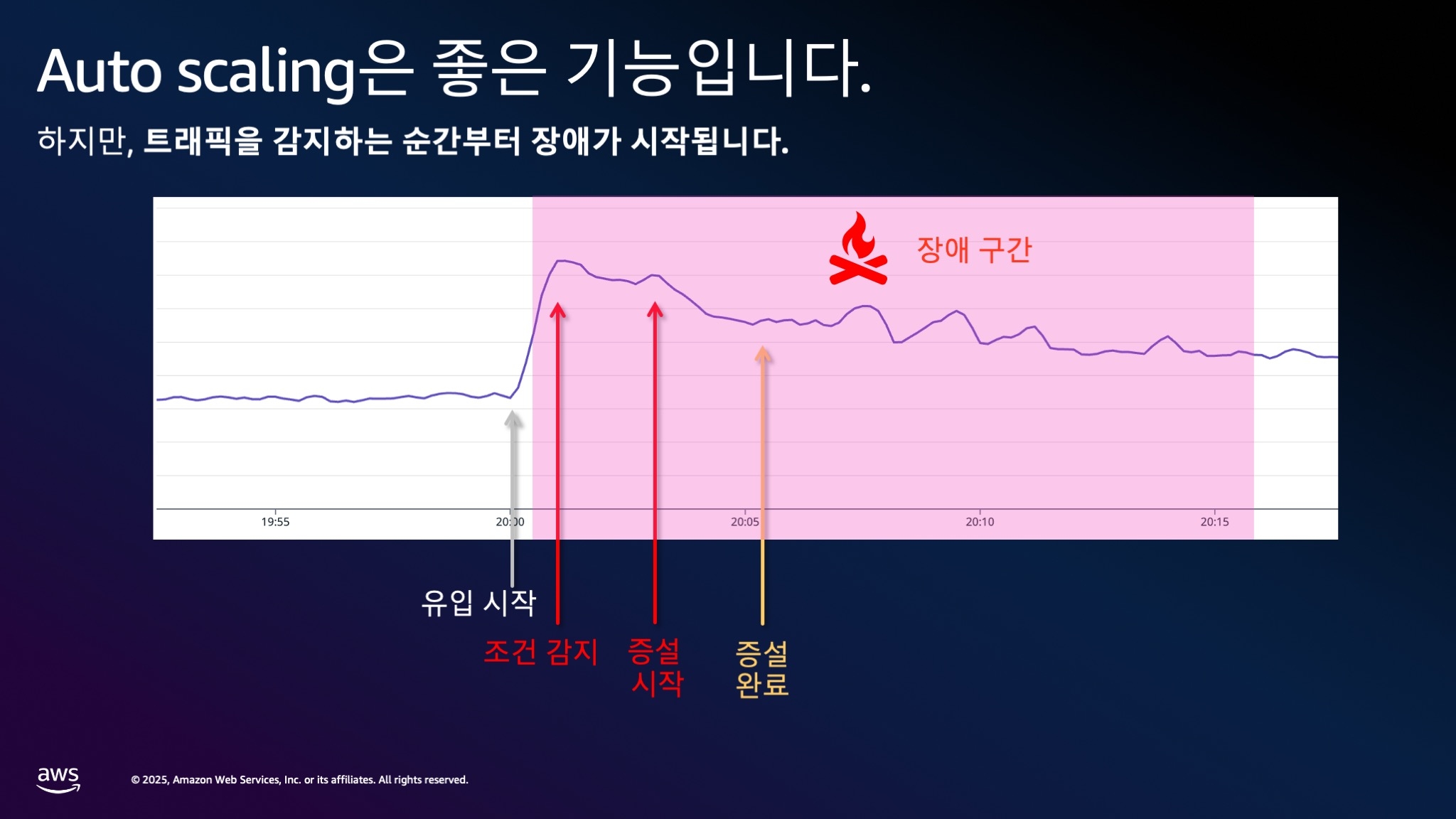
💡 핵심 포인트 Auto Scaling은 만능 도구가 아니라 '장애 시간을 줄여주는 보험' 정도로 이해하는 것이 적절합니다.
현실에서 Auto Scaling만으로는 효과적인 대응이 어려운 이유는 다음과 같습니다:
- 반응 지연: 트래픽이 급증한 후에야 Auto Scaling 조건이 충족됩니다
- 장애 시점: 조건 충족 후 증설이 시작되지만, 이미 장애는 시작된 상태입니다
- 복구 시간: 증설 완료까지 약 3-5분이 소요됩니다
- 사용자 경험: 결과적으로 첫 5분 동안의 트래픽은 모두 장애를 경험하게 됩니다
- 총 장애 시간: 시스템 회복까지 약 10분 정도 장애 상태가 지속됩니다
이렇게 되면 광고를 집행했음에도 장애만 발생하고, 효과는 없으며, 비용만 낭비하는 결과를 초래합니다.

따라서 우리는 Auto Scaling의 한계를 인정하고 새로운 접근 방법을 모색해야 합니다.
효과적인 스케일링 전략

그렇다면 어떻게 더 효과적으로 스케일링을 자동화하고 안전하게 할 수 있을까요?
저희는 운영자들이 밤잠을 설치지 않고 편안하게 쉴 수 있도록 4단계 접근법을 제안합니다.
1단계: 트래픽 카테고리화


트래픽이 어떤 형태로 들어오는지 카테고리를 나누는 것이 첫 번째 단계입니다.
트래픽을 카테고리로 나누는 것은 마치 자동차를 구매할 때 티코를 살 것인지, 아반떼를 살 것인지, 소나타를 살 것인지, 그랜저를 살 것인지 명확히 정하는 것과 같습니다.
명확한 목표와 경계를 정해두지 않으면 티코를 사려고 하다가 그랜저를 사려고 하는 상황이 발생할 수 있습니다. 트래픽 카테고리를 명확히 구분한다면, 대응 체계를 수립하는 데 훨씬 효율적입니다.
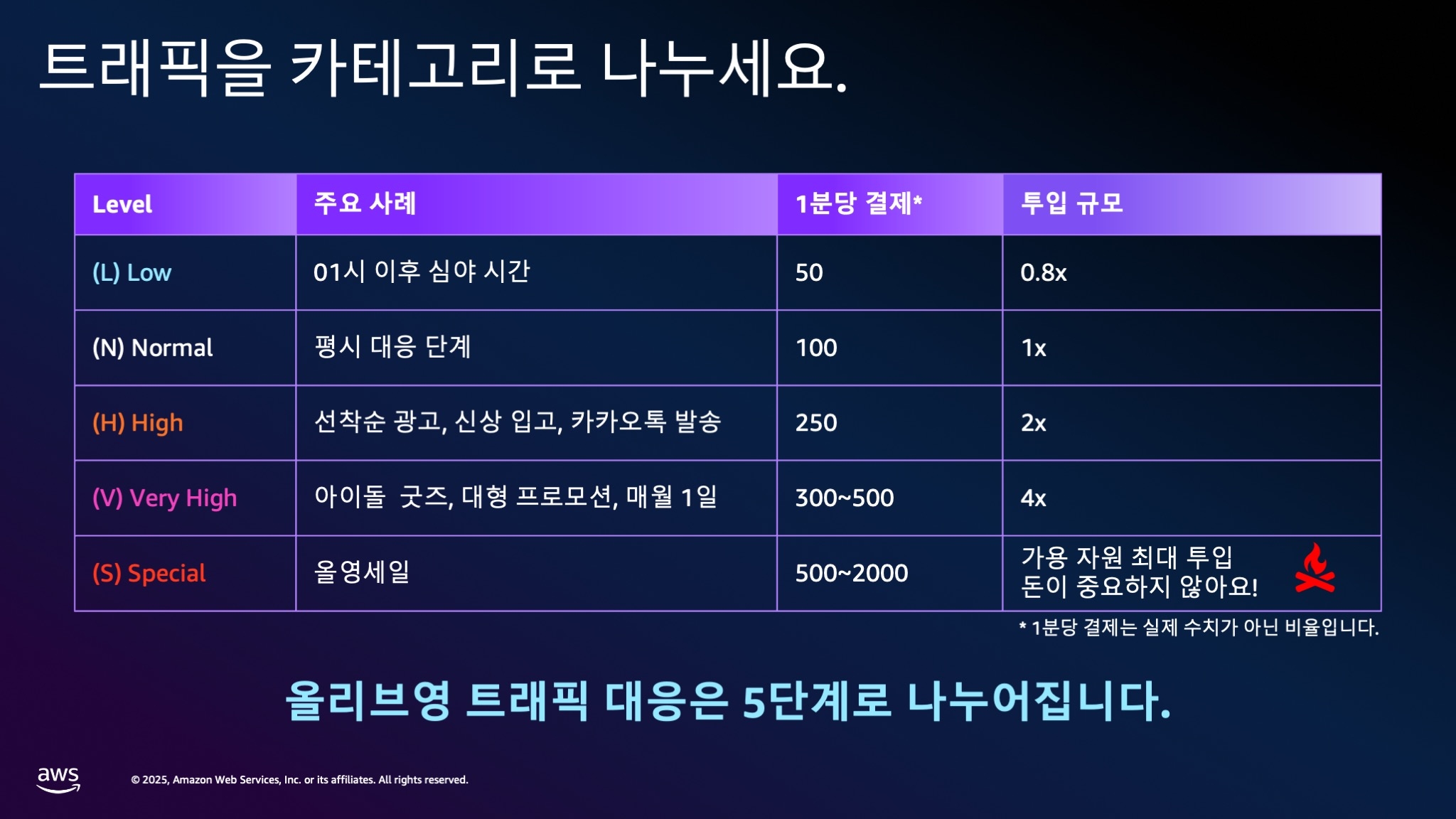
올리브영에서는 트래픽을 5단계로 구분합니다:
- Low: 야간 시간대 (비용 절감 목적)
- Normal: 평상시 트래픽
- High: 일반적인 광고 트래픽
- Very High: 인플루언서 마케팅, 아이돌 굿즈 판매 등
- Ultra High: 올영세일과 같은 대규모 이벤트
이러한 카테고리는 분당 결제 건수와 같은 핵심 비즈니스 KPI를 기준으로 정의합니다. 저희는 E-커머스 기업이므로 실제 판매량이 가장 중요한 지표입니다.
다른 업계는 각자의 핵심 KPI에 맞게 스케일링 기준을 설정해야 합니다. 각 회사의 특성을 잘 반영하는 지표를 개발하고, 그에 맞는 카테고리를 설정하는 것이 중요합니다.
2단계: 증설 대상 선정


카테고리로 트래픽을 정의했다면, 다음은 증설할 자원을 선정하는 작업입니다.
어떤 자원을 증설할지 정하는 것도 중요합니다. 모든 자원을 다 증설하는 것이 아니라, 전략적으로 선택해야 합니다.
예를 들어 웹/애플리케이션 서버(WAS)는 증설이 필요하지만, 백오피스 시스템은 증설하지 않아도 될 수 있습니다.
증설 대상을 선정할 때 가장 중요한 것은 고객의 행동 패턴입니다. 고객들이 우리 서비스에서 무엇을 원하는지 파악해야 합니다. 고객의 행동 패턴은 비즈니스와 밀접하게 연결되어 있고, 고객들이 자주 이용하는 서비스에 트래픽이 가장 많이 몰리기 때문입니다.
또 하나 중요한 것은 데이터 기반 의사결정입니다. 개발을 시작하고 서비스를 런칭할 때 "서버 몇 대 필요해?"라는 질문에 "많이 필요합니다!"라고 대답하는 경우가 많습니다.
하지만 운영을 한 달, 두 달, 6개월, 1년 해보면 분명히 데이터가 축적됩니다. 반드시 실제 데이터를 기반으로 판단해야 합니다.

데이터 수집을 위해서는 적절한 도구가 필요합니다. 마치 길이를 재려면 좋은 자가 있어야 하는 것과 같습니다.
대표적으로 CloudWatch는 기본적으로 많이 사용하실 것입니다. 저희는 Datadog을 주로 사용하고 있습니다. 유료이지만 대시보드 구성 등이 잘 되어 있습니다.
Grafana 같은 오픈소스 툴도 좋은 선택입니다. 비용 부담은 없지만 직접 구축하고 관리해야 하므로 관리 인력이 필요할 수 있습니다.

앞서 언급한 비즈니스 기반 모니터링을 위해 저희는 각종 비즈니스 지표에 대한 전용 대시보드를 구축했습니다.
이 비즈니스 대시보드를 통해 트래픽이 높은지 낮은지, 다음 상황이 어떻게 될지를 매일 모니터링하고 패턴을 파악합니다.
📚 참고자료 올리브영 DASH 2024 발표자료에서 비즈니스 대시보드 구성 사례를 확인할 수 있습니다.

어떤 자원을 증설해야 할까요?
증설 필요 자원:
- WAS 계열 (웹 애플리케이션 서버)
- 웹 서버 계열
- DB 계열
증설 불필요 자원:
- 서버리스(Serverless) 자원 - 자동 스케일링
- CDN 서비스 - 관리형 서비스
💡 실용적 팁 서버리스 자원을 많이 활용하면 직접 프로비저닝하고 증설해야 하는 자원의 양이 줄어들어 훨씬 효율적으로 운영할 수 있습니다.
프로비저닝이 필요한 자원들에 대해서는 명확한 원칙이 있어야 합니다. 예를 들어, '5분 이내에 무조건 증설을 시작할 수 있어야 한다'와 같은 원칙입니다.
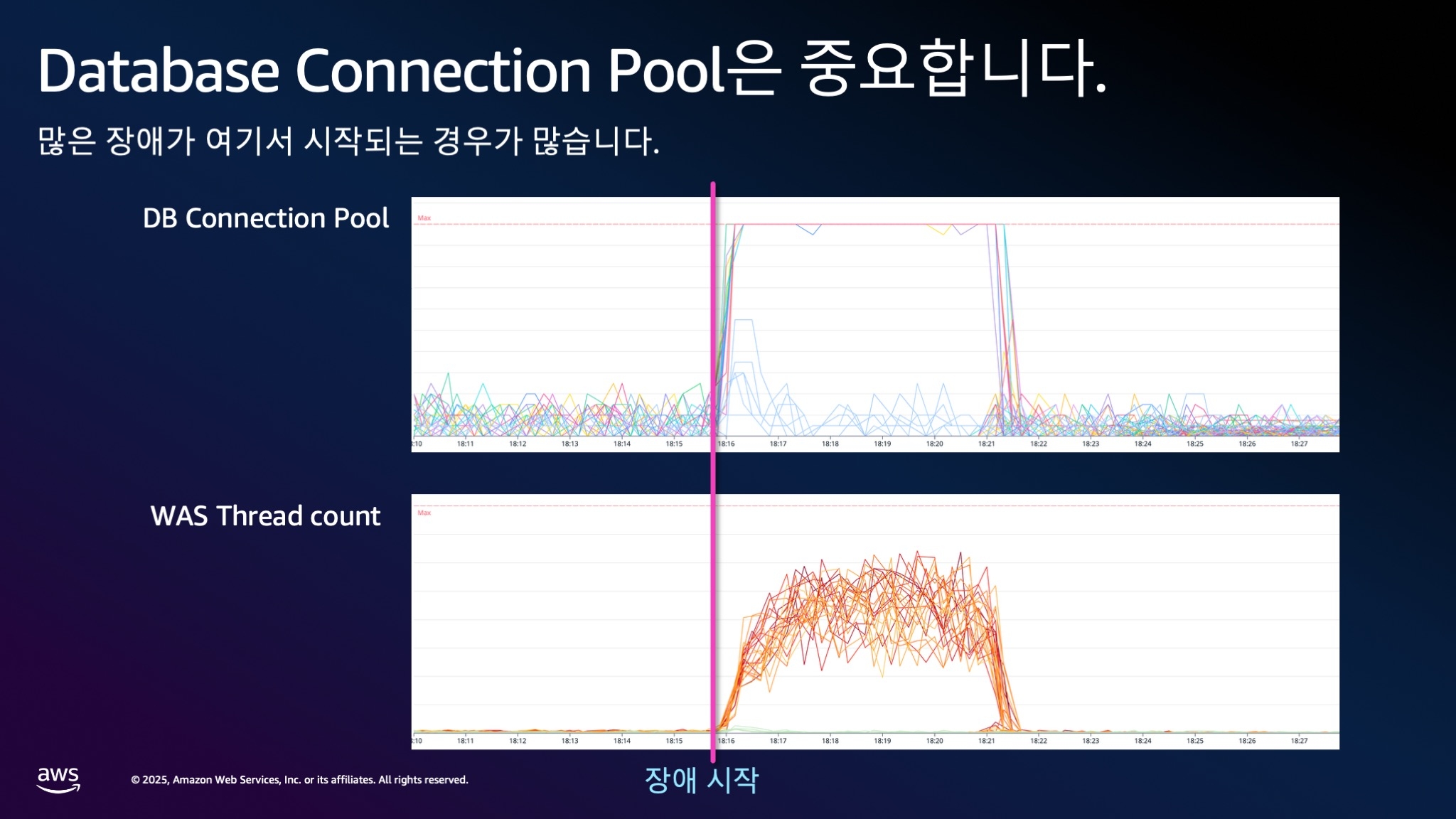
특별히 주의해서 모니터링해야 할 지표가 있습니다.
특히 Oracle DB를 사용하는 경우, WAS의 DB 커넥션 풀(Connection Pool)을 주의 깊게 모니터링해야 합니다. 커넥션 풀이 가득 차면 시스템이 즉시 다운됩니다.
⚠️ 주의사항 DB 커넥션 풀이 가득 차면 바로 장애로 이어지며, 실제로 이로 인한 장애 비율이 매우 높습니다.
시스템 CPU만 모니터링할 것이 아니라, 장애를 유발할 수 있는 다른 핵심 지표들도 선정해서 경험적으로 데이터를 축적하고, 그에 맞춰 증설 대상을 정의해야 합니다.
3단계: 증설 방법 구현

이제 '어떻게' 증설할지 구현 방법을 찾아야 합니다.
효과적인 오퍼레이션을 위한 핵심 원칙:
- 기존 도구 활용: 팀에서 이미 사용하던 도구를 잘 활용
- 멀티 플랫폼: PC와 모바일 양쪽 모두 지원
- 간편성: 복잡한 도구보다는 간편한 도구 선택
AWS 콘솔도 좋지만, 앞서 말한 간편함의 원칙에는 다소 부족하고 모바일에서 사용하기 어려운 측면이 있습니다.
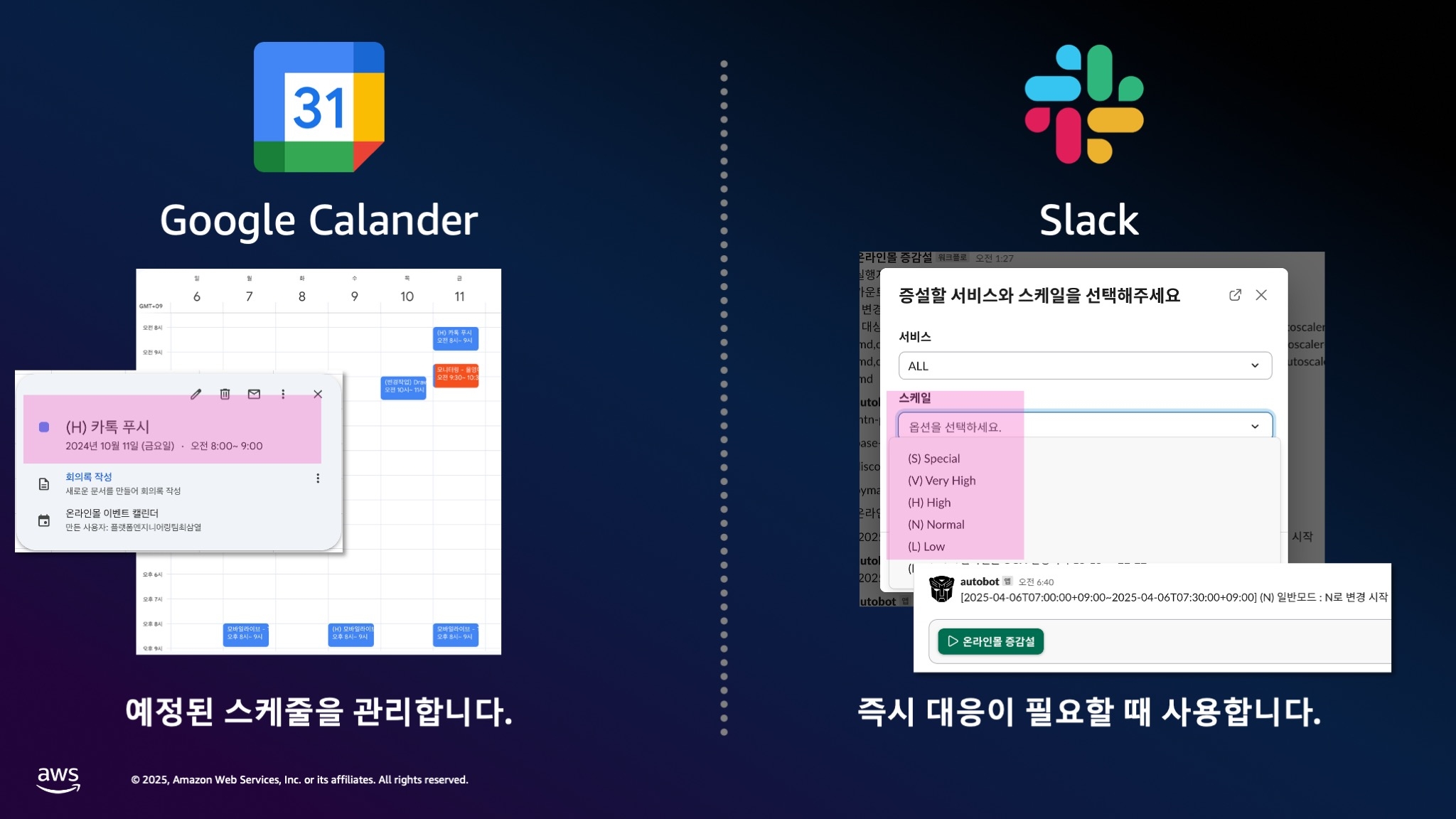
저희는 Slack과 Google Calendar를 활용합니다. 대부분 회사에서 사용하고 있는 도구들입니다.
Google Calendar 활용:
- 매달 발생하는 이벤트 스케줄 등록
- '(H)' 프리픽스와 함께 이벤트 등록
- 프리픽스를 보고 자동으로 해당 레벨로 증설
Slack 활용:
- 예정에 없던 갑작스러운 증설 필요 시
- 슬랙봇을 이용해서 '증설 카테고리: (V)Very High' 입력
- 바로 증설 실행
4단계: 위험 대응


앞의 3단계를 완료했다고 완벽한 것은 아닙니다. 위험은 항상 존재하며, 이에 대응하는 자세가 필요합니다.
저희가 모든 이벤트를 예측할 수는 없습니다. 갑자기 트래픽이 폭증하는 경우도 있습니다. 따라서 얼마나 빠르고 기민하게 대응할 수 있는가가 핵심입니다.
위험성을 감지하는 방법은 앞서 강조한 체계적인 모니터링과 직결됩니다. 위험이 감지되었을 때 신속한 증설이 가능해야 합니다.
🎯 대응 원칙 장애를 겪는 것보다는 과잉 대응으로 장애를 예방하는 것이 더 나은 선택입니다.
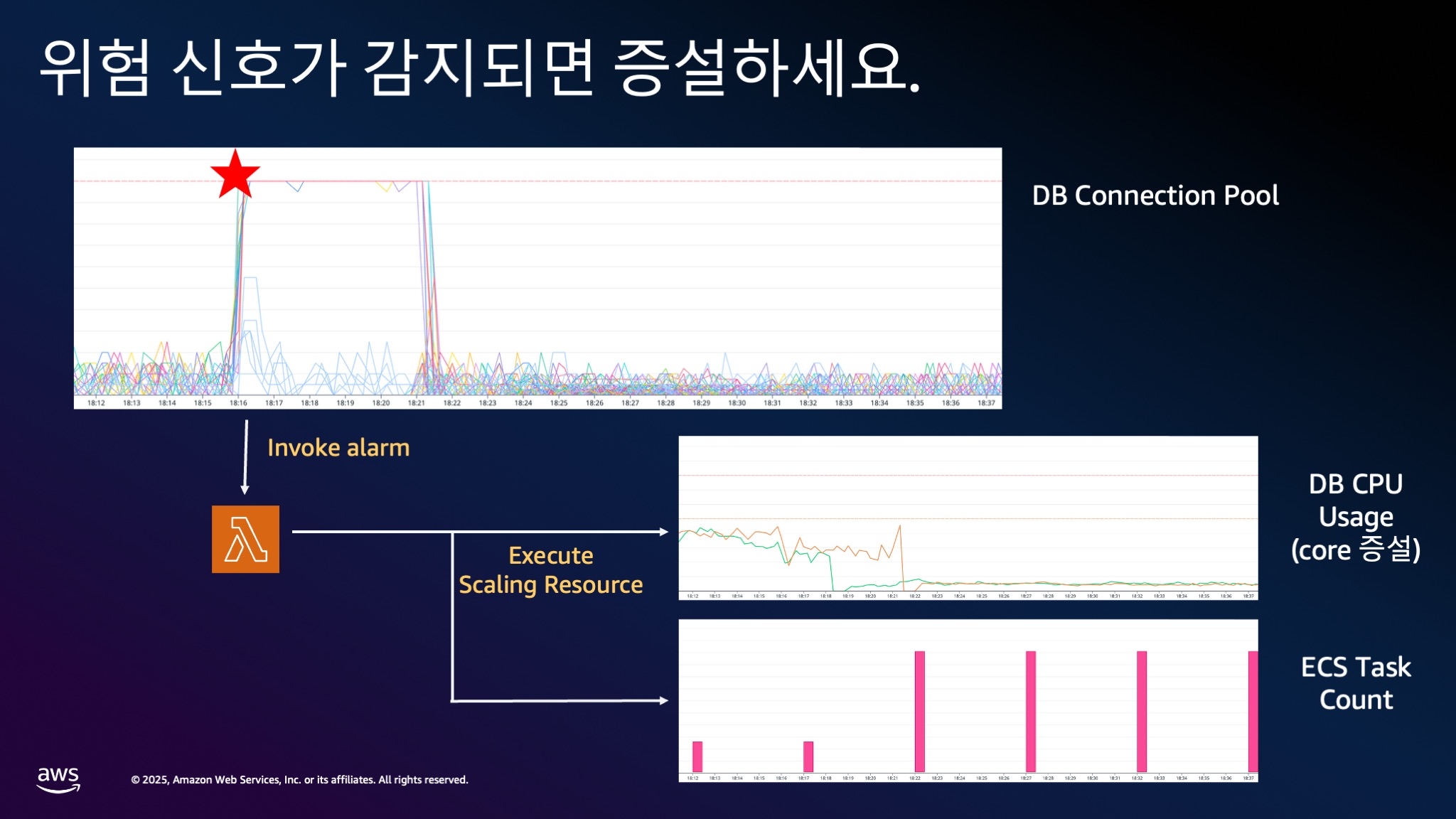
위험이 감지되면 빠르게 대응해야 합니다. 장애 발생 후 대응보다 장애 예방이 우선입니다.
예를 들어, DB 커넥션 풀이 갑자기 증가하면 즉시 모든 가용 자원을 투입하여 증설합니다. 이는 이러한 상황이 90% 이상의 확률로 장애로 이어지기 때문입니다.
증설 후에 상황이 안정되면 다시 감축할 수 있습니다.
구현의 단순함
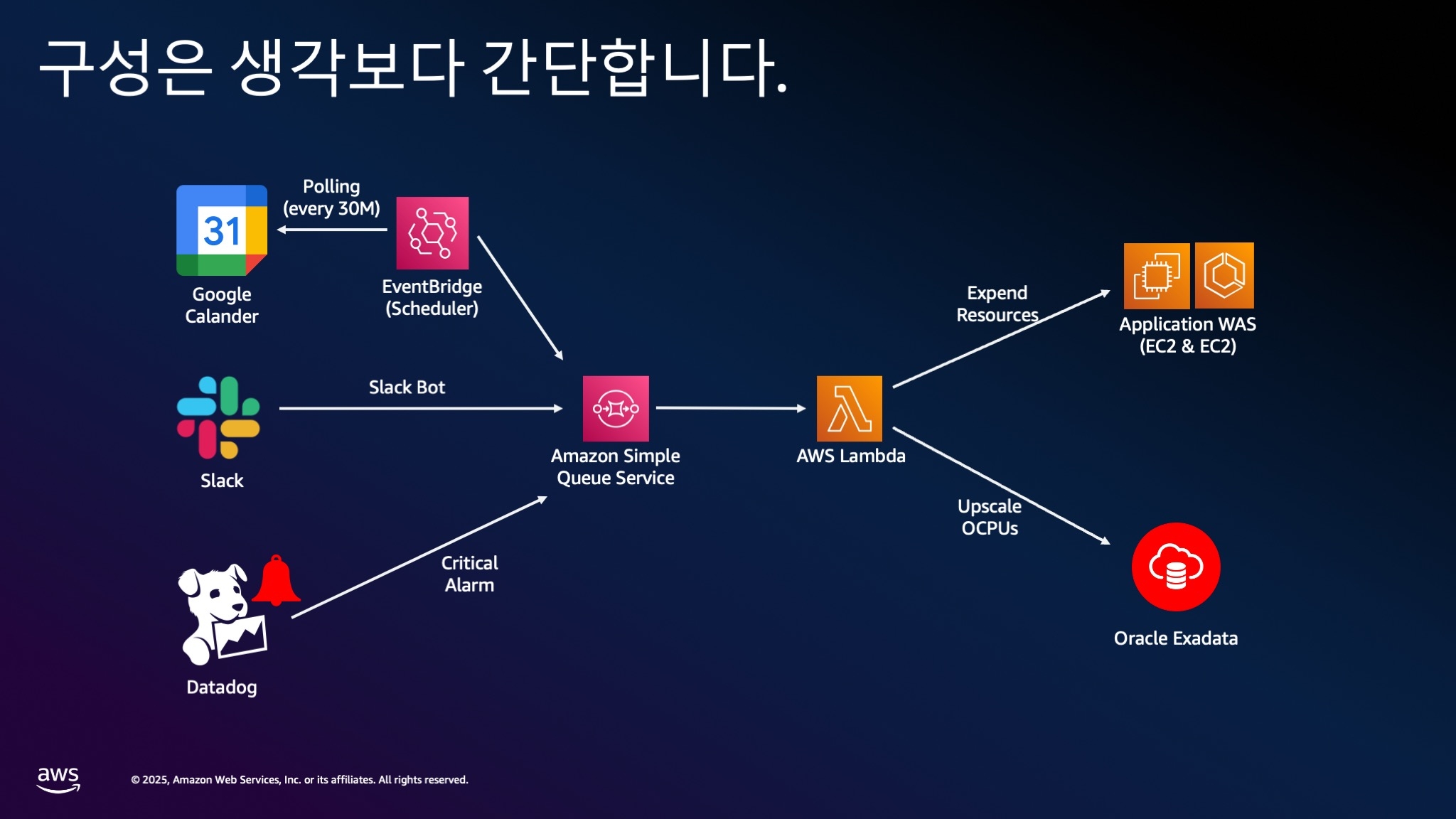
사실 이 전체 시스템 구성은 매우 단순합니다.
구현 복잡도:
- 개발 기간: 2-3일 정도
- 기술 스택: AWS Lambda, SQS, 기존 Chat/Calendar API
- 핵심: 여러분이 이미 가지고 있는 경험 활용
캘린더나 슬랙에서 이벤트를 받아 SQS 같은 큐에 넣고, Lambda 함수가 이를 처리해서 스케줄링하는 구조입니다.
하지만 앞서 설명한 전략적 사고과정이 기술적 구현보다 훨씬 중요합니다. 어떻게 트래픽을 분류하고, 무엇을 모니터링하며, 어떤 기준으로 증설할지 정하는 것이 핵심입니다.
SRE의 핵심 원칙

SRE에는 업무를 지탱하는 몇 가지 기본 원칙들이 있습니다.
SRE의 3대 핵심 영역:
- 가용성(Availability)
- 장애 대응(Incident Response)
- 관찰 가능성(Observability)
그중에서도 가용성을 높이려면 '관찰'을 잘해야 한다고 생각합니다. 앞서 데이터 기반 의사결정의 중요성을 강조한 것과 같은 맥락입니다.
🔍 핵심 인사이트 관찰하지 못하면 가용성을 확보할 수 없습니다. 적절한 관찰은 우리에게 더 높은 가용성을 보장해 줍니다.
옵저버빌리티(Observability)가 확보되어야 자동화도 제대로 할 수 있습니다.
비즈니스 중심 모니터링(BOM)

'관찰을 하자'고 하면 CPU와 메모리만 보는 경우가 많습니다.
'CPU랑 메모리만 잘 보면 되는 거 아니야?'라고 생각하시기보다, 한 걸음 더 나아가는 것을 권장합니다. 단순히 시스템 지표만 보는 것이 아니라, 우리 비즈니스가 운영 시스템에 어떤 영향을 미치는지 함께 살펴보는 것이 중요합니다.
비즈니스 지표는 우리 시스템이 앞으로 어떻게 나아가야 할지 알려주는 나침반과 같은 역할을 합니다.

이러한 접근법을 "비즈니스 오리엔티드 모니터링(Business Oriented Monitoring, BOM)"이라고 부릅니다.
BOM + Automation = 안정적인 시스템
여러분들이 더 좋고 안정적인 시스템을 구축하는 데 이러한 접근법을 활용하시기를 추천합니다.
오늘부터 시작할 수 있는 3가지
- 트래픽 카테고리 정의: 우리 서비스의 5단계 트래픽 레벨 설정
- 핵심 지표 선정: 주요 KPI 기반 모니터링 지표 정의
- 간단한 자동화: Slack/Calendar 연동 스케일링 봇 구축
참고 자료
- 올리브영 DASH 2024 발표자료 - 비즈니스 대시보드 구성 사례
- SRE 기본 원칙 가이드 - Site Reliability Engineering의 핵심 개념
- Amazon Q Developer CLI 가이드 - AI 기반 개발 도구 활용법
📝 이 포스트는 Amazon Q Developer CLI를 활용해 작성되었으며, Claude 4를 통한 리뷰로 마무리했습니다.