

시작하며
안녕하세요, 올리브영의 상품 데이터를 다루고 있는 국밥빌런🍲입니다.
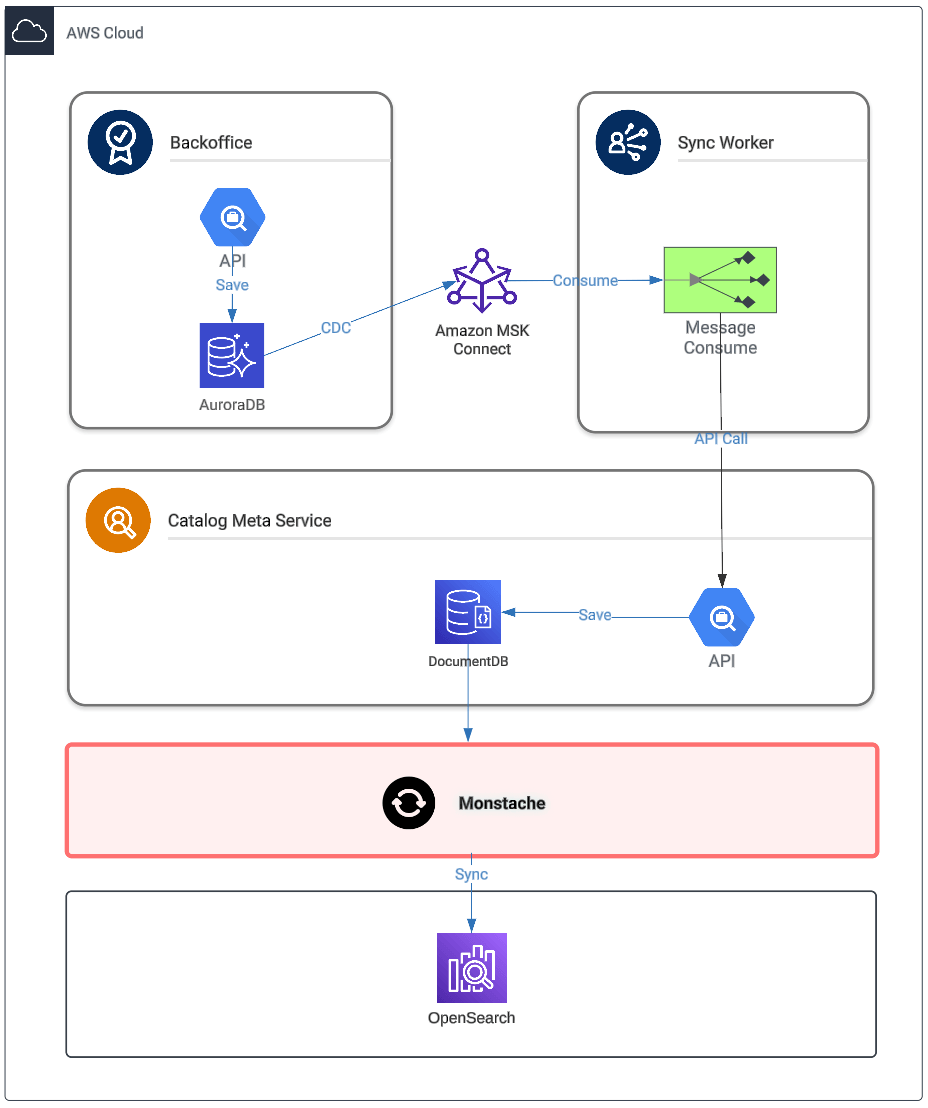
현재 올리브영의 상품 데이터를 생성하기 위해서는 오프라인 매장과 온라인몰로 관리하는 상품 데이터를 각기 다른 시스템을 통해 등록하고 연동하게 되어있어요.
저는 이렇게 관리 영역별로 분산되어 있는 상품 시스템을 하나로 통합하는 업무를 진행하고 있는데, 이를 통해 오프라인 매장이나 온라인몰 상품 데이터를 한 곳에서 관리할 수 있게 돕고 이 데이터들을 필요한 영역에 제공하려고 하고 있어요.🎯
상품 데이터를 제공 받는 곳에서는 어떤 종류의 데이터를 원할까요? 온라인몰 상품상세에서 필요한 상품 정보 중에는 상품명, 상품이미지, 브랜드, 가격, 재고, 할인 정보와 같은 정보가 있을 거예요. 사실 상품 데이터는 이 외에도 판매 채널, 매입가, 배송 정책, 패키지 규격, 담당자, 안전인증정보 등 많은 정보들로 구성되어 있어요.🧐
이렇게 다양한 상품 데이터를 받게되는 주체, 시기, 환경에 따라 데이터를 조합해서 필요한 곳에 제공하면 좋겠지만 그렇게 간단한 일이 아니었어요.🥺 다른 데이터도 추가해서 제공해야하거나 데이터가 필요하지 않는 경우 거기에 맞춰 지속적으로 요청과 응답형식을 고쳐야하는 불안한 미래가 그려졌어요.😵
이런 고민을 줄이기 위해 특정 상품에 대한 모든 정보를 한 번에 볼 수 있도록 역정규화된 상품 데이터를 AWS DocumentDB에 적재하여 제공하기로 했어요.
문제는 상품 데이터를 대량으로 조회할 때 발생했는데, 부하테스트를 진행했을 때 필요한 TPS에 미치지 못해 대안으로 DocumentDB에 있는 데이터를 OpenSearch로 동기화하여 대량 데이터 조회를 제공하는 방향을 잡게 되었어요.
안타깝게도 이 동기화에 힘을 쏟을 수 있는 인원은 저 혼자였고😱, 저는 아주 흔한 바쁜 올리브영 개발자 중에 한 명이기 때문에 이런 역할을 수행하는 오픈소스를 찾다가 Monstache를 발견했어요!🕵️♂️
Monstache는 실시간 데이터 동기화, 필터링, OpenSearch 호환성, 웹서버 기능까지 갖춘 솔루션으로, 제가 필요로 하는 조건에 적합했어요. 이를 기반으로 POC(Proof of Concept)를 진행하며 시행착오 끝에 성공적으로 데이터를 동기화할 수 있었고, 이 경험을 공유해보려고 합니다.😊
Monstache란? 🤖
Monstache는 MongoDB(또는 DocumentDB) 데이터를 Elasticsearch(또는 OpenSearch)로 실시간 동기화하는 Go 언어 기반의 오픈소스 프로그램이에요. MongoDB의 oplog를 감지해서 변경된 데이터를 자동으로 OpenSearch로 보내줘요.
주요 기능
✅ 실시간 데이터 동기화: DocumentDB에서 변경된 데이터를 OpenSearch에 자동 반영 ⚡
✅ 필터링 및 변환 지원: 정규식을 통한 특정 컬렉션 데이터만 동기화 가능 🎯
✅ 스크립팅 지원: Go 플러그인이나 JavaScript로 커스텀 로직 적용 가능 🛠️
✅ 웹서버 기능 제공: --enable-http-server 옵션으로 동기화 상태 확인 가능 🌐
저는 요 녀석의 동기화라는 기본적인 기능 뿐만 아니라 동기화 상태확인이 가능한 점도 필요했기 때문에 가려운 곳을 시원하게 긁어줄 수 있을 거라 판단하고 채택하게 되었어요 🛍️
Monstache 실행 방법 🏃♂️
1. Monstache 다운로드 및 실행
git clone https://github.com/rwynn/monstache.git
cd monstache
git checkout <branch-or-tag-to-build>
brew install go # Go가 설치되지 않았다면 실행
go install
cd $GOPATH/bin
./monstache -f config.toml2. 설정 파일을 이용한 실행
Monstache는 config.toml 설정 파일로 DocumentDB 및 OpenSearch 연결 정보, 동기화할 데이터 범위 등의 설정을 정의할 수 있어요.
./monstache -f config.toml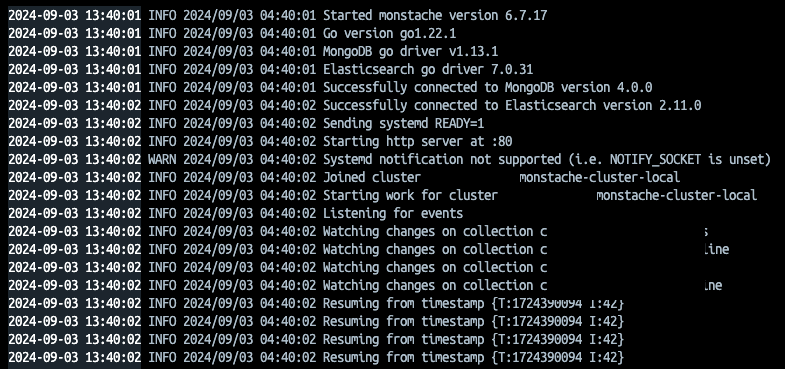
또한 웹서버 기능을 활성화하면 동기화 상태를 확인할 수도 있어요.
./monstache -f config.toml --enable-http-server
Monstache 설정 및 최적화 ⚙️
# MongoDB 연결 정보
mongo-url = "mongodb://{username}:{password}@your-docdb-url:27017/?authSource=admin&replicaSet=rs0&ssl=true&sslcertificateauthorityfile=ca.pem&readPreference=primary&retryWrites=false"
# OpenSearch 연결 정보
elasticsearch-urls = ["https://your-opensearch-url"]
elasticsearch-user = "{username}"
elasticsearch-password = "{password}"
# 변경점 감지 설정
change-stream-namespaces = ["your-database.your-collection-1", "your-database.your-collection-2"]
# OpenSearch 요청 압축
gzip = true
# Oplog 타임스탬프 인덱싱
index-oplog-time = true
# AWS 연결 설정
[aws-connect]
strategy = 4AWS 자격 증명 설정 변경 🛠️
처음 POC 단계에서는 AWS 자원에 접근하기 위해 strategy = 0으로 설정하고, access/secret key를 사용했어요. 하지만 보안🔒 문제가 발생할 수 있어서, 운영 환경에서는 EC2 IAM Role을 활용하는 방식으로 변경했어요. 🎯 IAM Role을 사용하면 보안에 민감한 값을 직접 관리하지 않아 더 안전하고 편리해요.
aws-connect.strategy = 4로 설정하면, access/secret key, 환경변수, IAM Role을 차례로 참조하면서 적절한 인증 방식을 선택하게 돼요.🔑
시행착오 1: elasticsearch-healthcheck-timeout 문제 ⏳
처음 Monstache를 실행했을 때, OpenSearch와 연결이 안 되더라고요. 🤔
문제 상황
cannot connect to Elasticsearch: health check timeout: no response첫 구동을 시도했을 때 위와 같은 로그가 발생해버렸어요. elasticsearch-healthcheck-timeout 기본값이 5초인데, OpenSearch가 응답하기에는 너무 짧았던 거예요. 🤦♂️
해결 방법
elasticsearch-healthcheck-timeout = 200이렇게 타임아웃 시간을 넉넉하게 설정하고 나니까 연결이 잘 됐어요! 🎉
이 설정은 특히 네트워크가 불안정하거나 OpenSearch가 높은 부하를 받을 때 유용해요. 만약 여전히 문제가 발생한다면, 값을 더 늘려 보거나 OpenSearch 상태를 확인하는 것도 방법이에요. 📡
시행착오 2: DocumentDB 변경 스트림 활성화 🔄
DocumentDB에서는 변경 스트림 기능이 기본적으로 비활성화되어 있어요. 그래서 활성화 과정이 필요해요. 또한, readPreference=primary 옵션을 포함한 DocumentDB 커넥션 URI를 사용해야 해요. 이 부분은 Monstache 가이드 문서에서도 다루고 있으니 참고하면 좋아요! 📖
변경 스트림 활성화 방법
1️⃣ DocumentDB에서 변경 스트림을 활성화
2️⃣ readPreference=primary가 포함된 URI를 사용하여 연결 설정
3️⃣ change-stream-namespaces 옵션을 활용하여 변경 스트림이 활성화된 컬렉션 동기화
이렇게 설정하면 변경 사항을 실시간으로 감지해서 변경된 데이터를 OpenSearch에 빠르게 반영할 수 있어요! 🚀
마무리 🏆
이외 자잘한 시행착오도 많았지만 저희 팀과 엔지니어링 팀의 도움이 컸어요. 덕분에 DocumentDB에서 OpenSearch로의 데이터 동기화에 성공할 수 있었습니다! 🎉 Monstatche를 안정적으로 구동한 후에는 거의 신경쓰지 않아도 괜찮을 만큼 동기화 시스템을 안정적으로 운용하게 되었어요.
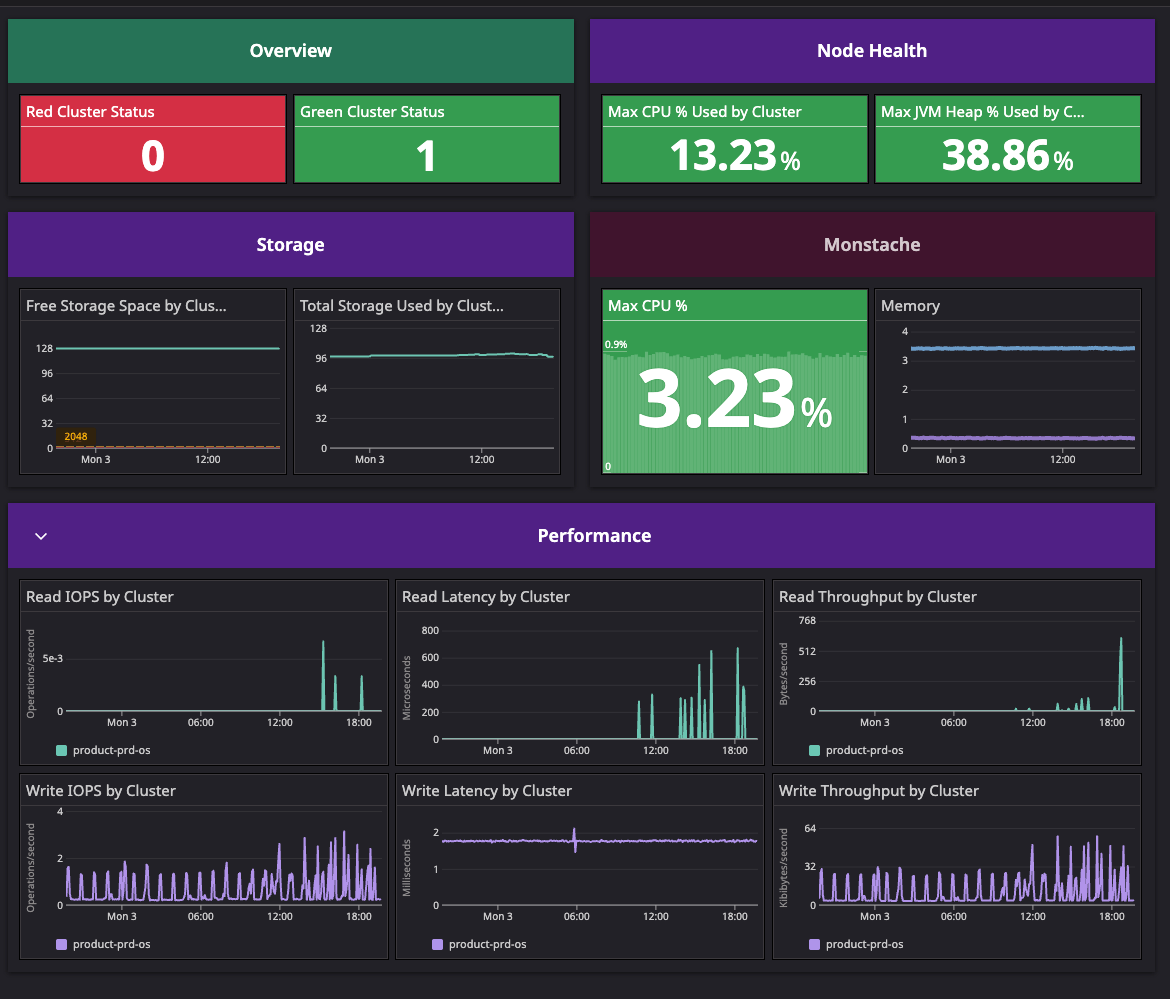
지금은 에러로그 감지 및 헬스체크를 위한 Datadog 모니터, 대시보드를 만들어 상태를 확인하고 있어요.📊

저처럼 AWS 서비스를 주로 활용하면서 동기화만 잘 하면 된다👌 하는 분들은 OpenSearch Ingestion Pipeline을 활용한 방법을 참고하시는걸 추천해요.😌 이 포스트가 저와 비슷한 고민이 있는 분들께 도움이 되면 좋겠어요. 😊
