👉 들어가기에 앞서
안녕하세요!
올리브영에서 상품 도메인을 책임지고 있는 윤긱스입니다. 혹시 지금.. 이런 고민을 하고 계신가요?
- 🙋 : MongoDB 트랜잭션을 도입하고 싶지만 어렵고 막막해요!
- 🙋♀️ : 도입은 했는데, 이게 진짜 잘 돌아가는건지 모르겠어요!
그렇다면 걱정하지 마세요.
여기 'MongoDB 트랜잭션 생존 가이드'에서 올리브영에서 겪은 경험을 통한 실전 꿀팁을 아낌없이 대방출합니다. Replica Set부터 Oplog 동작 원리까지, 운영 중에 발생할 수 있는 상황을 헤쳐 나갈 실전 가이드! 시작해 보겠습니다!
👉 MongoDB 트랜잭션의 주요 특징
1) 트랜잭션을 지원하는 MongoDB 버전
| MongoDB Engine Version | Spring 관련 모듈 version | |
|---|---|---|
| Single-Document | MongoDB 4.0 이전 | Spring Data MongoDB의 모든 버전 |
| Multi-Document |
Replica Set: MongoDB 4.0 이상 Sharded Cluster: MongoDB 4.2 이상 |
Spring Data MongoDB 2.1.x 이상 |
2) 트랜잭션이 동작하려면?
MongoDB 트랜잭션은 모든 MongoDB에서 통하는 것은 아닙니다!
- Replica Set 또는 Sharded Cluster 환경에서만 가능
- WiredTiger 스토리지 엔진이어야만 작동
❓여기서 잠깐! 왜 Replica Set이나 Sharded Cluster에서만 트랜잭션이 가능할까?
1. 복제 없이 데이터 무결성 보장 불가
- Standalone MongoDB는 노드가 하나이기 때문에 장애 시 복구 불가
- 복제 기능이 없으니 트랜잭션도 불필요
2. 트랜잭션 = Primary 노드 + Secondary 노드 동기화
- 트랜잭션 중에는 Primary 노드에서 데이터를 쓰고, Secondary 노드로 Oplog를 통해 복제
- 이렇게 동기화해야 데이터의 스냅샷 상태를 보장할 수 있습니다.
3. Standalone MongoDB의 경우, oplog 불필요
- 복제본이 없으니 당연히 oplog 불필요 → 트랜잭션 기능 미지원
cf) RDB는 트랜잭션 로그(WAL)와락(lock) 메커니즘으로 데이터 무결성과 일관성 보장 → MongoDB는 이런 방식 대신 Replica Set을 기반으로 동작
👉 MongoDB 트랜잭션 동작 방식
1) MongoDB의 격리 수준(Isolation)은 어떻게 될까요?
MongoDB는 기본적으로 Read Committed를 사용합니다.
즉, 다른 트랜잭션이 완료한 데이터는 읽을 수 있습니다.
MongoDB에는 또 하나의 비장의 무기 'Snapshot Isolation'이 있습니다.
이 방식은 트랜잭션 진행 중 데이터가 외부에서 변경되지 않도록 보장합니다.
2) Snapshot Isolation, 어떻게 작동할까요?
트랜잭션 시작 시: 데이터베이스가 해당 트랜잭션만을 위한 스냅샷을 찍습니다.이제 트랜잭션 내에서는 이 스냅샷을 기준으로 데이터가 반환됩니다. 트랜잭션이 동시에 진행될 때: 다른 트랜잭션이 데이터를 막 변경해도,내 트랜잭션은 처음 찍은 스냅샷 데이터만 봅니다. 즉, 다른 트랜잭션의 변경 내용은 모른 척한다는 뜻!
3) Snapshot Isolation의 장점과 단점은?
| 항목 | 장점 | 단점 |
|---|---|---|
| 일관성 | 데이터 일관성 보장 | Write Conflict 발생 가능 |
| 동시성 | 높은 동시성 지원 | 여러 트랜잭션 충돌 가능 |
| 읽기 작업 | 읽기 작업 시 항상 일관된 데이터 제공 | 충돌 방지 로직 필요 |
| 안정성 | 다른 트랜잭션으로 인한 데이터 꼬임 방지 | 트랜잭션 실패 시 재시도 필요 |
💥 여기서 잠깐! Write Conflict 시나리오
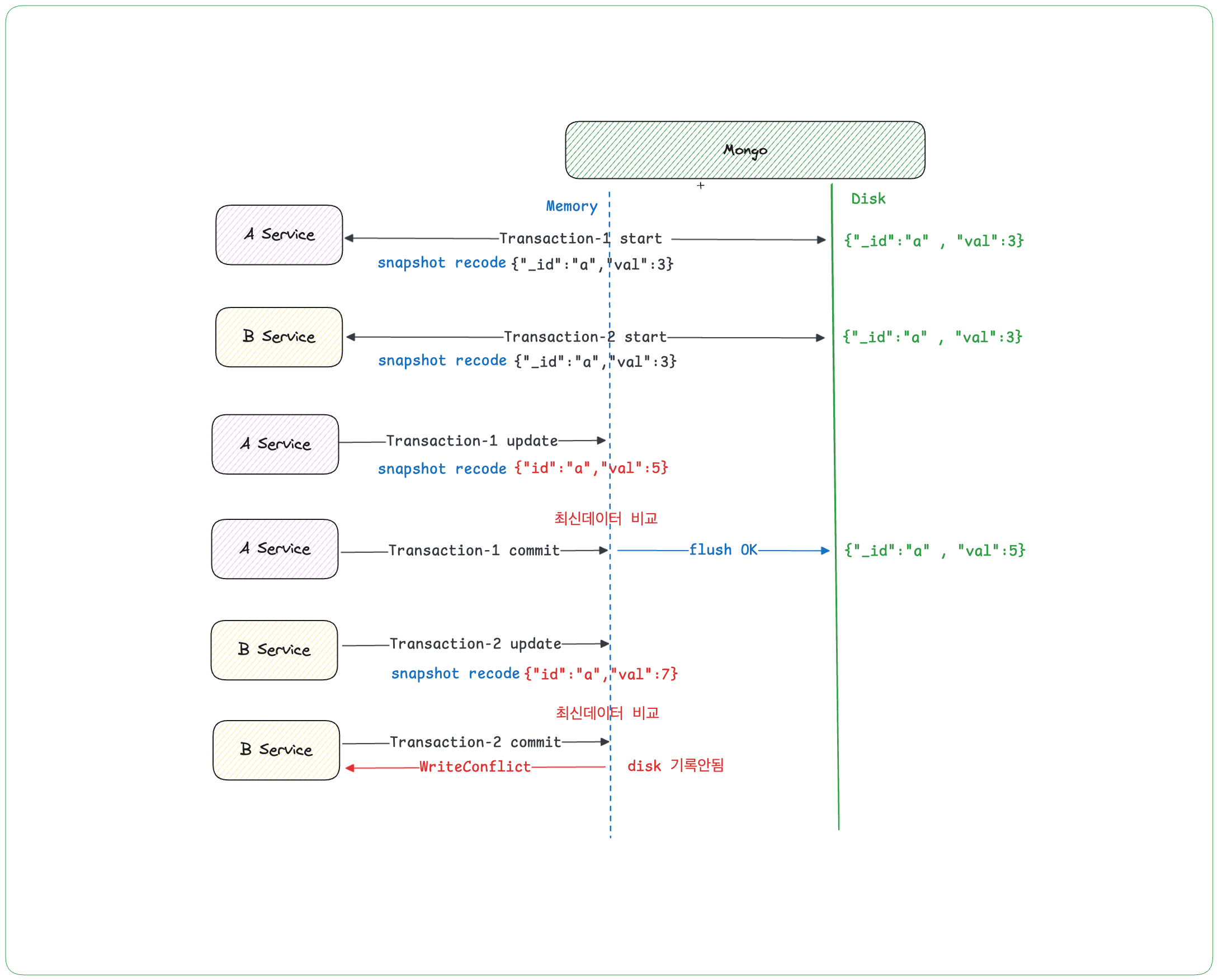
- { "val": 3 } 값을 조회함과 동시에 데이터의 스냅샷을 기록하고 작업을 시작합니다. (이 데이터는 메모리에 저장됩니다)
2. Transaction-2 Start
- Transaction-1 이 시작된 시점의 동일한 데이터를 읽고 작업에 들어갑니다. (아직 Transaction-1의 변경사항은 모르는 상태입니다.)
3. Transaction-1 Update & Commit
- Transaction-1이 작업을 끝내고 { "val": 5 } 메모리에 반영하고 데이터를 디스크에 반영합니다. 이제 데이터베이스에 새로운 값이 반영되었습니다.
4. Transaction-2 Update & Commit
- Transaction-2가 데이터를 { "val": 7 } 수정하려는데...?
5. Write Conflict 발생!!!
- 디스크 데이터는 { "val": 5 } 유지
이유는 간단합니다. Transaction-2는 이전 { "val": 3 } 데이터를 기준으로 작업 중이었으니까요. MongoDB는 해당 격리수준으로 Transaction 을 관리하고 있습니다.
👉 Spring Boot MongoDB 트랜잭션 설정 요소
코드부터 보시죠! MongoClient에서 트랜잭션을 설정하는 간단한 예제입니다.
@Configuration
class MongoConfig {
@Bean
fun mongoClient(): MongoClient {
val mongoClientSettings = MongoClientSettings.builder()
.applyConnectionString("mongodb://localhost:27017") // MongoDB 서버 URL 설정
.writeConcern(WriteConcern.ACKNOWLEDGED) // WriteConcern 기본 설정 옵션
.readPreference(ReadPreference.secondaryPreferred()) // ReadPreference Replica시 많이 설정하는 옵션
.build()
return MongoClients.create(mongoClientSettings)
}
}1) Write Concern 설정
Write Concern은 간단히 말하면, 데이터가 "잘 저장되었는지" 확인하는 장치입니다.
이 설정 덕분에, 데이터의 내구성과 일관성을 보장할 수 있습니다. 아래 표처럼 Write Concern은 여러 옵션이 있습니다.
| Write Concern | 설명 | 특징 |
|---|---|---|
| ACKNOWLEDGED | 기본값은 최소 1개의 노드에서 응답을 받을 때 성공으로 간주됩니다. | 빠른 응답 속도를 제공하고 널리 사용되지만, 데이터 일관성이 낮을 수 있습니다. |
| MAJORITY | 복제본 세트의 과반수 노드에 데이터 기록이 완료되면 성공으로 간주됩니다. | 높은 데이터 일관성을 보장하며, 과반수에서 기록이 완료되지만 성능이 저하될 가능성이 있습니다. |
| UNACKNOWLEDGED | 응답을 받지 않고 작업이 성공으로 간주됩니다. | 매우 빠른 응답을 제공하며 성능 최적화가 가능하지만, 데이터 손실 가능성이 있습니다. |
| W1 | 최소 1개의 노드에서 성공하면 작업이 성공으로 간주됩니다. | 빠른 성능을 제공하며 최소 1개 노드에서 성공 시 완료되지만, 데이터 일관성이 부족할 수 있습니다. |
| W2 | 2개의 노드에서 성공적으로 기록될 때 작업이 성공으로 간주됩니다. | 높은 데이터 일관성을 보장하며, 2개 노드에서 기록이 보장되지만 성능 저하가 있을 수 있습니다. |
| FSYNCED | 디스크에 기록된 후 작업이 성공으로 간주됩니다. | 높은 내구성을 보장하며, 디스크 동기화 후 기록이 보장되지만 성능 저하가 심할 수 있습니다. |
| JOURNALED | 복구 로그에 기록된 후 작업이 성공으로 간주됩니다. | 장애 시 복구가 가능하며 안전한 기록을 보장하지만, 성능 저하가 있을 수 있습니다. |
⚠️ 참고 Write Concern 설정은 복제본 세트 환경에서만 의미가 있습니다! Standalone 환경에서는 무시되기 때문에, 이 점을 반드시 기억하세요! 만약, 복제본 세트에서 운영 중이라면 이 설정을 적극 활용하고, Standalone 환경에서는 그 효과를 기대하기 어려운 점을 유의해야 합니다.
2) Read Preference 설정
복제본 세트를 사용하는 환경에서 중요한 역할을 하며, 데이터를 읽는 시점과 일관성을 어떻게 처리할지를 정할 수 있습니다. 아래 표에서 각 옵션의 특성과 장단점을 확인해 보세요!
| Read Preference | 설명 | 특징 |
|---|---|---|
| PRIMARY | 기본 설정. 쓰기 작업이 이루어지는 주요 노드에서 읽습니다. | 가장 신뢰할 수 있는 데이터를 읽을 수 있어 데이터 일관성이 보장됩니다. 읽기 성능은 떨어질 수 있습니다. |
| SECONDARY | 복제본 노드에서 읽습니다. 데이터 일관성보다는 읽기 성능을 우선시 합니다. | 읽기 작업을 복제본에서 처리하여 부하를 분산시킬 수 있습니다. 최신 데이터가 아닐 수 있습니다. |
| PRIMARY_PREFERRED | PRIMARY에서 읽습니다. PRIMARY가 사용 불가하면 SECONDARY에서 읽습니다. | PRIMARY 노드를 우선으로 사용하여 높은 가용성을 보장합니다. SECONDARY에서 읽을 때 최신 데이터가 아닐 수 있습니다. |
| SECONDARY_PREFERRED | SECONDARY에서 읽습니다. 읽을 수 없으면 PRIMARY에서 읽습니다. | 복제본에서 읽을 수 있으면 성능이 향상됩니다. PRIMARY에서 읽을 때보다 부하가 분산됩니다. PRIMARY에서 읽을 때 일관성 보장 가능성은 낮을 수 있습니다. |
| NEAREST | 여러 복제 노드 중 네트워크 지연시간이 가장 적은 노드를 선택하여 데이터를 읽습니다. | 네트워크 대기시간을 줄여 빠른 응답 시간을 제공합니다. 분산 환경에서 유용합니다. 읽은 데이터가 최신이 아닐 수 있습니다. |
3) transactionManager 설정 (필수!)
트랜잭션을 제대로 사용하려면 MongoTransactionManager를 @Bean 으로 등록해야 합니다. 그래야 @Transactional 어노테이션을 사용할 때 트랜잭션 처리가 제대로 동작합니다.
⚠️ 참고 Spring Boot 에서는 RDBMS의 트랜잭션 매니저를 자동으로 @Bean 으로 등록해 주죠. (예: spring-boot-starter-data-jpa가 자동 설정)
👉 Spring Boot 트랜잭션 + Replica 설정 시, 이슈와 그 해결책
이제, 우리가 사용한 설정들에 대해 소개합니다. 이 설정들이 어떤 문제를 일으킬 수 있는지, 그리고 어떻게 개선하면 더 효율적으로 사용할 수 있을지 알아보겠습니다.
- writeConcern(WriteConcern.ACKNOWLEDGED): 이 설정, 과연 완벽할까요?
- readPreference(ReadPreference.secondaryPreferred()): 이 설정은 장점이 많지만, 몇 가지 문제를 야기할 수 있습니다. 사용 시 주의가 필요합니다!"
이제, 위 설정들이 실제 운영시 서비스에 어떻게 영향을 미치는지 아래 예시를 통해 살펴보도록 하겠습니다.
@Service
class RequestAddServiceImpl(
//생략
): RequestAddService {
@Transactional("mongoTransactionManager")
override fun addRequest(requestDto: RequestDto): ResponseDto {
// Dto to Entity & domain Logic Setting
val request = dtoConverter.convertToAddRequest(requestDto)
// Goods 도메인 등록정보 Save
goodsAddService.add(request)
// 결재를 상신한다 (상품정보를 재 조회하는 로직 존재)
goodsApprovalService.submit(request.id)
//Event Send (SQS Publish)
eventSender.send(request)
return ResponseDto.create(id = request.id)
}
}
@Component
class EventSenderImpl(
private val amazonSQS: AmazonSQS,
) : EventSender {
override fun send(message: RequestDto) {
val sendMessageDto = SendMessageRequest()
.withMessageBody(objectMapper.writeValueAsString(message))
amazonSQS.sendMessage(sendMessageDto)
}
}1) Primary와 Secondary 간 Lag로 인한 비일관성 문제!!
Replica Set이나 Sharded Cluster 환경에서는 Write Concern과 Read Preference 설정이 큰 영향을 미칩니다.
아래 그림은 WriteConcern.ACKNOWLEDGED와 ReadPreference.secondaryPreferred 설정이 데이터 조회에 어떤 방식으로 영향을 미치는지 보여줍니다.
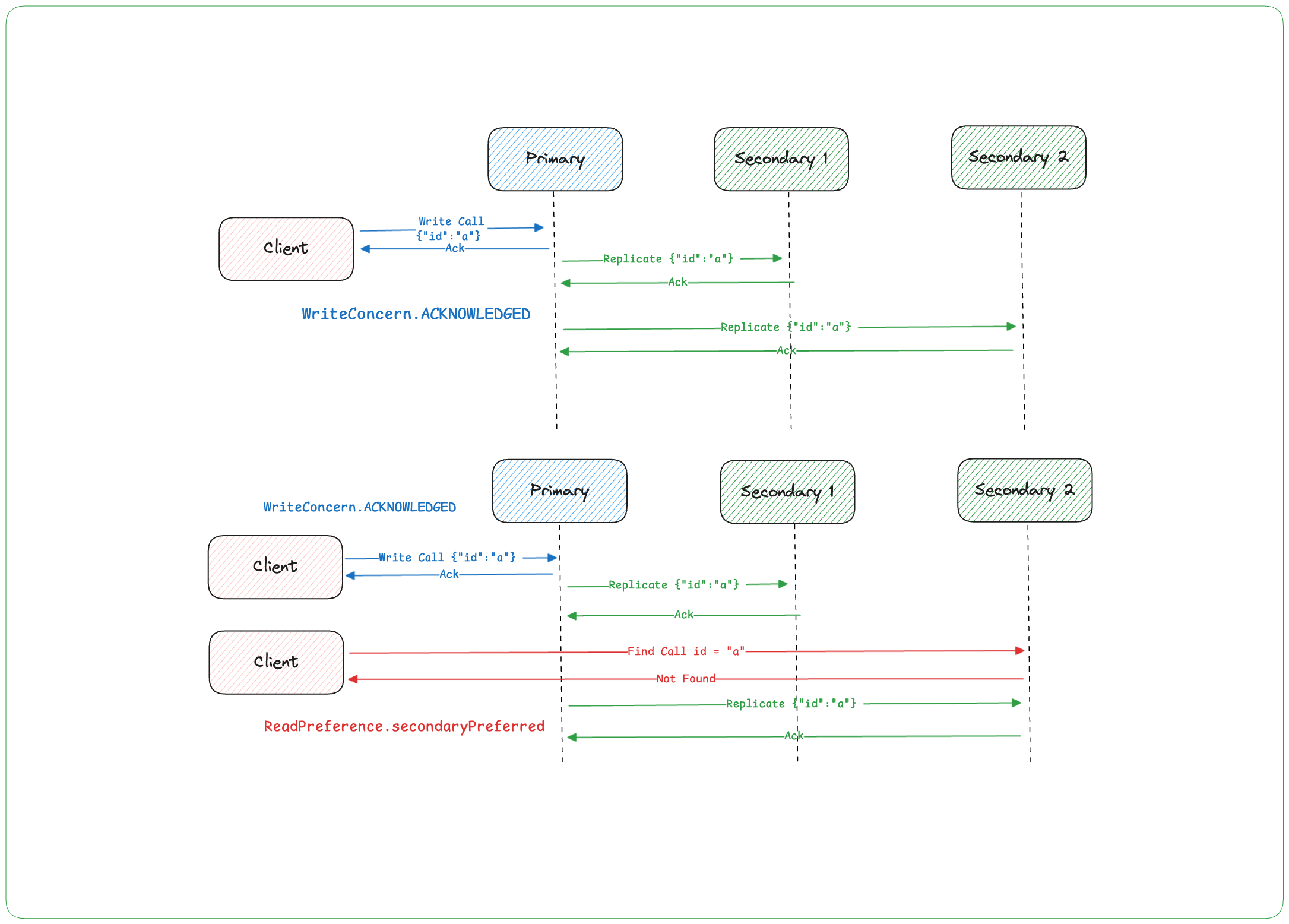
⚠️ 중요! 결국, PRIMARY와 SECONDARY 간의 복제 지연 때문에, SECONDARY에서 데이터를 찾지 못하게 되는 문제입니다. 마치SECONDARY가 아직 데이터를 못 받아서 "그거 아직 없어요!"라고 말하는 상황입니다.
Q. 무엇이 문제였을까요?
위 코드와 그림에서 드러난 주요 문제는 WriteConcern 설정은 기본값인 ACKNOWLEDGED를 사용해 빠른 응답을 유지하려 하면서도, Read Preference가 secondaryPreferred로 설정되어 있다는 점입니다. 이로 인해 PRIMARY와 SECONDARY 간 복제가 완료되지 않은 상황에서 데이터를 읽으려 하면 문제가 발생할 수 있습니다. 예를 들어, id = a라는 정보를 다시 조회하려 할 때 기대한 결과를 얻지 못할 가능성이 있는 것이죠. 즉, SECONDARY 노드에서 복제 지연이 발생하면 데이터를 찾지 못하고, 결국 Not Found Exception이 발생하는 상황으로 이어질 수 있습니다. 그렇다면, 위 그림의 문제를 실제 예제에 대입해 살펴보겠습니다.
How? 이 상황, 어떻게 해결할 수 있을까요?
1. MongoClient WriteConcern 옵션을 변경하여 정확도를 높여 조정한다면?
- WriteConcern을 MAJORITY로 설정하면, Secondary의 과반수 이상에 데이터가 저장된 후에 다음 프로세스가 진행됩니다.
- 이 방법은 정확성을 높일 수 있지만, 모든 요청에 대해 Secondary 과반수 ACK 응답을 기다리면 큰 오버헤드를 발생시킬 수 있습니다.
- "정확하게 하자!"는 의도가, 성능을 떨어뜨릴 위험이 있다는 점을 고려해야 합니다.
2. MongoClient Read Preference 옵션을 PRIMARY 로 설정한다면?
- ReadPreference를 PRIMARY로 설정하여, 모든 읽기 트래픽을 PRIMARY에 집중 시킬 수 있습니다.
- 하지만, 이 경우 SECONDARY 노드가 유휴 상태로 남아 리소스를 낭비할 수 있습니다.
- SECONDARY 노드가 자꾸 놀고 있는 상황을 피하고 싶다면, PRIMARY만을 우선하는 설정은 완벽한 해결책이 되지 않겠죠?
Solution 우리의 해결책, 이렇게 정리했습니다!
@Bean(name = ["mongoTransactionManager"])
fun transactionManager(dbFactory: MongoDatabaseFactory): MongoTransactionManager {
val transactionOptions = TransactionOptions.builder()
// 트랜잭션이 선언되어 있다면, PRIMARY에서 읽어야 합니다!
.readPreference(ReadPreference.primary())
.build()
return MongoTransactionManager(dbFactory, transactionOptions)
}트랜잭션 상황에서만 특별히 PRIMARY를 고집하기로 했습니다. 그 이유는 아래 두 가지로 딱 정리할 수 있습니다.
🎯 이유 1. 데이터 일관성, 놓칠 수 없죠! (데이터 일관성 보장)
- 트랜잭션에서는 가장 최신 데이터가 필요합니다.
- PRIMARY는 항상 실시간 데이터를 보장하니, 당연히 트랜잭션 중엔 믿고 사용할 수 있겠죠?
🎯 이유 2. 트랜잭션은 쓰기 중심이라서요! (트랜잭션 사용의 특수성)
- 트랜잭션은 보통 쓰기 작업과 쌍으로 움직입니다.
- PRIMARY에서만 쓰기가 가능하니, 읽기와 쓰기를 한 곳에서 처리하는 게 훨씬 자연스럽습니다.
- 이렇게 하면 데이터 정합성도 더 깔끔하게 유지됩니다.
⚠️ 결론 성능을 고려하면서 여러 DB에서 일관성(Consistency)을 요구하고자 할 때, 트랜잭션에만 옵션을 추가해보시는 건 어떨까요?
2) Event 발행시 비일관성 문제 발생!
이벤트 발행, 타이밍이 생명입니다! 특히 eventSender.send(request)처럼 MongoDB에 데이터를 저장하면서 SQS로 메시지를 발행하는 과정에서는 순간의 어긋남이 치명적일 수 있습니다. 코드로 문제의 원인을 파악해 볼까요?
Q. 무엇이 문제였을까요?
goodsAddService.add(request)를 통해 데이터를 MongoDB에 저장한 후, 아래 코드에서 GoodsEventSender가 데이터를 SQS로 메시지를 발행하는 기능을 담당하고 있습니다.
//Event Send (SQS Publish)
eventSender.send(request)문제는 여기서 발생합니다. 위 메소드는 @Transactional로 감싸져 있어, 트랜잭션이 커밋되기 전에 메시지가 발행됩니다. 그렇다면 Consumer는 어떻게 될까요? MongoDB에는 데이터가 아직 저장되지 않았는데, Consumer는 데이터를 조회하려다 Not Found Exception을 만나게 됩니다. 타이밍 하나 잘못 맞춰서 시스템이 흔들리는 셈이죠.
How? 이 상황, 어떻게 해결할 수 있을까요?
1. SQS 메시지 지연 전달 방식은 어떨까?
- 메시지를 지연 전송하는 방법은 간단하고 기존 로직을 거의 수정하지 않아도 됩니다. 그러나, 지연 시간이 너무 짧다면 타이밍 문제가 여전히 발생할 수 있어 임시방편에 불과하다고 생각했습니다.
2. Outbox 패턴이나 로그 테일링 패턴을 활용한 아키텍처 도입?
- 데이터와 메시지를 분리하여 관리하는 좋은 방법이지만, 현재 상황에서는 설계 및 구현에 걸리는 시간과 비용이 부담됩니다. (여유가 있다면 추천하지만, 당장 불 끄는 데는 조금 과한 솔루션이죠.)
Solution 우리의 해결책, 이렇게 정리했습니다!
@Component
class SellerRegistrationEventPublisher(
private val processStepFactory: SellerProcessStepFactory,
) {
@Async
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
fun handleEvent(event: RequestProcessedEvent) {
val sendMessageDto = SendMessageRequest()
.withMessageBody(objectMapper.writeValueAsString(event.request))
amazonSQS.sendMessage(sendMessageDto)
}
}
@Service
class RequestAddServiceImpl(
//나머지 선언 생략
private val applicationEventPublisher: ApplicationEventPublisher,
): RequestAddService {
@Transactional("mongoTransactionManager")
override fun addRequest(requestDto: RequestDto): ResponseDto {
// 윗부분은 위와 동일
// 커밋 후 이벤트 발행
applicationEventPublisher.publishEvent(RequestProcessedEvent(request))
return ResponseDto.create(id = request.id)
}
}위와 같이 Spring의 ApplicationEventPublisher 인터페이스를 사용해 문제를 해결했습니다. 트랜잭션 커밋 후 이벤트가 동작하도록 했는데요. 여기서 궁금증 하나! 왜 ApplicationEventPublisher 를 사용했을까요?
🎯 이유 1: 트랜잭션 커밋 후 발행 보장
- TransactionPhase.AFTER_COMMIT 옵션 덕분에 데이터가 MongoDB에 확실히 저장된 후 이벤트가 발행됩니다.
- Consumer는 더 이상 Not Found Exception으로 고통받지 않아도 됩니다.
🎯 이유 2 : 책임 분리의 미학
- "트랜잭션은 트랜잭션만, 이벤트는 이벤트만!" 작업과 이벤트 발행을 분리하면 코드가 더 깔끔하고, 추후 확장도 쉽습니다.
🎯 이유 3: 비동기로, 더 빠르게!
- @Async로 비동기 처리까지 추가하면, 이벤트 발행 작업이 메인 로직을 방해하지 않고 진행됩니다.
⚠️ 결론 트랜잭션 커밋 후에 이벤트를 발행하면 데이터 정합성도 지키고, 시스템 안정성도 챙길 수 있습니다.이제 Not Found Exception은 안녕~ 올바른 타이밍의 선택이 성공적인 시스템을 만든다는 사실, 잊지 마세요!
😁 마무리
Spring Boot MongoDB 트랜잭션 설정과 Replica Set 도입, 그리고 성능 테스트 과정에서 겪었던 문제를 공유해 봤습니다. 이 경험들이 여러분의 프로젝트에도 도움이 되었길 바랍니다! 🙌 혹시 더 좋은 아이디어나 다른 의견이 있으시다면 언제든 댓글로 알려주세요. 더 나은 방향을 함께 고민해봐요! 😊
📚 참고자료
😝 Thanks to
이 모든 과정을 함께 헤쳐나간 카탈로그서비스개발팀, 진심으로 감사드립니다.
여러분 덕분에 한 걸음 더 성장할 수 있었습니다. 🎉
앞으로도 더 재미있고 유익한 이야기로 찾아뵙겠습니다! 🚀