

안녕하세요. 카탈로그서비스개발팀에서 백엔드 개발을 담당하는 빅토르입니다.
Debezium MSK Connect를 운영하며 안정성을 고민했던 경험과 Connector 중단 시 해결 방법에 대해 공유해보겠습니다.

Debezium MSK Connect 최초 도입기는 같은 팀 빽곰님의 지난 3월 글을 확인해 주세요~
모니터링 및 알람 설정
MSK 시스템의 안정성을 확보하기 위해 모니터링은 필수적입니다. 모니터링은 서비스 가용성, 성능 최적화, 데이터 정합성 보장 등 다양한 측면에서 중요합니다. 예를 들어, Connector에서 이상이 발생할 경우 이를 조기에 감지하여 신속하게 대응해야 합니다.
알람 시스템 구성 및 관리
저희 팀은 이러한 필요성을 인식하고, Connector 이상 발생 시 메시지를 감지하기 위해 Topic Heartbeat 기능을 활용하였습니다. 이 기능은 주기적으로 연결 상태를 확인하고, 문제가 발생할 경우 Slack을 통해 오류 메시지를 발송과 온콜 시스템을 가동합니다. 이를 통해 운영팀은 실시간으로 시스템 상태를 모니터링할 수 있으며 신속하게 문제를 해결할 수 있는 기반을 마련할 수 있습니다.
Connector 설정 시 heartbeat.interval.ms 옵션과 topic.heartbeat.prefix를 사용하여 Heartbeat 메시지를 수신합니다. 저희는 이 메시지를 주기적으로 저장하고 있으며 이전 Heartbeat와의 시간 차이가 발생할 경우 알림을 받도록 설정하여 시스템의 안정성을 모니터링하고 있습니다.

MSK Connector가 정상적으로 작동하지 않는다면 어떻게 해야 할까요?

Offset을 사용해 복구할 수 있지만, 이마저도 불가능한 상황에서는 Connector를 새로 생성해야 합니다. 저희 팀이 고민한 해결 방법을 공유해 드리겠습니다.
저희는 기존 테이블 구조와 다른 신규 시스템 테이블로 데이터를 전송해야 해서, Sink Connector 대신 데이터 변환과 매핑을 직접 수행하고 있습니다. 이를 위해 별도의 컨슈머 워커(Consumer Worker)를 구성하여 MSK에서 수신한 메시지를 변환한 뒤 신규 시스템에 저장합니다. 새로운 Connector 생성 시에는 서비스 로직에서 기존 토픽의 데이터를 원하는 기간만큼 재발행하여 데이터 보정을 합니다.
또한 비동기 메시지 처리에서는 AOP를 적용해 메시지 수정 시간을 비교하고, 최신 메시지일 경우에만 처리가 되도록 설정했습니다.
전체적인 흐름은 아래와 같습니다.

이전 Offset으로의 복구
MSK Connector나 Kafka와 같은 메시지 스트리밍 시스템에서 장애가 발생하거나 데이터 불일치 문제가 생길 때, 데이터 일관성과 연속성을 확보하기 위한 중요한 기술적 전략입니다. 이를 활용하면 시스템의 장애나 오류 발생 시 특정 시점으로 되돌아가 메시지를 재처리하여 데이터 정합성을 유지할 수 있습니다.
-
효율적인 장애 복구와 데이터 불일치 해결
- 시스템 장애나 오류 발생 시, 특정 Offset부터 데이터를 재처리함으로써 전체 데이터를 처음부터 처리하지 않아도 되어 복구 시간이 단축됩니다. 이를 통해 운영 비용 절감과 빠른 복구가 가능하며, 데이터 불일치 문제도 해결할 수 있습니다.
-
연속적 데이터 처리와 안정성 보장
- Offset을 사용해 특정 시점부터 데이터를 재처리하면, 시스템이 데이터를 놓치지 않고 연속적으로 처리할 수 있어 데이터 흐름의 일관성을 유지할 수 있습니다. 이는 특히 데이터 연속성이 중요한 서비스에서 안정적인 운영을 보장합니다.
신규 Connector 생성
현재 사용중인 Offset을 확인합니다. 아래는 akhq를 사용한 토픽 확인 방법입니다.

운영중인 토픽을 확인하고, 신규 Connector를 해당 Offset 정보로 생성합니다.
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter=org.apache.kafka.connect.json.JsonConverter
# Connector Offset 설정
offset.storage.topic=__amazon_msk_connect_offsets_test-connector
# 30MB 최대 요청 크기
producer.max.request.size=31457280
#클러스터에서 설정 정보를 저장하는 토픽의 복제 계수
config.storage.replication.factor=3
#상태 정보를 저장하는 토픽의 파티션 수
status.storage.partitions=3
#상태 정보를 저장하는 토픽의 복제 계수
status.storage.replication.factor=3
#Offset 정보를 저장하는 토픽의 파티션 수
offset.storage.partitions=3
#Offset 정보를 저장하는 토픽의 복제 계수
offset.storage.replication.factor=3이와 같이 설정하면 Connector의 장애 발생 후에도 정상적으로 재가동될 수 있으며, 이전 오프셋 정보를 바탕으로 데이터의 연속성을 보장할 수 있습니다. 이러한 절차는 시스템의 안정성을 높이는 데 중요한 역할을 하며, 데이터 처리의 신뢰성을 강화합니다.
Failover 발생 시나리오
Failover의 정의 및 필요성
Failover는 시스템의 주요 구성 요소가 장애를 일으킬 경우, 이를 자동으로 대체하여 서비스 연속성을 유지하는 기술입니다. 이 프로세스는 고가용성을 목표로 하며, 서비스 중단 시간을 최소화하고 시스템 안정성을 높이는 데 필수적입니다. 장애가 발생해도 사용자가 서비스 중단을 느끼지 못하도록 서비스가 지속적으로 운영되어야 합니다.
- 서비스 중단 최소화: 장애가 발생해도 빠르게 전환하여 서비스가 지속되도록 보장합니다.
- 데이터 손실 방지: 주요 데이터가 손실되지 않도록 보호해 데이터 무결성을 유지합니다.
- 고객 신뢰성 유지: 지속적인 가용성은 사용자 신뢰를 강화하고, 시스템의 신뢰도를 높입니다.
Failover 발생 시 조치 사항
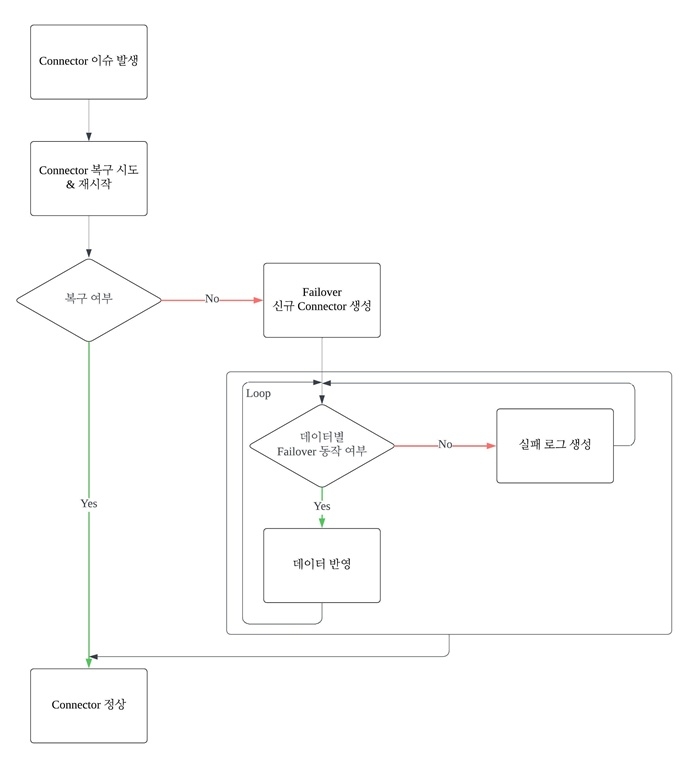

이러한 절차를 통해 데이터 정합성을 유지하고, 각 단계의 검토 및 처리를 통해 데이터 신뢰성을 강화하고 있습니다.
Failover 상황에서 발생한 데이터 오류 처리
메시지를 소비할 때 순차적으로 처리하는 경우 메시지의 순서 보장이 되지 않아 문제가 발생할 수 있습니다. MSK는 기본적으로 메시지 순서를 보장하지 않기 때문에 의도치 않은 순서로 메시지가 처리될 수 있습니다.
잘못된 데이터 처리 및 복구 절차

a. Custom plugin
Amazon MSK 신규 Connector를 생성하게 되면, 사용할 plugin을 설정합니다.

b. Connector properties
Connector를 생성할 때, Failover 대상 데이터를 처리하기 위해 snapshot.select.statement.overrides 옵션을 설정합니다. 이 옵션을 통해 특정 테이블의 스냅샷 쿼리를 커스터마이징할 수 있어, Failover 시 필요한 데이터만 선택적으로 가져오는 데 유용합니다.
#테이블의 스냅샷(초기 데이터 로딩) 시에 사용할 커스텀 SQL 쿼리를 정의
snapshot.select.statement.overrides.customers=SELECT * FROM customers where change_dt >= '2024-10-10'
#테이블의 스냅샷을 할 때 커스텀 쿼리를 사용하도록 지정
snapshot.select.statement.overrides=customers
#테이블만 변경사항을 추적
table.include.list=customers
#Debezium이 테이블에서 감지한 이벤트를 기본 토픽 대신 failover-topic이라는 새로운 토픽으로 재배치합니다.
transforms.Reroute.topic.replacement=failover-topicc. Worker configuration
기본 설정으로 아래와 같이 생성합니다.
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 30MB 최대 요청 크기
producer.max.request.size=31457280
#클러스터에서 설정 정보를 저장하는 토픽의 복제 계수
config.storage.replication.factor=3
#상태 정보를 저장하는 토픽의 파티션 수
status.storage.partitions=3
#상태 정보를 저장하는 토픽의 복제 계수
status.storage.replication.factor=3
#Offset 정보를 저장하는 토픽의 파티션 수
offset.storage.partitions=3
#Offset 정보를 저장하는 토픽의 복제 계수
offset.storage.replication.factor=3d. Review and create
해당 테이블의 데이터를 CDC로 처리하는 Connector를 생성합니다. 이때 스냅샷 상태인 r 상태로 데이터가 구성되며, 지정된 토픽으로 전송됩니다.


주의점
Connector 생성 시 주의해야 할 두 가지 옵션이 있습니다. snapshot.locking.mode = none, snapshot.mode = schema_only 로 설정하고 있습니다. 이 옵션에 따라 수행되는 기능이 달라지므로 각 옵션의 의미를 이해하는 것이 중요합니다.

위 절차대로 Connector 를 생성하면, 스냅샷이 생성되면서 op="r" 타입의 데이터가 발행됩니다. 이 부분을 제어하려고 합니다.

Debezium Documentation Connectors MySQL - update events
{
"schema": { ... },
"payload": {
"before": null,
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "2.5.4.Final",
"name": "mysql-server-1",
"connector": "mysql",
"name": "mysql-server-1",
"ts_ms": 1465581029100,
"snapshot": false,
"db": "inventory",
"table": "customers",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"thread": 7
},
"op": "r",
"ts_ms": 1465581029523
}
}저희 팀은 기존 상태와 겹치지 않는, f = Failover 라는 상태를 정의했으며 이를 통해 서비스 내부 Failover 가 동작하게됩니다.
Failover 토픽으로 op = "r" 상태의 데이터가 유입되면, 이를 소비하여 op = "f" 상태로 강제로 변환합니다. r 상태는 스냅샷 상태로, ChangedFields 항목이 존재하지 않아 변경된 필드가 없습니다. 그러나 저희 팀은 변경된 필드를 기반으로 로직을 처리하기 때문에, after의 key 값을 모두 가져와 ChangedFields 항목을 생성합니다. 그 후, 데이터를 기존 테이블과 연관된 토픽으로 전달할 수 있도록, targetTopic 정보를 가져와 테이블 정보와 결합하여 다시 전송합니다.
- ex) offline-oracle-dev-connector.customers
companion object {
const val AFTER = "after"
const val FAILOVER = "failover"
const val DB = "db"
const val TABLE = "table"
const val CHANGED_FIELDS = "ChangedFields"
const val OPERATOR = "op"
const val FAILOVER_RECOVERY_OP = "f"
const val DOT = "."
val unavailableValues = listOf("unavailable_value")
val excludedKeys = listOf("TEMP_KEY")
}
@KafkaListener
fun failoverMessages(records: MutableList<ConsumerRecord<String, String>>, ack: Acknowledgment) = try {
records.forEach { record ->
record.value()?.let { value ->
kafkaSender.sendMessage(
listOf(
connectorConfig[FAILOVER],
jacksonObjectMapper().readValue<Map<String, Any>>(value).let { cdcMessage ->
addChangedFieldsToData(cdcMessage.toMutableMap()).apply {
this[OPERATOR] = FAILOVER_RECOVERY_OP
}
}[DB].toString(),
jacksonObjectMapper().readValue<Map<String, Any>>(value)[TABLE].toString()
).joinToString(DOT),
record.key(),
addChangedFieldsToData(jacksonObjectMapper().readValue(value))
)
}
}
ack.acknowledge()
} catch (e: Exception) {
// handle exception
}
// addChangedFieldsToData 는 after 기준으로 전체 변경 항목으로 추가합니다.
private fun addChangedFieldsToData(data: MutableMap<String, Any>) = data.apply {
val after = this[AFTER] as? Map<*, *> ?: return this
val filteredKeys = after.filterKeys { it !in excludedKeys }
.filterValues {it.toString() !in unavailableValues }
.keys
this[CHANGED_FIELDS] = filteredKeys
}
{
"before": null,
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "2.5.4.Final",
"name": "mysql-server-1",
"connector": "mysql",
"name": "mysql-server-1",
"ts_ms": 1465581029100,
"snapshot": false,
"db": "inventory",
"table": "customers",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"thread": 7,
"ChangedFields": [
"id",
"first_name",
"last_name",
"email"
]
},
"op": "f",
"ts_ms": 1465581029523
}
- 위와 같이 op = "f" 상태로 ChangedFields 항목이 추가됩니다.
- 스냅샷 데이터이므로 최신 데이터로 간주하여 전체 항목을 변경할 예정입니다.
- source . table = 동작한 테이블명이 나타납니다.
Failover 로직 AOP 공통화
발행된 메시지를 소비하여 API를 호출할 때, Failover 이벤트와 충돌하지 않고 정상적으로 동작해야 합니다. 기존 서비스 로직과는 별개로 작동해야 하므로, 공통화를 위해 AOP를 활용하여 개발했습니다.
Failover 어노테이션을 정의하고, 해당 서비스가 실행될 때 Failover 대상인지 여부를 체크하여 적절히 동작하도록 설정하였습니다.
import org.aspectj.lang.ProceedingJoinPoint
import org.aspectj.lang.annotation.Around
import org.aspectj.lang.annotation.Aspect
import org.aspectj.lang.reflect.MethodSignature
import org.springframework.context.ApplicationContext
import org.springframework.stereotype.Component
import java.time.LocalDateTime
import kotlin.reflect.full.memberProperties
@Aspect
@Component
class FailoverCallAspect(
val applicationContext: ApplicationContext,
val failOverService: FailOverServiceImpl
) {
private val logger by LoggerDelegator()
companion object {
const val FAILOVER = "failover"
const val REQUEST_DATE = "changedTime"
const val OFFSET = "offset"
const val Y = "Y"
const val N = "N"
const val C = "C"
const val U = "U"
const val FAIL = "F"
}
data class ExecutionContext(
val annotation: Failover,
val actionName: String,
val parameters: Array<Any>
)
// @Around("@annotation(Failover)")` Failover 어노테이션이 설정된 서비스 메서드가 실행될 때 호출됩니다.
@Around("@annotation(Failover)")
fun controlMethodExecution(joinPoint: ProceedingJoinPoint) = try {
prepareExecutionContext(joinPoint).let { context ->
// `if (!failoverValue)` 를 통해 해당 메서드가 Failover로 호출되었는지 확인합니다. 이 값이 false일 경우, Failover 동작은 무시됩니다.
if (extractPropertyFromParams<Boolean>(context.parameters, FAILOVER) == false)
return joinPoint.proceed()
// `findBeanByName` 메소드는 사용하려는 레파지토리를 검색합니다.
findBeanByName(context.annotation.serviceName).let { service ->
service::class.java.getMethod(context.annotation.methodName, String::class.java).let { targetMethod ->
context.annotation.searchKey.mapNotNull { key ->
extractPropertyFromParams(context.parameters, key)
}.toTypedArray().let { searchArray ->
// `method.invoke(service, *searchArray)` 를 사용하여 리플렉션을 통해 해당 메서드를 호출합니다.
targetMethod.invoke(service, *searchArray).let { result ->
extractPropertyFromParams<LocalDateTime>(
arrayOf(result),
context.annotation.dateTime
).let { dbModifiedDate ->
extractPropertyFromParams<LocalDateTime>(context.parameters, REQUEST_DATE).let { modifiedDateValue ->
determineOperator(
dbModifiedDate,
modifiedDateValue,
context.annotation.operator
).let { (operator, applyYn, isSuccess) ->
// `saveFailOver` 메서드를 호출하여 Failover 정보를 저장합니다.
failOverService.saveFailOver(
extractPropertyFromParams(context.parameters, OFFSET),
operator,
context.actionName,
context.parameters,
applyYn,
modifiedDateValue
)
if (isSuccess) joinPoint.proceed() else null
}
}
}
}
}
}
}
}
} catch (e: Exception) {
// handle exception
}
private fun prepareExecutionContext(joinPoint: ProceedingJoinPoint) = ExecutionContext(
annotation = (joinPoint.signature as MethodSignature)
.method
.getAnnotation(Failover::class.java),
actionName = "${joinPoint.target::class.java.simpleName}.${(joinPoint.signature as MethodSignature).name}",
parameters = joinPoint.args
)
private inline fun <reified T> extractPropertyFromParams(params: Array<Any>, propertyName: String): T? =
params.asSequence()
.mapNotNull { param ->
param::class.memberProperties
.firstOrNull { it.name == propertyName }
?.getter
?.call(param) as? T
}
.firstOrNull()
private fun findBeanByName(beanName: String) = try {
applicationContext.getBean(beanName)
} catch (e: Exception) {
// handle exception
}
/*
f) 마지막으로, `determineOperator` 는 실제 서비스에서 동작 가능한 상태를 확인합니다.
- operator : 동작타입
- applyYn : 적용여부
- isSuccess : 성공/실패
*/
private fun determineOperator(
dbModifiedDate: LocalDateTime?,
modifiedDateValue: LocalDateTime?,
operator: Array<String>
): Triple<String, String, Boolean> = when {
dbModifiedDate == null && C in operator -> Triple(C, Y, true)
dbModifiedDate != null && modifiedDateValue?.isAfter(dbModifiedDate) == true && U in operator -> Triple(U, Y, true)
else -> Triple(U, N, false)
}
}아래는 AOP Failover 예제입니다.
@Target(AnnotationTarget.FUNCTION)
@Retention(AnnotationRetention.RUNTIME)
annotation class Failover(
val serviceName: String,
val methodName: String,
val dateTime: String,
val searchKey: Array<String>,
val operator: Array<String>,
val group: String = ""
)
// 서비스에는 `@Failover` 어노테이션 적용으로 동작하게됩니다.
@Failover(serviceName = "simpleRepository", methodName = "findOneByNo", dateTime = "changedTime", searchKey = ["no"], operator = ["U"])
@Transactional
override fun updateStatus(request: RequestDto): String? {
return simpleRepository.findOneByNo(request.no)?.let { data ->
data.status = request.status
return@let data.no
}
}
마무리
지금까지 Debezium MSK Connect 를 정상화하기 위한 다양한 방법을 소개해 드렸습니다.
Trouble shooting 을 진행하면서 Oracle Debezium의 레퍼런스가 부족하다는 사실에 좌절도 하고 많은 어려움이 있었지만, 점차 시스템이 안정화되는 모습을 보며 뿌듯함을 느끼고 있습니다.
아직 저희의 Debezium MSK Connect 활용기는 절찬리에 진행 중이니 많은 관심 부탁드립니다!
긴 글을 읽어 주셔서 감사합니다~

References
https://docs.spring.io/spring-framework/reference/core/aop/ataspectj/advice.html
