
안녕하세요~ 올리브영에서 백엔드 개발을 담당하고 있는 인벤토리 스쿼드 올여우입니다.
오늘은 인벤토리 스쿼드에서 진행 중인 신규 재고 시스템 구축과 그 개발 여정을 소개하겠습니다.
현재 올리브영의 시스템은 하루가 다르게 발전하고 있습니다.
기존 레거시 시스템들의 문제들을 파악해서 신규 아키텍처로 전환하는 작업들이 지속적으로 진행 중입니다.
신규 재고 시스템 구축 역시 개선 작업의 일환으로 시작했습니다.
프로젝트 시작
현재 올리브영의 주요 데이터는 Oracle DB에 저장되고 있습니다.
하지만 수많은 시스템의 커넥션이 발생하면서 Oracle DB의 부하는 종종 문제가 되곤 합니다.
그래서 Oracle에 집중된 DB 트래픽 분산과 MSA 전환을 목적으로 신규 재고 프로젝트가 시작됩니다.
더 나아가 복잡한 레거시의 프로세스를 개선하고 안정적인 재고 시스템 구축으로 유연한 비즈니스 확장을 목표로 합니다.
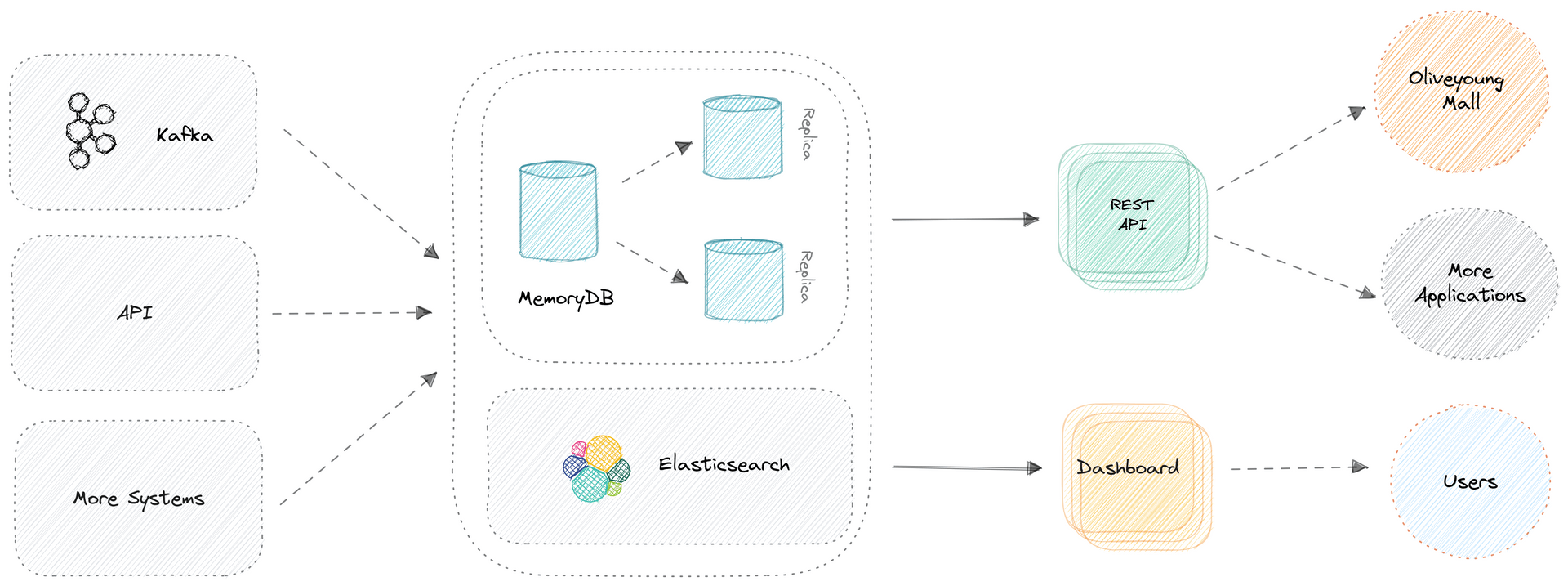
프로젝트 목표
'개편의 시작은 철저한 레거시 분석부터'라는 말이 있습니다.
프로젝트 방향을 정하기 위해 레거시 재고 프로세스 분석을 먼저 진행했습니다.
재고는 매장을 비롯해서 온라인몰, 물류 등 다양한 영역의 데이터를 가지고 있습니다.
저희는 먼저 1차 구축 목표를 오프라인 매장 재고로 정했습니다.
올리브영의 오늘드림 서비스가 매장 재고를 기반으로 하기 때문입니다.
오늘드림은 온라인몰에서 고객이 상품을 구매하면, 오프라인 매장에서 배달대행을 통해 빠르게 배송해 주는 올리브영의 대표적인 O2O 서비스입니다.
아직 오늘드림을 사용해 보지 않으셨다면, 꼭 빠른 배송의 새로운 세계를 경험해 보시기 바랍니다.
오늘드림 서비스를 위해서는 온라인몰에서 오프라인 매장 재고 조회가 필수입니다.
하지만 대규모 트래픽이 발생하는 온라인몰에서 매장 재고를 실시간으로 조회하면서 트래픽 이슈가 빈번히 발생했습니다.
특히 트래픽이 높은 일부 서비스에서는 Cache, Batch 등 보조 수단으로 성능 이슈를 해소해 왔습니다.
저희의 목표는 분명합니다.

신규 시스템을 구축하면 수 많은 기술 고민에 맞닥뜨리게 됩니다.
그리고 당면한 문제를 효율적으로 해결하기 위해서는 심도 깊은 노력과 선택이 필요합니다.
아래는 프로젝트를 진행하면서 고민했던 몇 가지 기술입니다.
동시성 제어와 Distributed Lock
매장 재고는 전국의 매장 POS, 물류 시스템, 관리자 등 여러 클라이언트에서 동시에 호출이 발생합니다.
따라서 데이터 동시성 제어는 필수입니다.
먼저 Redis 라이브러리는 Redisson을 선택했습니다.
아래 기능 외에도 다양한 장점을 가지고 있습니다.
- Java의 표준 컬렉션 인터페이스 구현으로 간단하게 데이터 연동 가능
- 분산 락과 동기화 지원으로 분산 환경에서 자원 접근 조정 (데이터 일관성과 동시성 관리)
- 분산 캐시 지원을 통한 빠른 데이터 액세스 및 성능 향상
- Pub/Sub 메커니즘을 활용해서 이벤트 기반 메시징 시스템 지원
- Redis Cluster 및 Sentinel 등 고가용성 기능 지원
- 비동기 및 반응형 프로그래밍 모델을 지원해서 고성능 애플리케이션 구축 가능
동시성 제어를 위해 Redisson의 분산 락 인터페이스인 RLock을 활용했습니다.
Pub/Sub 기반의 분산 락 메커니즘을 제공합니다.
아래는 분산 락 구현을 위한 간단한 Kotlin 예제입니다.
RedissonClient 객체는 Factory Pattern으로 정의했고, AOP로 분산 락을 적용했습니다.
그리고 Redisson Transaction을 반영했습니다.
@Configuration
@EnableTransactionManagement
class RedisDataSourceProvider {
@Bean
@Qualifier(value = "redissonFactory")
fun createRedissonFactory(): RedissonClient {
val config = Config().apply {
codec = StringCodec()
useClusterServers()
.setScanInterval(SCAN_INTERVAL)
.addNodeAddress(REDIS_HOST)
}
return Redisson.create(config)
}
@Bean
fun redissonTransactionManager(
@Autowired
@Qualifier(value = "redissonFactory")
redisson: RedissonClient
): RedissonTransactionManager {
return RedissonTransactionManager(redisson)
}
}@Component
class RedissonTransactionAspect {
@Transactional("redissonTransactionManager")
fun proceed(proceedingJoinPoint: ProceedingJoinPoint): Any {
return proceedingJoinPoint.proceed()
}
}
Redisson에는 락을 획득하는 다양한 메서드들이 있습니다.
크게 lock 메서드와 tryLock 메서드로 구분됩니다.
lock 메서드는 락을 얻을 때까지 대기하며, tryLock 메서드는 락 획득에 실패하면 추가 작업을 진행합니다.
프로젝트에서는 락 상태를 바로 알 수 있는 tryLock으로 데이터 일관성과 성능 향상을 도모했습니다.
그리고 락 임대 시간과 대기 시간을 조정할 수 있습니다.
데이터 및 시스템 환경에 따라 최적의 시간을 설정하면 됩니다.
- leaseTime : 자원 임대 시간
- waitTime : 자원 임대를 위한 대기 시간
- unit : enum TimeUnit
@Aspect
@Component
class LockableAspect {
@Around(value = "@annotation(lockable)")
fun executeWithLock(proceedingJoinPoint: ProceedingJoinPoint, lockable: Lockable): Any? {
val lock = memoryDBConnectionFactory.getLock(LOCK_KEY)
return try {
if (lock.tryLock(CLUSTER_WAIT_TIME, CLUSTER_LEASE_TIME, TimeUnit.MILLISECONDS)) {
redissonTransactionAspect.proceed(proceedingJoinPoint) // 락을 보유한 상태에서 작업 수행
} else {
// 락 획득 실패에 따른 추가 작업
}
} catch (e : Exception) {
// 예외 처리
} finally {
lock.unlock() // 락 해제
}
}
}
추가로 락을 해제할 때 forceUnlock 메서드가 있습니다.
강제로 락을 해제해야 하는 경우에 사용하며, 동시성 문제 가능성이 있어서 사용에 주의가 필요합니다.

레거시 시스템에 Kafka Message Queue 연동
매장 재고는 고객의 주문/취소로 인한 재고 이벤트 비중이 가장 높습니다.
기존에는 POS 주문 건마다 중계 서버를 거쳐 Transaction 데이터를 Oracle DB에 등록해서 재고를 업데이트했습니다.
하지만 Transaction 데이터는 재고뿐 아니라 상품, 쿠폰, 회원, 매출 등 전체 정보를 가지고 있습니다.
저희는 빠르고 안정적인 재고 적재를 위해 POS에서 발생하는 재고 이벤트만 연동이 필요했습니다.
그래서 선택한 방식이 바로 Kafka Message Streaming입니다.
신규 아키텍처는 AWS 기반으로 MSK(Amazon Managed Streaming for Apache Kafka)를 구축했습니다.
이제 POS에서 발생하는 재고 이벤트는 Oracle DB를 거치지 않고, 바로 신규 재고 시스템으로 적재가 가능합니다.

Broker(MSK)와 Consumer(Spring, Kotlin)는 AWS에서 신규 구축되기 때문에 문제가 없었습니다.
하지만, Producer(중계서버)의 경우 한정된 레거시 시스템의 리소스에 추가해야 한다는 부담이 있었습니다.
따라서 최소한의 I/O와 네트워크 리소스를 사용하며, 안정적인 데이터 전송이 보장된 Producer 개발이 필요했습니다.
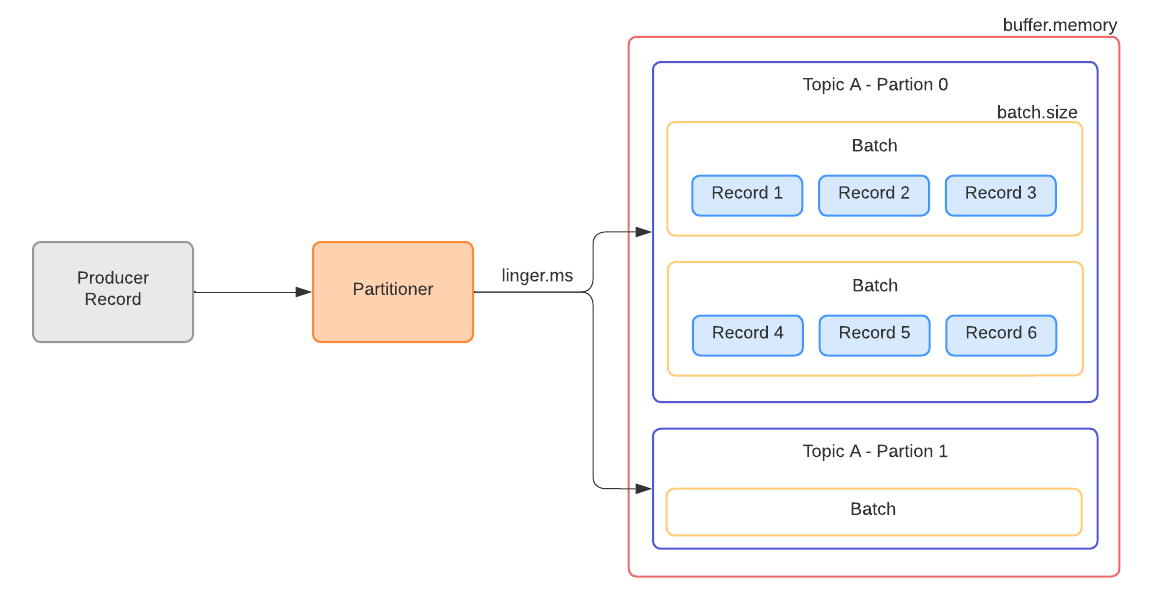
그래서 비동기 호출 기반의 Batch 전송 방식으로 구현을 했습니다.
필수 옵션은 다음과 같습니다. 시스템과 데이터에 맞는 설정을 하려면 다양한 테스트가 필요합니다.
처리량을 높이려면 batch.size와 linger.ms 값을 크게 설정하고, 지연 없는 전송이 필요하면 작게 설정합니다.
- buffer.memory : Producer 버퍼 메모리 옵션
- batch.size : Record들을 묶어서 Batch 전송을 하는 크기 옵션
- linger.ms : 버퍼 메모리에 대기하는 Message들의 최대 대기 시간
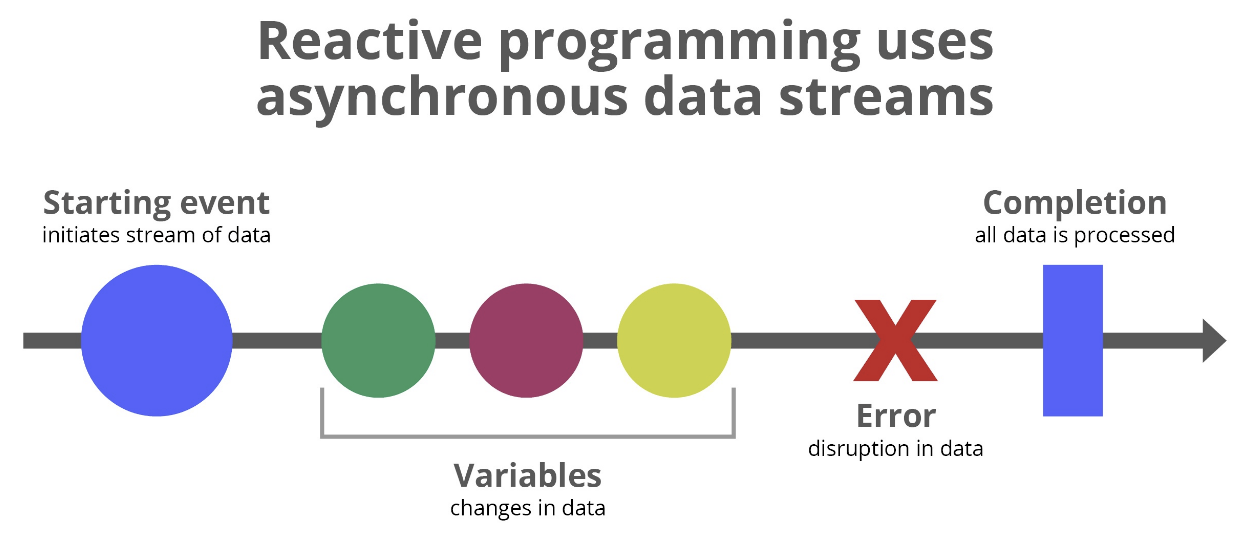
Reactive Programing
매장 재고는 매장 코드와 상품 코드로 간단하게 조회가 가능합니다.
하지만 한 번에 매장의 수많은 상품의 재고를 가져가는 API도 필요했습니다.
따라서 데이터 성능 개선을 고민했고, Reactive Programing을 고려했습니다.
반응형 프로그래밍은 비동기 데이터 스트림을 다루는 패러다임입니다.
데이터 스트림의 변화에 반응하여 연속적으로 데이터를 처리하고, 데이터 흐름을 선언적으로 정의하는 함수형 프로그래밍 기법입니다.
Redisson에서는 Reactive 전용 클라이언트를 제공합니다.
기존 클라이언트와 별도로 정의하고 간편하게 사용할 수 있습니다.
@Bean
@Qualifier(value = "redissonReactiveFactory")
fun createRedissonReactiveFactory(): RedissonReactiveClient {
val config = Config().apply {
codec = StringCodec()
useClusterServers()
.setScanInterval(SCAN_INTERVAL)
.addNodeAddress(REDIS_HOST)
}
return Redisson.create(config).reactive()
}fun getMapFromRedisReactive(key: Key, properties: Set<String>?): Mono<Map<String, Any>> {
return redissonReactive
.getMap<String, Any>(key.getKey())
.getAll(properties ?: Stock.findProperties)
}fun findByKeysAsync(keys: List<Key>, properties: Set<String>?, timeOut: Long?): List<Stock> {
return try {
Flux.fromIterable(keys)
.flatMap { key ->
getMapFromRedisReactive(key, properties)
.doOnNext {
if (it.isEmpty()) {
// Miss key
}
}
.filter { it.isNotEmpty() }
.map { Stock.domainFromMap(key, it) }
}
.collectList()
.block(Duration.ofMillis(timeOut?:MAX_WAIT_TIME))
?: throw StockManageIgnorableException(
// Not found any keys
)
} catch (e: Exception) {
// Exception
}
}
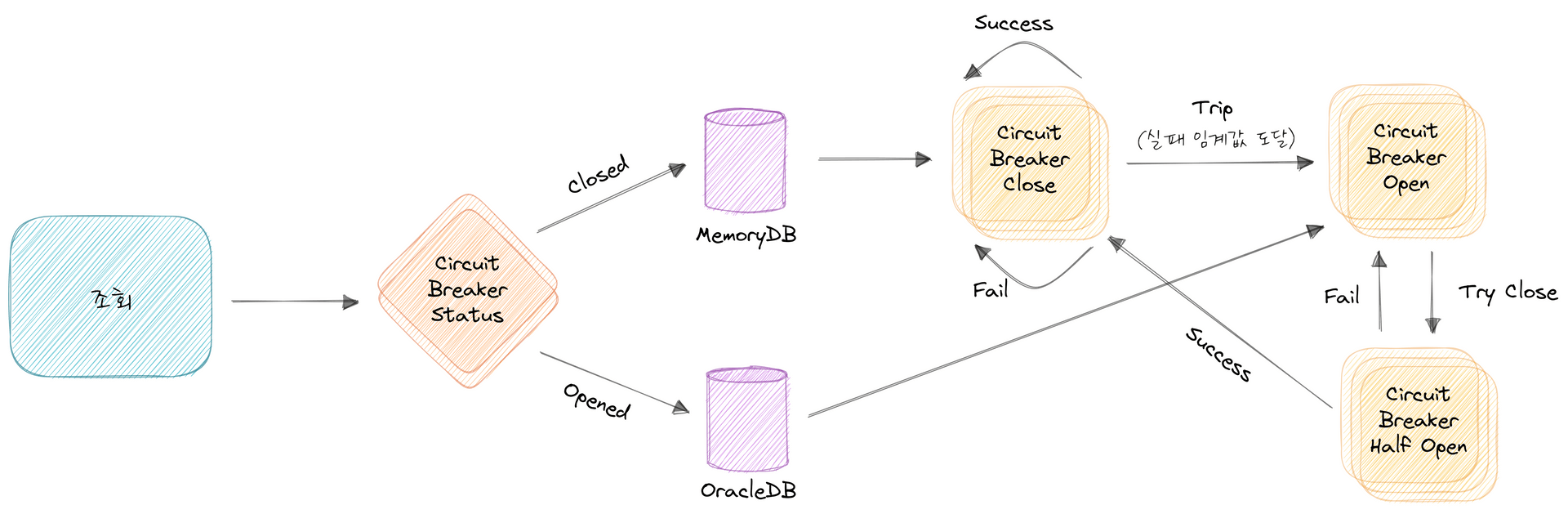
CircuitBreaker
신규로 재고 DB를 구축했기 때문에 안정성 확보는 필수입니다.
Amazon MemoryDB는 클러스터 구조로 안정성이 보장된 시스템이지만, 장애 상황에 대한 준비는 필요했습니다.
그래서 MemoryDB에 일정 기준 오류가 발생할 경우, 기존 DB로 전환하는 CircuitBreaker를 구현했습니다.
MemoryDB가 정상화되면 자동으로 CircuitBreaker는 닫히게 됩니다.
Resilience4j 라이브러리를 활용했습니다.
참고로 CircuitBreaker는 인벤토리 스쿼드의 지난 테크 블로그 포스팅에 자세히 설명되어 있습니다.
궁금하시면 클릭! 클릭!
https://oliveyoung.tech/2023-08-31/circuitbreaker-inventory-squad/
Monitoring
올리브영의 시스템은 DataDog으로 모니터링을 진행하고 있습니다.
그리고 지표에 이상이 있을 경우, 바로 슬랙으로 알림이 오게 됩니다.
신규 재고 시스템 역시 주요 지표를 실시간으로 모니터링하고 있습니다.
재고 데이터 연동 및 처리, 시스템 성능, API 호출 및 응답, Message Queue, CircuitBreaker, 오류 수집 외
몇 가지 흥미로운 모니터링 지표를 잠시 소개하겠습니다.
전국 매장 POS의 주문/취소에 따른 재고 이벤트는 Kafka Message Streaming으로 연동됩니다.
아래는 평일 어느 하루의 전국 매장 재고 데이터 처리 현황입니다.
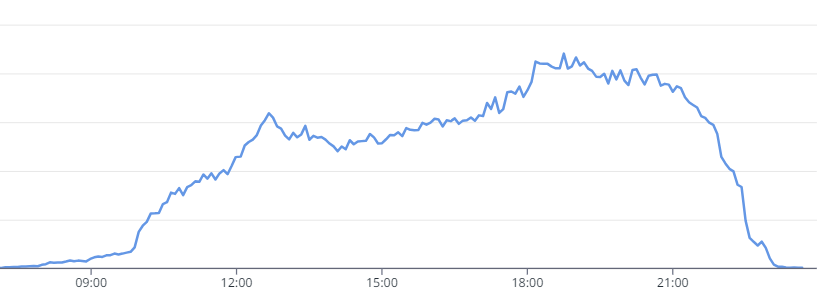
점심시간(12시 이후)과 퇴근 시간(18시 이후)에 급격하게 매장 방문이 늘어납니다.
한적한 쇼핑을 원하신다면 그래프를 자세히 보시기 바랍니다. ㅎㅎ
물론 올영 세일 기간이나 주말, 비 오는 날 등은 조금 다를 수 있습니다.
이상 꿀팁 아닌 꿀팁(?)이었습니다.
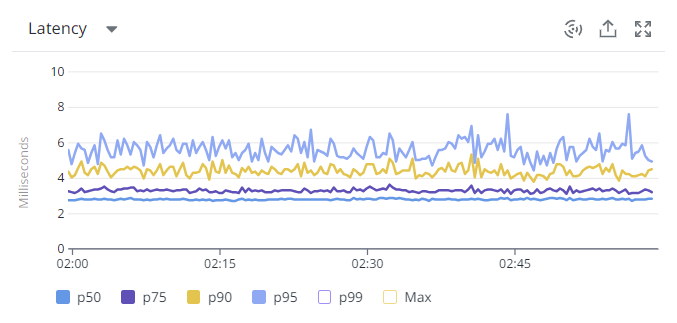
다음으로 API 성능 지표를 살짝 자랑(?) 해보겠습니다.
아래는 온라인몰에서 사용 중인 Inventory API의 평균 Latency 지표입니다.
마치며..
지금까지 신규 재고 프로젝트의 시작부터 구축까지 개발 여정을 알아봤습니다.
현재 인벤토리 스쿼드는 구축된 Inventory API를 다양한 시스템에 적용하고 있습니다.
그리고 재고 데이터를 기반으로 ELK를 활용해서 Dashboard를 개발하고 있습니다.
이번에는 프로젝트 전반적인 이야기를 해봤습니다.
다음에는 조금 더 깊이 있는 기술 이야기를 준비해 보겠습니다.
그럼 다음에 또 좋은 주제로 찾아오겠습니다~ ㅎㅎ
긴 글 읽어 주셔서 감사합니다!
